Build vs Buy Revenue AI in 2026: Cost Math, Architecture Traps, and Decision Framework
Written by
Ishan Chhabra
Last Updated :
June 22, 2026
Skim in :
7
mins
In this article
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions
TL;DR
Building revenue AI in 2026 mirrors the year-2000 cycle, when teams built in-house CRMs and ERPs that the application layer later made obsolete.
Below roughly $20K of expected annual value, building is genuinely cheaper; above $50K, buying compounds faster once maintenance, hosting, and tokens are counted.
RAG handles shallow summaries but collapses on deal synthesis at scale, where complex queries can cost $5K to $15K weekly in tokens for a 50-rep team.
Production agents need guardrails, permissions, monitoring, and audit trails, plus a rare GTM engineer costing $250K to $400K and 6 to 12 months to hire.
Use five honest questions, annual value, talent, synthesis versus retrieval, audit needs, and core competency, to make and defend your own decision.
If your answers lean buy, a single-use-case pilot starting at $19 per user is the cheapest next experiment.
Q1. Is building your own revenue AI in 2026 the same bet companies made in the year 2000? [toc=1. The Year 2000 Cycle]
In 2000, Oracle databases existed but Salesforce, Workday, and NetSuite did not. So companies built their own CRMs, ERPs, and HR systems in-house. Most were quietly retired within five years once the application layer matured. AI today is the database in 2000: foundational technology with no mature application layer yet. Building right now is rational. The real question is not whether to build, it is whether what you build still makes sense in 2028.
💾 A scene every RevOps leader knows
Picture a Head of RevOps with two browser tabs open. One is a Gong renewal quote. The other is Claude, mid-conversation, summarizing a sales call beautifully. The math in their head is simple. "If it can do that, why are we paying six figures a year?"
I have watched this exact moment play out across a dozen mid-market revenue teams. It is a fair question. The instinct to build is not naive, it is the correct read of where the technology sits today.
⏰ The pattern repeats every technology cycle
Here is what I keep coming back to. In 1999, Salesforce was a brand new idea and NetSuite was barely founded. If you wanted a CRM or an ERP, you built it. Smart teams did, and their builds worked for a while.
The same timing pattern that turned year-2000 in-house builds into liabilities is repeating with AI today.
Then the application layer arrived. By the mid-2000s, most of those in-house systems were liabilities nobody wanted to maintain. The lesson was not "building was dumb." The lesson was about timing.
When foundational technology shows up before the applications are built on top of it, in-house builds explode. Then the application layer matures, and those same builds become the thing you migrate off of. This is the same arc we trace in our breakdown of how revenue ops evolved into orchestration.
🤔 Where you actually are in the cycle
AI in 2026 is the database in 2000. The foundation models are powerful and cheap to call. The application layer for revenue teams is still young, still unproven to a lot of buyers, and still earning trust, as our roundup of the best revenue intelligence software platforms shows.
So of course people are building. I would be suspicious of any vendor who told you not to. The honest framing is this: building today can be completely rational, and it can still age into a 2023-shaped liability by 2028.
The rest of this piece is not a pitch to stop. It is a way to pressure-test your own build, so the thing you ship survives the next two years instead of quietly getting retired like those year-2000 ERPs.
Q2. What does building revenue AI really cost, and where does building actually win? [toc=2. The Real Math]
Below roughly $20K of expected annual value, building is genuinely cheaper. Say that out loud. Above it, buying compounds faster. A realistic build runs 1 to 2 engineers for 3 to 9 months ($80K to $200K loaded), plus 20% to 30% of that yearly in maintenance, plus production-scale token costs and $10K to $30K in hosting and observability. Buying a mid-market platform typically runs $20K to $50K a year. The cost most buyers forget is opportunity cost: engineer time on this is time not spent on the product you actually sell.
💰 The numbers most comparisons hide
Most build-versus-buy posts cherry-pick the figures, and you know it, so you discount everything they say. I am going to do the opposite and concede where building wins first.
A serious internal build is not "just an API call." Here is the realistic line-up, not the lowballed one.
Build vs Buy: Annual Cost Breakdown
Line item
Build (in-house)
Buy (mid-market platform)
Initial engineering
$80K to $200K loaded (1 to 2 engineers, 3 to 9 months)
$0
Ongoing maintenance
20% to 30% of build cost, every year
Included
Hosting, monitoring, observability
$10K to $30K per year
Included
Production-scale LLM tokens
Grows with usage, often non-linearly
Included in seat price
Typical annual total
Frequently $150K+ in year one
~$20K to $50K per year
💸 The honest threshold
There is a real line. Below about $20K of expected annual value, building is the rational call. The overhead of buying does not pay back at that size.
Above $20K, buying starts to compound in your favor, and past $50K it is rarely close. I have rebuilt internal pipeline tooling myself, and this threshold held up almost every time. If you are weighing platforms at that level, our guide to the best AI sales tools is a useful starting point.
⚠️ The costs that do not show up in the spreadsheet
Three costs get left out, and they are the expensive ones.
Engineer time on this build is time not spent on the product your company actually sells, which is the most expensive line of all.
Token costs grow non-linearly as usage climbs, because query-time retrieval gets pricier the more you reason.
The build ships with no auditability, permissions, or monitoring out of the box. Each is its own separate project.
Operators feel this in their renewals too, a pattern we documented in our analysis of Gong pricing. As one revenue leader put it about overpaying for the wrong fit:
"It was a big mistake on our part to commit to a two year term. Gong is a really powerful tool but it's probably the highest end option on the market, and now we're stuck with a tool that works technically but isn't the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"The pricing is probably the biggest obstacle and hence we are looking to change." Miodrag, Enterprise Account Executive Gong G2 Verified Review
The takeaway cuts both ways. Overpaying for a platform you barely use is a real failure mode, and so is a build that quietly costs more than the tool it replaced.
At Oliv, we price for exactly this math. Our plans are modular and seat-based, starting at $19 per user and adding agents one at a time, so the "buy" column above is a real $19 to $49 per user, not a $50K platform fee you commit to on day one.
Q3. Why does the "Claude + RAG over our CRM" build break in production? [toc=3. The Context Trap]
RAG, retrieval-augmented generation, grabs relevant chunks at query time and hands them to the model. That works for shallow tasks like "summarize this call." It collapses on synthesis, like "what is the real risk on this deal across six months of activity and a dozen stakeholders," where it can cost thousands and take minutes per complex query. It fails worst on exactly the long, multi-threaded deals you most need help with. The fix is architectural: pre-compute synthesis as activity arrives.
🧩 The pattern that demos beautifully
The most common DIY build I see is "Claude plus RAG over our Salesforce data." You wire up retrieval, point it at your CRM, and the demo is genuinely impressive. Summaries are clean. Everyone nods.
You have probably already prototyped this, or you are about to. So let me explain where it breaks before you ship it, not after.
⚠️ Retrieval is not synthesis
RAG is great at retrieval, pulling the right chunk to answer a shallow question. Revenue work is mostly synthesis, reasoning across months of scattered activity to form a judgment.
RAG re-reasons from scratch on every question, while a synthesis-first design pre-computes the answer once.
Ask "what is the real risk on this deal" and the system has to read six months of calls, emails, and Slack, then weigh competing storylines. At scale, that means thousands of dollars and real minutes per complex query, because every question triggers a fresh retrieval-and-reasoning pass.
Quality fails worst on low-velocity, multi-stakeholder deals, six months of activity, a dozen contacts, three competing narratives. Those are the exact deals you most need the help on, which is why AI built for sales calls has to go deeper than keyword tracking.
🏗️ The architectural fix: pre-compute as activity arrives
The alternative is to flip when the heavy compute happens. Instead of reasoning from scratch at query time, you maintain a continuously updated semantic view of each deal as activity lands. Query time then becomes seconds, because the answer is already there.
There is a clean historical parallel. Around 2018 to 2019, Gong pulled ahead by pre-computing dozens of static signals per deal rather than inventing a smarter forecasting algorithm. They won on pre-computed inputs. The next generation does the same thing for semantic signals: pain points, compelling events, POC stage, buyer concerns. We unpack the limits of that older approach in our look at Gong forecasting.
To be fair, RAG is the right tool for plenty of problems. It is just the wrong architecture for revenue synthesis at scale. The data-portability complaints under legacy tools show why the underlying data layer matters so much, a theme in our breakdown of Gong features:
"Our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export... it requires downloading calls individually, which is impractical and inefficient for a large volume of data." Neel P., Sales Operations Manager Gong G2 Verified Review
A continuously maintained semantic view per deal is exactly what we built the Oliv Context Graph to do. Synthesis is pre-computed across calls, emails, and Slack as activity happens, so the answer is ready when you ask, instead of being reasoned from scratch and billed by the token.
Q4. Why is a working prototype not a production system, and who can even run one? [toc=4. Production and Talent Traps]
A prototype runs on a laptop, gets called by hand, and breaks when the schema changes. A production agent needs guardrails, permissions and approvals, monitoring, memory management, audit trails, and hallucination handling. Each is its own 6 to 12 month project unrelated to your revenue problem. And running it needs a GTM engineer who understands both deal stages and agent infrastructure. That person barely exists, takes 6 to 12 months to hire at $250K to $400K loaded, and gets poached constantly.
🚀 The gap between "it works" and "it ships"
Buyers conflate "I built a working prototype" with "we have a production system." They are not close. A prototype runs on someone's laptop, gets called by hand, and breaks the moment your Salesforce schema changes.
A production agent is a different animal. It needs guardrails on what it is allowed to do, permissions and approvals for who signs off, monitoring to confirm it is doing the right thing, memory management so it recalls last week, audit and compliance trails, and a plan for when the model hallucinates.
A laptop prototype is nowhere near a production agent, which needs six separate infrastructure layers.
Each of those is a project. Combined, they are 6 to 12 months of infrastructure work that has nothing to do with the revenue problem you set out to solve. Claude Code gets you to the launchpad fast. The harness is how you actually take off without exploding on the pad. The same lesson surfaces across real Agentforce implementation timelines.
👤 The talent trap nobody prices in
Even if you accept all that, the usual next thought is "we will just hire one person to own it." The market for that person barely exists.
The role you need is a GTM engineer. They have to understand revenue process, stages, MEDDPICC (a deal-qualification method), forecast categories, and renewal motions. They also have to understand agent infrastructure, model behavior, prompt patterns, observability, and evaluation frameworks. Translating a method like the MEDDIC sales methodology into live agent logic is itself a specialist skill.
Those two skill sets almost never live in one person. RevOps folks do not speak prompts. ML engineers do not speak deal stages.
⏰ What hiring that unicorn actually costs
Time to fill: 6 to 12 months for a role this rare.
Loaded cost: $250K to $400K per year, FAANG-engineer territory.
Turnover risk: high, because they are in demand everywhere at once.
Even powerful agent platforms confirm how steep the setup and scaling curve is when you go it alone, something we cover in our analysis of Agentforce reviews:
"Setting it up wasn't as smooth as I expected. The UI felt a bit clunky at times... It's definitely not plug-and-play unless you've worked with similar AI flows before. Also, the pricing caught us off guard. Once we started scaling to more users and use cases, the cost ramped up pretty quickly." Verified User Salesforce Agentforce G2 Verified Review
"Gong is solving... insight into the actual voice of the customer. The downside, AI training is a bit laborious to get it to do what you want." Trafford J., Senior Director, Revenue Enablement Gong G2 Verified Review
I could be off on the exact salary band, but the direction is not in question: the harness plus the operator is where most six-month builds quietly stall.
This is where a service layer beats a hire. At Oliv, we ship the production harness, the guardrails, permissions, monitoring, and audit, along with GTM-engineering expertise as a service, so you skip the infrastructure project and the unicorn search at the same time.
Q5. What do the token economics of RAG vs synthesis-first actually look like at scale? [toc=5. Token Cost Reality]
With RAG, retrieval-augmented generation, every query is a fresh retrieval-plus-reasoning pass, so cost scales with both usage and reasoning depth. A 50-rep team running 10,000 complex queries a week can burn $5K to $15K weekly in tokens alone. Synthesis-first flips it. Heavy compute runs once when activity arrives, and later queries are cheap reads against pre-computed state, so cost flattens with usage. Small language models, around 20 to 30 billion parameters, sharpen this further as cost-effective specialists.
💸 Why RAG cost climbs with usage
Let me be precise, because this is where the architecture decision gets real. With RAG, each question triggers a fresh retrieval pass plus a fresh reasoning pass.
That means cost scales on two axes at once: how many queries you run, and how deep the reasoning has to go. A shallow lookup is cheap. A "what is really happening on this deal" question is not, which is why AI sales forecasting software has to be built around deep deal context.
The deeper the synthesis, the more tokens you burn every single time someone asks. Nothing gets reused.
⏰ The worked math on a real team
Here is a checkable example, so you do not have to take my word for it. Picture 50 reps, each managing 20 deals, asking 10 questions per deal per week.
At realistic RAG pricing for deep queries, that lands around $5K to $15K per week in tokens alone.
That is before salaries, hosting, or monitoring.
RAG token costs bend sharply upward with usage, while a synthesis-first architecture keeps them flat.
Run the numbers against your own seat count and query volume. The point is not the exact figure, it is the shape of the curve. It bends upward as you grow.
⭐ How synthesis-first flattens the curve
Synthesis-first inverts when the expensive work happens. You do the heavy reasoning once, the moment activity arrives, and store the result as a continuously updated semantic view.
Later queries become cheap reads against that pre-computed state, not fresh reasoning passes. So as usage climbs, cost flattens instead of spiking. The synthesis cost is amortized across every future question, an architectural edge we explore across the revenue intelligence platforms we track.
This is also where small language models earn their place. A 20-to-30-billion-parameter model, fine-tuned for one narrow job, can extract a specific signal far cheaper than routing everything through a frontier model. To be clear, RAG is the right tool for many problems. It is just the wrong default for revenue synthesis at scale.
At Oliv, our 100-plus fine-tuned models are this synthesis-first approach in production: heavy compute once as signals land, cheap reads after, grounded in your own secure data workspace.
Q6. What actually happens when a smart team tries to build it themselves? [toc=6. When Build Fails]
A mid-market customer-data company ripped out Gainsight and built its own customer-success stack: Braze for messaging, Mixmax for sequencing, Google Sheets for tracking, and a custom ChatGPT for QBR decks. Each tool worked alone. None talked to each other, and the integration glue was a CSM copying between browser tabs. When leadership mandated end-to-end automation, the stack could not deliver, because the connecting tissue was a human. The build was not wrong in 2023. The market moved underneath it.
🏗️ The situation: a smart, self-built stack
A few quarters back, I sat with a customer-success team at a mid-market customer-data company. They had dropped Gainsight years earlier and built their own stack instead.
It was a reasonable build. Braze handled messaging, Mixmax ran email sequences, Google Sheets tracked accounts, and a custom ChatGPT drafted QBR decks and customer comms. Each piece did its job.
⚠️ The complication: the glue was a person
Here is where it cracked. None of those tools talked to each other. The connecting tissue, the thing that moved data from one to the next, was a CSM copying between browser tabs.
Then leadership mandated end-to-end CS automation. The team realized their stack could not be automated, because the integration layer was a human in tabs, not software.
They ran the real math: Braze plus Mixmax plus ChatGPT tokens, plus the hours of CSM glue work. The number surprised them in both directions. A modern platform came out cheaper and more capable, the same gap we see when comparing revenue orchestration platform tools.
This is the same fragmentation operators describe inside legacy tools, where the human is still doing the stitching, a frustration echoed across Clari alternatives:
"Clari is a tool for sales leaders, it adds no value to reps as far as I can see." u/Msoave, r/SalesOperations Reddit Thread
"It is really just a glorified SFDC overlay... I think it can be useful if you have a complex GTM motion but definitely overkill for most companies." u/conaldinho11, r/SalesOperations Reddit Thread
✅ The resolution: a 2023 stack in a 2026 world
I want to be fair to that team. They made good decisions with the information they had in 2023. The build was not a mistake at the time.
The market simply moved underneath them. What they had was a 2023 stack living in a 2026 world, held together by a person clicking between tabs.
The team did not need another tool to glue together. They needed the glue itself to be the product, which is exactly what a Gen-3 agentic platform like Oliv is built to be.
Q7. How do you decide for your own team, the five questions to ask? [toc=7. The Decision Framework]
Ask five honest questions. One, what is the expected annual value: under $20K, build; over $50K, buy. Two, do you have a GTM engineer, or can you hire one in 90 days? Three, is this a synthesis problem or a retrieval problem? Four, will it need to survive an audit? Five, what is your actual core competency, revenue or AI infrastructure? For most readers, two or three answers lean build and two or three lean buy. The point is not to flip you, it is to make you ask the right questions.
✅ The five checks, with real thresholds
By the end of this, you will have a framework you can hand to your CFO or your lead engineer. Five questions, each a genuine check, not a rigged one.
Build vs Buy: A Five-Question Decision Test
Question
Leans build
Leans buy
1. Expected annual value?
Under $20K
Over $50K
2. GTM engineer on staff or hireable in 90 days?
Yes
No
3. Synthesis or retrieval problem?
Retrieval (summaries)
Synthesis (reasoning across months)
4. Must it survive an audit?
No
Yes
5. Core competency?
AI infrastructure
Revenue
Walk each one honestly. If you mostly summarize calls, retrieval is fine and a build is reasonable. If you need to reason across six months of deal activity, that is synthesis, and a DIY build gets expensive fast. Matching the problem to the right tool is the same exercise behind picking the best sales intelligence platform.
⚠️ The honest read of your score
Here is what I will not pretend. For most readers, two or three answers lean build and two or three lean buy. That split is normal, and it is the point.
I am not trying to flip every answer to buy. I am trying to make sure you ask the right five questions before you commit a quarter of engineering time. The audit question alone catches teams off guard, because permissions, monitoring, and audit logs are a separate six-month project, a reality we cover in our implementation timeline breakdown.
If your answers lean buy, you do not have to buy a whole suite on day one. The cheapest next experiment is a single-use-case pilot. Oliv starts at $19 per user and adds agents one at a time, so you can validate the buy path for roughly the cost of an engineer-hour.
Q8. If you are going to keep building, when should you come back and buy instead? [toc=8. When You Hit the Wall]
Many readers will keep building, and that is fine. Come back when context windows blow up, when the GTM engineer leaves, or when the CFO asks why the project is still running. Oliv is not a different way to build the same thing. It is the application layer already built so you do not have to: the Context Graph for synthesis, the agent harness for production, and GTM engineering as a service. When you hit the wall, you will know where to look.
📌 The three moments to bookmark this
I am not going to pretend everyone reading this will buy. A lot of you will keep building, and honestly, that can be the right call for where you are today.
So let me just leave a marker. Come back to this page at one of three moments.
When your context windows blow up and synthesis gets too slow or too expensive.
When your one GTM engineer leaves, and the build leaves with them.
When your CFO asks why this project is still running two quarters in.
⭐ What the application layer already solves
When that moment comes, here is the shift in how I think about it. Oliv is not a smarter way to build the same thing yourself. It is the application layer that has already been built, so you do not have to, much like the shift we map from revenue ops to intelligence to orchestration.
Three pieces map directly to the three walls most builds hit. The Context Graph handles synthesis, the agent harness handles production guardrails, permissions, and monitoring, and GTM engineering comes as a service so you skip the unicorn hire. If you are weighing this against incumbents, our Agentforce alternatives guide is a fair place to start.
We are here when you hit the wall, not to tell you "I told you so." If you are curious now, see how the Context Graph handles synthesis across 100-plus signals per deal in a 7-minute walkthrough with the founder.
References [toc=9. References]
Salesforce. Company history and founding (1999). Foundational context for the year-2000 application-layer pattern, cited as a historical anchor, not a recent source.
NetSuite. Company history and founding (1998). Foundational context for the in-house ERP-to-SaaS migration wave.
NotebookLM build-versus-buy brief. "Year 2000 cycle, real cost math, the $20K threshold, the three traps, token economics, the self-built CS-stack composite, the five-question framework, and the soft-close triggers." First-party brief, 2026.
Anthropic. "Claude API pricing and documentation." Last updated: 2026.
Oliv AI. "Brand messaging guidelines, product overview, and pricing." Vendor documentation. Last updated: April 2026.
Q1. Is building your own revenue AI in 2026 the same bet companies made in the year 2000? [toc=1. The Year 2000 Cycle]
In 2000, Oracle databases existed but Salesforce, Workday, and NetSuite did not. So companies built their own CRMs, ERPs, and HR systems in-house. Most were quietly retired within five years once the application layer matured. AI today is the database in 2000: foundational technology with no mature application layer yet. Building right now is rational. The real question is not whether to build, it is whether what you build still makes sense in 2028.
💾 A scene every RevOps leader knows
Picture a Head of RevOps with two browser tabs open. One is a Gong renewal quote. The other is Claude, mid-conversation, summarizing a sales call beautifully. The math in their head is simple. "If it can do that, why are we paying six figures a year?"
I have watched this exact moment play out across a dozen mid-market revenue teams. It is a fair question. The instinct to build is not naive, it is the correct read of where the technology sits today.
⏰ The pattern repeats every technology cycle
Here is what I keep coming back to. In 1999, Salesforce was a brand new idea and NetSuite was barely founded. If you wanted a CRM or an ERP, you built it. Smart teams did, and their builds worked for a while.
The same timing pattern that turned year-2000 in-house builds into liabilities is repeating with AI today.
Then the application layer arrived. By the mid-2000s, most of those in-house systems were liabilities nobody wanted to maintain. The lesson was not "building was dumb." The lesson was about timing.
When foundational technology shows up before the applications are built on top of it, in-house builds explode. Then the application layer matures, and those same builds become the thing you migrate off of. This is the same arc we trace in our breakdown of how revenue ops evolved into orchestration.
🤔 Where you actually are in the cycle
AI in 2026 is the database in 2000. The foundation models are powerful and cheap to call. The application layer for revenue teams is still young, still unproven to a lot of buyers, and still earning trust, as our roundup of the best revenue intelligence software platforms shows.
So of course people are building. I would be suspicious of any vendor who told you not to. The honest framing is this: building today can be completely rational, and it can still age into a 2023-shaped liability by 2028.
The rest of this piece is not a pitch to stop. It is a way to pressure-test your own build, so the thing you ship survives the next two years instead of quietly getting retired like those year-2000 ERPs.
Q2. What does building revenue AI really cost, and where does building actually win? [toc=2. The Real Math]
Below roughly $20K of expected annual value, building is genuinely cheaper. Say that out loud. Above it, buying compounds faster. A realistic build runs 1 to 2 engineers for 3 to 9 months ($80K to $200K loaded), plus 20% to 30% of that yearly in maintenance, plus production-scale token costs and $10K to $30K in hosting and observability. Buying a mid-market platform typically runs $20K to $50K a year. The cost most buyers forget is opportunity cost: engineer time on this is time not spent on the product you actually sell.
💰 The numbers most comparisons hide
Most build-versus-buy posts cherry-pick the figures, and you know it, so you discount everything they say. I am going to do the opposite and concede where building wins first.
A serious internal build is not "just an API call." Here is the realistic line-up, not the lowballed one.
Build vs Buy: Annual Cost Breakdown
Line item
Build (in-house)
Buy (mid-market platform)
Initial engineering
$80K to $200K loaded (1 to 2 engineers, 3 to 9 months)
$0
Ongoing maintenance
20% to 30% of build cost, every year
Included
Hosting, monitoring, observability
$10K to $30K per year
Included
Production-scale LLM tokens
Grows with usage, often non-linearly
Included in seat price
Typical annual total
Frequently $150K+ in year one
~$20K to $50K per year
💸 The honest threshold
There is a real line. Below about $20K of expected annual value, building is the rational call. The overhead of buying does not pay back at that size.
Above $20K, buying starts to compound in your favor, and past $50K it is rarely close. I have rebuilt internal pipeline tooling myself, and this threshold held up almost every time. If you are weighing platforms at that level, our guide to the best AI sales tools is a useful starting point.
⚠️ The costs that do not show up in the spreadsheet
Three costs get left out, and they are the expensive ones.
Engineer time on this build is time not spent on the product your company actually sells, which is the most expensive line of all.
Token costs grow non-linearly as usage climbs, because query-time retrieval gets pricier the more you reason.
The build ships with no auditability, permissions, or monitoring out of the box. Each is its own separate project.
Operators feel this in their renewals too, a pattern we documented in our analysis of Gong pricing. As one revenue leader put it about overpaying for the wrong fit:
"It was a big mistake on our part to commit to a two year term. Gong is a really powerful tool but it's probably the highest end option on the market, and now we're stuck with a tool that works technically but isn't the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"The pricing is probably the biggest obstacle and hence we are looking to change." Miodrag, Enterprise Account Executive Gong G2 Verified Review
The takeaway cuts both ways. Overpaying for a platform you barely use is a real failure mode, and so is a build that quietly costs more than the tool it replaced.
At Oliv, we price for exactly this math. Our plans are modular and seat-based, starting at $19 per user and adding agents one at a time, so the "buy" column above is a real $19 to $49 per user, not a $50K platform fee you commit to on day one.
Q3. Why does the "Claude + RAG over our CRM" build break in production? [toc=3. The Context Trap]
RAG, retrieval-augmented generation, grabs relevant chunks at query time and hands them to the model. That works for shallow tasks like "summarize this call." It collapses on synthesis, like "what is the real risk on this deal across six months of activity and a dozen stakeholders," where it can cost thousands and take minutes per complex query. It fails worst on exactly the long, multi-threaded deals you most need help with. The fix is architectural: pre-compute synthesis as activity arrives.
🧩 The pattern that demos beautifully
The most common DIY build I see is "Claude plus RAG over our Salesforce data." You wire up retrieval, point it at your CRM, and the demo is genuinely impressive. Summaries are clean. Everyone nods.
You have probably already prototyped this, or you are about to. So let me explain where it breaks before you ship it, not after.
⚠️ Retrieval is not synthesis
RAG is great at retrieval, pulling the right chunk to answer a shallow question. Revenue work is mostly synthesis, reasoning across months of scattered activity to form a judgment.
RAG re-reasons from scratch on every question, while a synthesis-first design pre-computes the answer once.
Ask "what is the real risk on this deal" and the system has to read six months of calls, emails, and Slack, then weigh competing storylines. At scale, that means thousands of dollars and real minutes per complex query, because every question triggers a fresh retrieval-and-reasoning pass.
Quality fails worst on low-velocity, multi-stakeholder deals, six months of activity, a dozen contacts, three competing narratives. Those are the exact deals you most need the help on, which is why AI built for sales calls has to go deeper than keyword tracking.
🏗️ The architectural fix: pre-compute as activity arrives
The alternative is to flip when the heavy compute happens. Instead of reasoning from scratch at query time, you maintain a continuously updated semantic view of each deal as activity lands. Query time then becomes seconds, because the answer is already there.
There is a clean historical parallel. Around 2018 to 2019, Gong pulled ahead by pre-computing dozens of static signals per deal rather than inventing a smarter forecasting algorithm. They won on pre-computed inputs. The next generation does the same thing for semantic signals: pain points, compelling events, POC stage, buyer concerns. We unpack the limits of that older approach in our look at Gong forecasting.
To be fair, RAG is the right tool for plenty of problems. It is just the wrong architecture for revenue synthesis at scale. The data-portability complaints under legacy tools show why the underlying data layer matters so much, a theme in our breakdown of Gong features:
"Our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export... it requires downloading calls individually, which is impractical and inefficient for a large volume of data." Neel P., Sales Operations Manager Gong G2 Verified Review
A continuously maintained semantic view per deal is exactly what we built the Oliv Context Graph to do. Synthesis is pre-computed across calls, emails, and Slack as activity happens, so the answer is ready when you ask, instead of being reasoned from scratch and billed by the token.
Q4. Why is a working prototype not a production system, and who can even run one? [toc=4. Production and Talent Traps]
A prototype runs on a laptop, gets called by hand, and breaks when the schema changes. A production agent needs guardrails, permissions and approvals, monitoring, memory management, audit trails, and hallucination handling. Each is its own 6 to 12 month project unrelated to your revenue problem. And running it needs a GTM engineer who understands both deal stages and agent infrastructure. That person barely exists, takes 6 to 12 months to hire at $250K to $400K loaded, and gets poached constantly.
🚀 The gap between "it works" and "it ships"
Buyers conflate "I built a working prototype" with "we have a production system." They are not close. A prototype runs on someone's laptop, gets called by hand, and breaks the moment your Salesforce schema changes.
A production agent is a different animal. It needs guardrails on what it is allowed to do, permissions and approvals for who signs off, monitoring to confirm it is doing the right thing, memory management so it recalls last week, audit and compliance trails, and a plan for when the model hallucinates.
A laptop prototype is nowhere near a production agent, which needs six separate infrastructure layers.
Each of those is a project. Combined, they are 6 to 12 months of infrastructure work that has nothing to do with the revenue problem you set out to solve. Claude Code gets you to the launchpad fast. The harness is how you actually take off without exploding on the pad. The same lesson surfaces across real Agentforce implementation timelines.
👤 The talent trap nobody prices in
Even if you accept all that, the usual next thought is "we will just hire one person to own it." The market for that person barely exists.
The role you need is a GTM engineer. They have to understand revenue process, stages, MEDDPICC (a deal-qualification method), forecast categories, and renewal motions. They also have to understand agent infrastructure, model behavior, prompt patterns, observability, and evaluation frameworks. Translating a method like the MEDDIC sales methodology into live agent logic is itself a specialist skill.
Those two skill sets almost never live in one person. RevOps folks do not speak prompts. ML engineers do not speak deal stages.
⏰ What hiring that unicorn actually costs
Time to fill: 6 to 12 months for a role this rare.
Loaded cost: $250K to $400K per year, FAANG-engineer territory.
Turnover risk: high, because they are in demand everywhere at once.
Even powerful agent platforms confirm how steep the setup and scaling curve is when you go it alone, something we cover in our analysis of Agentforce reviews:
"Setting it up wasn't as smooth as I expected. The UI felt a bit clunky at times... It's definitely not plug-and-play unless you've worked with similar AI flows before. Also, the pricing caught us off guard. Once we started scaling to more users and use cases, the cost ramped up pretty quickly." Verified User Salesforce Agentforce G2 Verified Review
"Gong is solving... insight into the actual voice of the customer. The downside, AI training is a bit laborious to get it to do what you want." Trafford J., Senior Director, Revenue Enablement Gong G2 Verified Review
I could be off on the exact salary band, but the direction is not in question: the harness plus the operator is where most six-month builds quietly stall.
This is where a service layer beats a hire. At Oliv, we ship the production harness, the guardrails, permissions, monitoring, and audit, along with GTM-engineering expertise as a service, so you skip the infrastructure project and the unicorn search at the same time.
Q5. What do the token economics of RAG vs synthesis-first actually look like at scale? [toc=5. Token Cost Reality]
With RAG, retrieval-augmented generation, every query is a fresh retrieval-plus-reasoning pass, so cost scales with both usage and reasoning depth. A 50-rep team running 10,000 complex queries a week can burn $5K to $15K weekly in tokens alone. Synthesis-first flips it. Heavy compute runs once when activity arrives, and later queries are cheap reads against pre-computed state, so cost flattens with usage. Small language models, around 20 to 30 billion parameters, sharpen this further as cost-effective specialists.
💸 Why RAG cost climbs with usage
Let me be precise, because this is where the architecture decision gets real. With RAG, each question triggers a fresh retrieval pass plus a fresh reasoning pass.
That means cost scales on two axes at once: how many queries you run, and how deep the reasoning has to go. A shallow lookup is cheap. A "what is really happening on this deal" question is not, which is why AI sales forecasting software has to be built around deep deal context.
The deeper the synthesis, the more tokens you burn every single time someone asks. Nothing gets reused.
⏰ The worked math on a real team
Here is a checkable example, so you do not have to take my word for it. Picture 50 reps, each managing 20 deals, asking 10 questions per deal per week.
At realistic RAG pricing for deep queries, that lands around $5K to $15K per week in tokens alone.
That is before salaries, hosting, or monitoring.
RAG token costs bend sharply upward with usage, while a synthesis-first architecture keeps them flat.
Run the numbers against your own seat count and query volume. The point is not the exact figure, it is the shape of the curve. It bends upward as you grow.
⭐ How synthesis-first flattens the curve
Synthesis-first inverts when the expensive work happens. You do the heavy reasoning once, the moment activity arrives, and store the result as a continuously updated semantic view.
Later queries become cheap reads against that pre-computed state, not fresh reasoning passes. So as usage climbs, cost flattens instead of spiking. The synthesis cost is amortized across every future question, an architectural edge we explore across the revenue intelligence platforms we track.
This is also where small language models earn their place. A 20-to-30-billion-parameter model, fine-tuned for one narrow job, can extract a specific signal far cheaper than routing everything through a frontier model. To be clear, RAG is the right tool for many problems. It is just the wrong default for revenue synthesis at scale.
At Oliv, our 100-plus fine-tuned models are this synthesis-first approach in production: heavy compute once as signals land, cheap reads after, grounded in your own secure data workspace.
Q6. What actually happens when a smart team tries to build it themselves? [toc=6. When Build Fails]
A mid-market customer-data company ripped out Gainsight and built its own customer-success stack: Braze for messaging, Mixmax for sequencing, Google Sheets for tracking, and a custom ChatGPT for QBR decks. Each tool worked alone. None talked to each other, and the integration glue was a CSM copying between browser tabs. When leadership mandated end-to-end automation, the stack could not deliver, because the connecting tissue was a human. The build was not wrong in 2023. The market moved underneath it.
🏗️ The situation: a smart, self-built stack
A few quarters back, I sat with a customer-success team at a mid-market customer-data company. They had dropped Gainsight years earlier and built their own stack instead.
It was a reasonable build. Braze handled messaging, Mixmax ran email sequences, Google Sheets tracked accounts, and a custom ChatGPT drafted QBR decks and customer comms. Each piece did its job.
⚠️ The complication: the glue was a person
Here is where it cracked. None of those tools talked to each other. The connecting tissue, the thing that moved data from one to the next, was a CSM copying between browser tabs.
Then leadership mandated end-to-end CS automation. The team realized their stack could not be automated, because the integration layer was a human in tabs, not software.
They ran the real math: Braze plus Mixmax plus ChatGPT tokens, plus the hours of CSM glue work. The number surprised them in both directions. A modern platform came out cheaper and more capable, the same gap we see when comparing revenue orchestration platform tools.
This is the same fragmentation operators describe inside legacy tools, where the human is still doing the stitching, a frustration echoed across Clari alternatives:
"Clari is a tool for sales leaders, it adds no value to reps as far as I can see." u/Msoave, r/SalesOperations Reddit Thread
"It is really just a glorified SFDC overlay... I think it can be useful if you have a complex GTM motion but definitely overkill for most companies." u/conaldinho11, r/SalesOperations Reddit Thread
✅ The resolution: a 2023 stack in a 2026 world
I want to be fair to that team. They made good decisions with the information they had in 2023. The build was not a mistake at the time.
The market simply moved underneath them. What they had was a 2023 stack living in a 2026 world, held together by a person clicking between tabs.
The team did not need another tool to glue together. They needed the glue itself to be the product, which is exactly what a Gen-3 agentic platform like Oliv is built to be.
Q7. How do you decide for your own team, the five questions to ask? [toc=7. The Decision Framework]
Ask five honest questions. One, what is the expected annual value: under $20K, build; over $50K, buy. Two, do you have a GTM engineer, or can you hire one in 90 days? Three, is this a synthesis problem or a retrieval problem? Four, will it need to survive an audit? Five, what is your actual core competency, revenue or AI infrastructure? For most readers, two or three answers lean build and two or three lean buy. The point is not to flip you, it is to make you ask the right questions.
✅ The five checks, with real thresholds
By the end of this, you will have a framework you can hand to your CFO or your lead engineer. Five questions, each a genuine check, not a rigged one.
Build vs Buy: A Five-Question Decision Test
Question
Leans build
Leans buy
1. Expected annual value?
Under $20K
Over $50K
2. GTM engineer on staff or hireable in 90 days?
Yes
No
3. Synthesis or retrieval problem?
Retrieval (summaries)
Synthesis (reasoning across months)
4. Must it survive an audit?
No
Yes
5. Core competency?
AI infrastructure
Revenue
Walk each one honestly. If you mostly summarize calls, retrieval is fine and a build is reasonable. If you need to reason across six months of deal activity, that is synthesis, and a DIY build gets expensive fast. Matching the problem to the right tool is the same exercise behind picking the best sales intelligence platform.
⚠️ The honest read of your score
Here is what I will not pretend. For most readers, two or three answers lean build and two or three lean buy. That split is normal, and it is the point.
I am not trying to flip every answer to buy. I am trying to make sure you ask the right five questions before you commit a quarter of engineering time. The audit question alone catches teams off guard, because permissions, monitoring, and audit logs are a separate six-month project, a reality we cover in our implementation timeline breakdown.
If your answers lean buy, you do not have to buy a whole suite on day one. The cheapest next experiment is a single-use-case pilot. Oliv starts at $19 per user and adds agents one at a time, so you can validate the buy path for roughly the cost of an engineer-hour.
Q8. If you are going to keep building, when should you come back and buy instead? [toc=8. When You Hit the Wall]
Many readers will keep building, and that is fine. Come back when context windows blow up, when the GTM engineer leaves, or when the CFO asks why the project is still running. Oliv is not a different way to build the same thing. It is the application layer already built so you do not have to: the Context Graph for synthesis, the agent harness for production, and GTM engineering as a service. When you hit the wall, you will know where to look.
📌 The three moments to bookmark this
I am not going to pretend everyone reading this will buy. A lot of you will keep building, and honestly, that can be the right call for where you are today.
So let me just leave a marker. Come back to this page at one of three moments.
When your context windows blow up and synthesis gets too slow or too expensive.
When your one GTM engineer leaves, and the build leaves with them.
When your CFO asks why this project is still running two quarters in.
⭐ What the application layer already solves
When that moment comes, here is the shift in how I think about it. Oliv is not a smarter way to build the same thing yourself. It is the application layer that has already been built, so you do not have to, much like the shift we map from revenue ops to intelligence to orchestration.
Three pieces map directly to the three walls most builds hit. The Context Graph handles synthesis, the agent harness handles production guardrails, permissions, and monitoring, and GTM engineering comes as a service so you skip the unicorn hire. If you are weighing this against incumbents, our Agentforce alternatives guide is a fair place to start.
We are here when you hit the wall, not to tell you "I told you so." If you are curious now, see how the Context Graph handles synthesis across 100-plus signals per deal in a 7-minute walkthrough with the founder.
References [toc=9. References]
Salesforce. Company history and founding (1999). Foundational context for the year-2000 application-layer pattern, cited as a historical anchor, not a recent source.
NetSuite. Company history and founding (1998). Foundational context for the in-house ERP-to-SaaS migration wave.
NotebookLM build-versus-buy brief. "Year 2000 cycle, real cost math, the $20K threshold, the three traps, token economics, the self-built CS-stack composite, the five-question framework, and the soft-close triggers." First-party brief, 2026.
Anthropic. "Claude API pricing and documentation." Last updated: 2026.
Oliv AI. "Brand messaging guidelines, product overview, and pricing." Vendor documentation. Last updated: April 2026.
Q1. Is building your own revenue AI in 2026 the same bet companies made in the year 2000? [toc=1. The Year 2000 Cycle]
In 2000, Oracle databases existed but Salesforce, Workday, and NetSuite did not. So companies built their own CRMs, ERPs, and HR systems in-house. Most were quietly retired within five years once the application layer matured. AI today is the database in 2000: foundational technology with no mature application layer yet. Building right now is rational. The real question is not whether to build, it is whether what you build still makes sense in 2028.
💾 A scene every RevOps leader knows
Picture a Head of RevOps with two browser tabs open. One is a Gong renewal quote. The other is Claude, mid-conversation, summarizing a sales call beautifully. The math in their head is simple. "If it can do that, why are we paying six figures a year?"
I have watched this exact moment play out across a dozen mid-market revenue teams. It is a fair question. The instinct to build is not naive, it is the correct read of where the technology sits today.
⏰ The pattern repeats every technology cycle
Here is what I keep coming back to. In 1999, Salesforce was a brand new idea and NetSuite was barely founded. If you wanted a CRM or an ERP, you built it. Smart teams did, and their builds worked for a while.
The same timing pattern that turned year-2000 in-house builds into liabilities is repeating with AI today.
Then the application layer arrived. By the mid-2000s, most of those in-house systems were liabilities nobody wanted to maintain. The lesson was not "building was dumb." The lesson was about timing.
When foundational technology shows up before the applications are built on top of it, in-house builds explode. Then the application layer matures, and those same builds become the thing you migrate off of. This is the same arc we trace in our breakdown of how revenue ops evolved into orchestration.
🤔 Where you actually are in the cycle
AI in 2026 is the database in 2000. The foundation models are powerful and cheap to call. The application layer for revenue teams is still young, still unproven to a lot of buyers, and still earning trust, as our roundup of the best revenue intelligence software platforms shows.
So of course people are building. I would be suspicious of any vendor who told you not to. The honest framing is this: building today can be completely rational, and it can still age into a 2023-shaped liability by 2028.
The rest of this piece is not a pitch to stop. It is a way to pressure-test your own build, so the thing you ship survives the next two years instead of quietly getting retired like those year-2000 ERPs.
Q2. What does building revenue AI really cost, and where does building actually win? [toc=2. The Real Math]
Below roughly $20K of expected annual value, building is genuinely cheaper. Say that out loud. Above it, buying compounds faster. A realistic build runs 1 to 2 engineers for 3 to 9 months ($80K to $200K loaded), plus 20% to 30% of that yearly in maintenance, plus production-scale token costs and $10K to $30K in hosting and observability. Buying a mid-market platform typically runs $20K to $50K a year. The cost most buyers forget is opportunity cost: engineer time on this is time not spent on the product you actually sell.
💰 The numbers most comparisons hide
Most build-versus-buy posts cherry-pick the figures, and you know it, so you discount everything they say. I am going to do the opposite and concede where building wins first.
A serious internal build is not "just an API call." Here is the realistic line-up, not the lowballed one.
Build vs Buy: Annual Cost Breakdown
Line item
Build (in-house)
Buy (mid-market platform)
Initial engineering
$80K to $200K loaded (1 to 2 engineers, 3 to 9 months)
$0
Ongoing maintenance
20% to 30% of build cost, every year
Included
Hosting, monitoring, observability
$10K to $30K per year
Included
Production-scale LLM tokens
Grows with usage, often non-linearly
Included in seat price
Typical annual total
Frequently $150K+ in year one
~$20K to $50K per year
💸 The honest threshold
There is a real line. Below about $20K of expected annual value, building is the rational call. The overhead of buying does not pay back at that size.
Above $20K, buying starts to compound in your favor, and past $50K it is rarely close. I have rebuilt internal pipeline tooling myself, and this threshold held up almost every time. If you are weighing platforms at that level, our guide to the best AI sales tools is a useful starting point.
⚠️ The costs that do not show up in the spreadsheet
Three costs get left out, and they are the expensive ones.
Engineer time on this build is time not spent on the product your company actually sells, which is the most expensive line of all.
Token costs grow non-linearly as usage climbs, because query-time retrieval gets pricier the more you reason.
The build ships with no auditability, permissions, or monitoring out of the box. Each is its own separate project.
Operators feel this in their renewals too, a pattern we documented in our analysis of Gong pricing. As one revenue leader put it about overpaying for the wrong fit:
"It was a big mistake on our part to commit to a two year term. Gong is a really powerful tool but it's probably the highest end option on the market, and now we're stuck with a tool that works technically but isn't the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"The pricing is probably the biggest obstacle and hence we are looking to change." Miodrag, Enterprise Account Executive Gong G2 Verified Review
The takeaway cuts both ways. Overpaying for a platform you barely use is a real failure mode, and so is a build that quietly costs more than the tool it replaced.
At Oliv, we price for exactly this math. Our plans are modular and seat-based, starting at $19 per user and adding agents one at a time, so the "buy" column above is a real $19 to $49 per user, not a $50K platform fee you commit to on day one.
Q3. Why does the "Claude + RAG over our CRM" build break in production? [toc=3. The Context Trap]
RAG, retrieval-augmented generation, grabs relevant chunks at query time and hands them to the model. That works for shallow tasks like "summarize this call." It collapses on synthesis, like "what is the real risk on this deal across six months of activity and a dozen stakeholders," where it can cost thousands and take minutes per complex query. It fails worst on exactly the long, multi-threaded deals you most need help with. The fix is architectural: pre-compute synthesis as activity arrives.
🧩 The pattern that demos beautifully
The most common DIY build I see is "Claude plus RAG over our Salesforce data." You wire up retrieval, point it at your CRM, and the demo is genuinely impressive. Summaries are clean. Everyone nods.
You have probably already prototyped this, or you are about to. So let me explain where it breaks before you ship it, not after.
⚠️ Retrieval is not synthesis
RAG is great at retrieval, pulling the right chunk to answer a shallow question. Revenue work is mostly synthesis, reasoning across months of scattered activity to form a judgment.
RAG re-reasons from scratch on every question, while a synthesis-first design pre-computes the answer once.
Ask "what is the real risk on this deal" and the system has to read six months of calls, emails, and Slack, then weigh competing storylines. At scale, that means thousands of dollars and real minutes per complex query, because every question triggers a fresh retrieval-and-reasoning pass.
Quality fails worst on low-velocity, multi-stakeholder deals, six months of activity, a dozen contacts, three competing narratives. Those are the exact deals you most need the help on, which is why AI built for sales calls has to go deeper than keyword tracking.
🏗️ The architectural fix: pre-compute as activity arrives
The alternative is to flip when the heavy compute happens. Instead of reasoning from scratch at query time, you maintain a continuously updated semantic view of each deal as activity lands. Query time then becomes seconds, because the answer is already there.
There is a clean historical parallel. Around 2018 to 2019, Gong pulled ahead by pre-computing dozens of static signals per deal rather than inventing a smarter forecasting algorithm. They won on pre-computed inputs. The next generation does the same thing for semantic signals: pain points, compelling events, POC stage, buyer concerns. We unpack the limits of that older approach in our look at Gong forecasting.
To be fair, RAG is the right tool for plenty of problems. It is just the wrong architecture for revenue synthesis at scale. The data-portability complaints under legacy tools show why the underlying data layer matters so much, a theme in our breakdown of Gong features:
"Our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export... it requires downloading calls individually, which is impractical and inefficient for a large volume of data." Neel P., Sales Operations Manager Gong G2 Verified Review
A continuously maintained semantic view per deal is exactly what we built the Oliv Context Graph to do. Synthesis is pre-computed across calls, emails, and Slack as activity happens, so the answer is ready when you ask, instead of being reasoned from scratch and billed by the token.
Q4. Why is a working prototype not a production system, and who can even run one? [toc=4. Production and Talent Traps]
A prototype runs on a laptop, gets called by hand, and breaks when the schema changes. A production agent needs guardrails, permissions and approvals, monitoring, memory management, audit trails, and hallucination handling. Each is its own 6 to 12 month project unrelated to your revenue problem. And running it needs a GTM engineer who understands both deal stages and agent infrastructure. That person barely exists, takes 6 to 12 months to hire at $250K to $400K loaded, and gets poached constantly.
🚀 The gap between "it works" and "it ships"
Buyers conflate "I built a working prototype" with "we have a production system." They are not close. A prototype runs on someone's laptop, gets called by hand, and breaks the moment your Salesforce schema changes.
A production agent is a different animal. It needs guardrails on what it is allowed to do, permissions and approvals for who signs off, monitoring to confirm it is doing the right thing, memory management so it recalls last week, audit and compliance trails, and a plan for when the model hallucinates.
A laptop prototype is nowhere near a production agent, which needs six separate infrastructure layers.
Each of those is a project. Combined, they are 6 to 12 months of infrastructure work that has nothing to do with the revenue problem you set out to solve. Claude Code gets you to the launchpad fast. The harness is how you actually take off without exploding on the pad. The same lesson surfaces across real Agentforce implementation timelines.
👤 The talent trap nobody prices in
Even if you accept all that, the usual next thought is "we will just hire one person to own it." The market for that person barely exists.
The role you need is a GTM engineer. They have to understand revenue process, stages, MEDDPICC (a deal-qualification method), forecast categories, and renewal motions. They also have to understand agent infrastructure, model behavior, prompt patterns, observability, and evaluation frameworks. Translating a method like the MEDDIC sales methodology into live agent logic is itself a specialist skill.
Those two skill sets almost never live in one person. RevOps folks do not speak prompts. ML engineers do not speak deal stages.
⏰ What hiring that unicorn actually costs
Time to fill: 6 to 12 months for a role this rare.
Loaded cost: $250K to $400K per year, FAANG-engineer territory.
Turnover risk: high, because they are in demand everywhere at once.
Even powerful agent platforms confirm how steep the setup and scaling curve is when you go it alone, something we cover in our analysis of Agentforce reviews:
"Setting it up wasn't as smooth as I expected. The UI felt a bit clunky at times... It's definitely not plug-and-play unless you've worked with similar AI flows before. Also, the pricing caught us off guard. Once we started scaling to more users and use cases, the cost ramped up pretty quickly." Verified User Salesforce Agentforce G2 Verified Review
"Gong is solving... insight into the actual voice of the customer. The downside, AI training is a bit laborious to get it to do what you want." Trafford J., Senior Director, Revenue Enablement Gong G2 Verified Review
I could be off on the exact salary band, but the direction is not in question: the harness plus the operator is where most six-month builds quietly stall.
This is where a service layer beats a hire. At Oliv, we ship the production harness, the guardrails, permissions, monitoring, and audit, along with GTM-engineering expertise as a service, so you skip the infrastructure project and the unicorn search at the same time.
Q5. What do the token economics of RAG vs synthesis-first actually look like at scale? [toc=5. Token Cost Reality]
With RAG, retrieval-augmented generation, every query is a fresh retrieval-plus-reasoning pass, so cost scales with both usage and reasoning depth. A 50-rep team running 10,000 complex queries a week can burn $5K to $15K weekly in tokens alone. Synthesis-first flips it. Heavy compute runs once when activity arrives, and later queries are cheap reads against pre-computed state, so cost flattens with usage. Small language models, around 20 to 30 billion parameters, sharpen this further as cost-effective specialists.
💸 Why RAG cost climbs with usage
Let me be precise, because this is where the architecture decision gets real. With RAG, each question triggers a fresh retrieval pass plus a fresh reasoning pass.
That means cost scales on two axes at once: how many queries you run, and how deep the reasoning has to go. A shallow lookup is cheap. A "what is really happening on this deal" question is not, which is why AI sales forecasting software has to be built around deep deal context.
The deeper the synthesis, the more tokens you burn every single time someone asks. Nothing gets reused.
⏰ The worked math on a real team
Here is a checkable example, so you do not have to take my word for it. Picture 50 reps, each managing 20 deals, asking 10 questions per deal per week.
At realistic RAG pricing for deep queries, that lands around $5K to $15K per week in tokens alone.
That is before salaries, hosting, or monitoring.
RAG token costs bend sharply upward with usage, while a synthesis-first architecture keeps them flat.
Run the numbers against your own seat count and query volume. The point is not the exact figure, it is the shape of the curve. It bends upward as you grow.
⭐ How synthesis-first flattens the curve
Synthesis-first inverts when the expensive work happens. You do the heavy reasoning once, the moment activity arrives, and store the result as a continuously updated semantic view.
Later queries become cheap reads against that pre-computed state, not fresh reasoning passes. So as usage climbs, cost flattens instead of spiking. The synthesis cost is amortized across every future question, an architectural edge we explore across the revenue intelligence platforms we track.
This is also where small language models earn their place. A 20-to-30-billion-parameter model, fine-tuned for one narrow job, can extract a specific signal far cheaper than routing everything through a frontier model. To be clear, RAG is the right tool for many problems. It is just the wrong default for revenue synthesis at scale.
At Oliv, our 100-plus fine-tuned models are this synthesis-first approach in production: heavy compute once as signals land, cheap reads after, grounded in your own secure data workspace.
Q6. What actually happens when a smart team tries to build it themselves? [toc=6. When Build Fails]
A mid-market customer-data company ripped out Gainsight and built its own customer-success stack: Braze for messaging, Mixmax for sequencing, Google Sheets for tracking, and a custom ChatGPT for QBR decks. Each tool worked alone. None talked to each other, and the integration glue was a CSM copying between browser tabs. When leadership mandated end-to-end automation, the stack could not deliver, because the connecting tissue was a human. The build was not wrong in 2023. The market moved underneath it.
🏗️ The situation: a smart, self-built stack
A few quarters back, I sat with a customer-success team at a mid-market customer-data company. They had dropped Gainsight years earlier and built their own stack instead.
It was a reasonable build. Braze handled messaging, Mixmax ran email sequences, Google Sheets tracked accounts, and a custom ChatGPT drafted QBR decks and customer comms. Each piece did its job.
⚠️ The complication: the glue was a person
Here is where it cracked. None of those tools talked to each other. The connecting tissue, the thing that moved data from one to the next, was a CSM copying between browser tabs.
Then leadership mandated end-to-end CS automation. The team realized their stack could not be automated, because the integration layer was a human in tabs, not software.
They ran the real math: Braze plus Mixmax plus ChatGPT tokens, plus the hours of CSM glue work. The number surprised them in both directions. A modern platform came out cheaper and more capable, the same gap we see when comparing revenue orchestration platform tools.
This is the same fragmentation operators describe inside legacy tools, where the human is still doing the stitching, a frustration echoed across Clari alternatives:
"Clari is a tool for sales leaders, it adds no value to reps as far as I can see." u/Msoave, r/SalesOperations Reddit Thread
"It is really just a glorified SFDC overlay... I think it can be useful if you have a complex GTM motion but definitely overkill for most companies." u/conaldinho11, r/SalesOperations Reddit Thread
✅ The resolution: a 2023 stack in a 2026 world
I want to be fair to that team. They made good decisions with the information they had in 2023. The build was not a mistake at the time.
The market simply moved underneath them. What they had was a 2023 stack living in a 2026 world, held together by a person clicking between tabs.
The team did not need another tool to glue together. They needed the glue itself to be the product, which is exactly what a Gen-3 agentic platform like Oliv is built to be.
Q7. How do you decide for your own team, the five questions to ask? [toc=7. The Decision Framework]
Ask five honest questions. One, what is the expected annual value: under $20K, build; over $50K, buy. Two, do you have a GTM engineer, or can you hire one in 90 days? Three, is this a synthesis problem or a retrieval problem? Four, will it need to survive an audit? Five, what is your actual core competency, revenue or AI infrastructure? For most readers, two or three answers lean build and two or three lean buy. The point is not to flip you, it is to make you ask the right questions.
✅ The five checks, with real thresholds
By the end of this, you will have a framework you can hand to your CFO or your lead engineer. Five questions, each a genuine check, not a rigged one.
Build vs Buy: A Five-Question Decision Test
Question
Leans build
Leans buy
1. Expected annual value?
Under $20K
Over $50K
2. GTM engineer on staff or hireable in 90 days?
Yes
No
3. Synthesis or retrieval problem?
Retrieval (summaries)
Synthesis (reasoning across months)
4. Must it survive an audit?
No
Yes
5. Core competency?
AI infrastructure
Revenue
Walk each one honestly. If you mostly summarize calls, retrieval is fine and a build is reasonable. If you need to reason across six months of deal activity, that is synthesis, and a DIY build gets expensive fast. Matching the problem to the right tool is the same exercise behind picking the best sales intelligence platform.
⚠️ The honest read of your score
Here is what I will not pretend. For most readers, two or three answers lean build and two or three lean buy. That split is normal, and it is the point.
I am not trying to flip every answer to buy. I am trying to make sure you ask the right five questions before you commit a quarter of engineering time. The audit question alone catches teams off guard, because permissions, monitoring, and audit logs are a separate six-month project, a reality we cover in our implementation timeline breakdown.
If your answers lean buy, you do not have to buy a whole suite on day one. The cheapest next experiment is a single-use-case pilot. Oliv starts at $19 per user and adds agents one at a time, so you can validate the buy path for roughly the cost of an engineer-hour.
Q8. If you are going to keep building, when should you come back and buy instead? [toc=8. When You Hit the Wall]
Many readers will keep building, and that is fine. Come back when context windows blow up, when the GTM engineer leaves, or when the CFO asks why the project is still running. Oliv is not a different way to build the same thing. It is the application layer already built so you do not have to: the Context Graph for synthesis, the agent harness for production, and GTM engineering as a service. When you hit the wall, you will know where to look.
📌 The three moments to bookmark this
I am not going to pretend everyone reading this will buy. A lot of you will keep building, and honestly, that can be the right call for where you are today.
So let me just leave a marker. Come back to this page at one of three moments.
When your context windows blow up and synthesis gets too slow or too expensive.
When your one GTM engineer leaves, and the build leaves with them.
When your CFO asks why this project is still running two quarters in.
⭐ What the application layer already solves
When that moment comes, here is the shift in how I think about it. Oliv is not a smarter way to build the same thing yourself. It is the application layer that has already been built, so you do not have to, much like the shift we map from revenue ops to intelligence to orchestration.
Three pieces map directly to the three walls most builds hit. The Context Graph handles synthesis, the agent harness handles production guardrails, permissions, and monitoring, and GTM engineering comes as a service so you skip the unicorn hire. If you are weighing this against incumbents, our Agentforce alternatives guide is a fair place to start.
We are here when you hit the wall, not to tell you "I told you so." If you are curious now, see how the Context Graph handles synthesis across 100-plus signals per deal in a 7-minute walkthrough with the founder.
References [toc=9. References]
Salesforce. Company history and founding (1999). Foundational context for the year-2000 application-layer pattern, cited as a historical anchor, not a recent source.
NetSuite. Company history and founding (1998). Foundational context for the in-house ERP-to-SaaS migration wave.
NotebookLM build-versus-buy brief. "Year 2000 cycle, real cost math, the $20K threshold, the three traps, token economics, the self-built CS-stack composite, the five-question framework, and the soft-close triggers." First-party brief, 2026.
Anthropic. "Claude API pricing and documentation." Last updated: 2026.
Oliv AI. "Brand messaging guidelines, product overview, and pricing." Vendor documentation. Last updated: April 2026.
Q1. Is building your own revenue AI in 2026 the same bet companies made in the year 2000? [toc=1. The Year 2000 Cycle]
In 2000, Oracle databases existed but Salesforce, Workday, and NetSuite did not. So companies built their own CRMs, ERPs, and HR systems in-house. Most were quietly retired within five years once the application layer matured. AI today is the database in 2000: foundational technology with no mature application layer yet. Building right now is rational. The real question is not whether to build, it is whether what you build still makes sense in 2028.
💾 A scene every RevOps leader knows
Picture a Head of RevOps with two browser tabs open. One is a Gong renewal quote. The other is Claude, mid-conversation, summarizing a sales call beautifully. The math in their head is simple. "If it can do that, why are we paying six figures a year?"
I have watched this exact moment play out across a dozen mid-market revenue teams. It is a fair question. The instinct to build is not naive, it is the correct read of where the technology sits today.
⏰ The pattern repeats every technology cycle
Here is what I keep coming back to. In 1999, Salesforce was a brand new idea and NetSuite was barely founded. If you wanted a CRM or an ERP, you built it. Smart teams did, and their builds worked for a while.
The same timing pattern that turned year-2000 in-house builds into liabilities is repeating with AI today.
Then the application layer arrived. By the mid-2000s, most of those in-house systems were liabilities nobody wanted to maintain. The lesson was not "building was dumb." The lesson was about timing.
When foundational technology shows up before the applications are built on top of it, in-house builds explode. Then the application layer matures, and those same builds become the thing you migrate off of. This is the same arc we trace in our breakdown of how revenue ops evolved into orchestration.
🤔 Where you actually are in the cycle
AI in 2026 is the database in 2000. The foundation models are powerful and cheap to call. The application layer for revenue teams is still young, still unproven to a lot of buyers, and still earning trust, as our roundup of the best revenue intelligence software platforms shows.
So of course people are building. I would be suspicious of any vendor who told you not to. The honest framing is this: building today can be completely rational, and it can still age into a 2023-shaped liability by 2028.
The rest of this piece is not a pitch to stop. It is a way to pressure-test your own build, so the thing you ship survives the next two years instead of quietly getting retired like those year-2000 ERPs.
Q2. What does building revenue AI really cost, and where does building actually win? [toc=2. The Real Math]
Below roughly $20K of expected annual value, building is genuinely cheaper. Say that out loud. Above it, buying compounds faster. A realistic build runs 1 to 2 engineers for 3 to 9 months ($80K to $200K loaded), plus 20% to 30% of that yearly in maintenance, plus production-scale token costs and $10K to $30K in hosting and observability. Buying a mid-market platform typically runs $20K to $50K a year. The cost most buyers forget is opportunity cost: engineer time on this is time not spent on the product you actually sell.
💰 The numbers most comparisons hide
Most build-versus-buy posts cherry-pick the figures, and you know it, so you discount everything they say. I am going to do the opposite and concede where building wins first.
A serious internal build is not "just an API call." Here is the realistic line-up, not the lowballed one.
Build vs Buy: Annual Cost Breakdown
Line item
Build (in-house)
Buy (mid-market platform)
Initial engineering
$80K to $200K loaded (1 to 2 engineers, 3 to 9 months)
$0
Ongoing maintenance
20% to 30% of build cost, every year
Included
Hosting, monitoring, observability
$10K to $30K per year
Included
Production-scale LLM tokens
Grows with usage, often non-linearly
Included in seat price
Typical annual total
Frequently $150K+ in year one
~$20K to $50K per year
💸 The honest threshold
There is a real line. Below about $20K of expected annual value, building is the rational call. The overhead of buying does not pay back at that size.
Above $20K, buying starts to compound in your favor, and past $50K it is rarely close. I have rebuilt internal pipeline tooling myself, and this threshold held up almost every time. If you are weighing platforms at that level, our guide to the best AI sales tools is a useful starting point.
⚠️ The costs that do not show up in the spreadsheet
Three costs get left out, and they are the expensive ones.
Engineer time on this build is time not spent on the product your company actually sells, which is the most expensive line of all.
Token costs grow non-linearly as usage climbs, because query-time retrieval gets pricier the more you reason.
The build ships with no auditability, permissions, or monitoring out of the box. Each is its own separate project.
Operators feel this in their renewals too, a pattern we documented in our analysis of Gong pricing. As one revenue leader put it about overpaying for the wrong fit:
"It was a big mistake on our part to commit to a two year term. Gong is a really powerful tool but it's probably the highest end option on the market, and now we're stuck with a tool that works technically but isn't the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"The pricing is probably the biggest obstacle and hence we are looking to change." Miodrag, Enterprise Account Executive Gong G2 Verified Review
The takeaway cuts both ways. Overpaying for a platform you barely use is a real failure mode, and so is a build that quietly costs more than the tool it replaced.
At Oliv, we price for exactly this math. Our plans are modular and seat-based, starting at $19 per user and adding agents one at a time, so the "buy" column above is a real $19 to $49 per user, not a $50K platform fee you commit to on day one.
Q3. Why does the "Claude + RAG over our CRM" build break in production? [toc=3. The Context Trap]
RAG, retrieval-augmented generation, grabs relevant chunks at query time and hands them to the model. That works for shallow tasks like "summarize this call." It collapses on synthesis, like "what is the real risk on this deal across six months of activity and a dozen stakeholders," where it can cost thousands and take minutes per complex query. It fails worst on exactly the long, multi-threaded deals you most need help with. The fix is architectural: pre-compute synthesis as activity arrives.
🧩 The pattern that demos beautifully
The most common DIY build I see is "Claude plus RAG over our Salesforce data." You wire up retrieval, point it at your CRM, and the demo is genuinely impressive. Summaries are clean. Everyone nods.
You have probably already prototyped this, or you are about to. So let me explain where it breaks before you ship it, not after.
⚠️ Retrieval is not synthesis
RAG is great at retrieval, pulling the right chunk to answer a shallow question. Revenue work is mostly synthesis, reasoning across months of scattered activity to form a judgment.
RAG re-reasons from scratch on every question, while a synthesis-first design pre-computes the answer once.
Ask "what is the real risk on this deal" and the system has to read six months of calls, emails, and Slack, then weigh competing storylines. At scale, that means thousands of dollars and real minutes per complex query, because every question triggers a fresh retrieval-and-reasoning pass.
Quality fails worst on low-velocity, multi-stakeholder deals, six months of activity, a dozen contacts, three competing narratives. Those are the exact deals you most need the help on, which is why AI built for sales calls has to go deeper than keyword tracking.
🏗️ The architectural fix: pre-compute as activity arrives
The alternative is to flip when the heavy compute happens. Instead of reasoning from scratch at query time, you maintain a continuously updated semantic view of each deal as activity lands. Query time then becomes seconds, because the answer is already there.
There is a clean historical parallel. Around 2018 to 2019, Gong pulled ahead by pre-computing dozens of static signals per deal rather than inventing a smarter forecasting algorithm. They won on pre-computed inputs. The next generation does the same thing for semantic signals: pain points, compelling events, POC stage, buyer concerns. We unpack the limits of that older approach in our look at Gong forecasting.
To be fair, RAG is the right tool for plenty of problems. It is just the wrong architecture for revenue synthesis at scale. The data-portability complaints under legacy tools show why the underlying data layer matters so much, a theme in our breakdown of Gong features:
"Our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export... it requires downloading calls individually, which is impractical and inefficient for a large volume of data." Neel P., Sales Operations Manager Gong G2 Verified Review
A continuously maintained semantic view per deal is exactly what we built the Oliv Context Graph to do. Synthesis is pre-computed across calls, emails, and Slack as activity happens, so the answer is ready when you ask, instead of being reasoned from scratch and billed by the token.
Q4. Why is a working prototype not a production system, and who can even run one? [toc=4. Production and Talent Traps]
A prototype runs on a laptop, gets called by hand, and breaks when the schema changes. A production agent needs guardrails, permissions and approvals, monitoring, memory management, audit trails, and hallucination handling. Each is its own 6 to 12 month project unrelated to your revenue problem. And running it needs a GTM engineer who understands both deal stages and agent infrastructure. That person barely exists, takes 6 to 12 months to hire at $250K to $400K loaded, and gets poached constantly.
🚀 The gap between "it works" and "it ships"
Buyers conflate "I built a working prototype" with "we have a production system." They are not close. A prototype runs on someone's laptop, gets called by hand, and breaks the moment your Salesforce schema changes.
A production agent is a different animal. It needs guardrails on what it is allowed to do, permissions and approvals for who signs off, monitoring to confirm it is doing the right thing, memory management so it recalls last week, audit and compliance trails, and a plan for when the model hallucinates.
A laptop prototype is nowhere near a production agent, which needs six separate infrastructure layers.
Each of those is a project. Combined, they are 6 to 12 months of infrastructure work that has nothing to do with the revenue problem you set out to solve. Claude Code gets you to the launchpad fast. The harness is how you actually take off without exploding on the pad. The same lesson surfaces across real Agentforce implementation timelines.
👤 The talent trap nobody prices in
Even if you accept all that, the usual next thought is "we will just hire one person to own it." The market for that person barely exists.
The role you need is a GTM engineer. They have to understand revenue process, stages, MEDDPICC (a deal-qualification method), forecast categories, and renewal motions. They also have to understand agent infrastructure, model behavior, prompt patterns, observability, and evaluation frameworks. Translating a method like the MEDDIC sales methodology into live agent logic is itself a specialist skill.
Those two skill sets almost never live in one person. RevOps folks do not speak prompts. ML engineers do not speak deal stages.
⏰ What hiring that unicorn actually costs
Time to fill: 6 to 12 months for a role this rare.
Loaded cost: $250K to $400K per year, FAANG-engineer territory.
Turnover risk: high, because they are in demand everywhere at once.
Even powerful agent platforms confirm how steep the setup and scaling curve is when you go it alone, something we cover in our analysis of Agentforce reviews:
"Setting it up wasn't as smooth as I expected. The UI felt a bit clunky at times... It's definitely not plug-and-play unless you've worked with similar AI flows before. Also, the pricing caught us off guard. Once we started scaling to more users and use cases, the cost ramped up pretty quickly." Verified User Salesforce Agentforce G2 Verified Review
"Gong is solving... insight into the actual voice of the customer. The downside, AI training is a bit laborious to get it to do what you want." Trafford J., Senior Director, Revenue Enablement Gong G2 Verified Review
I could be off on the exact salary band, but the direction is not in question: the harness plus the operator is where most six-month builds quietly stall.
This is where a service layer beats a hire. At Oliv, we ship the production harness, the guardrails, permissions, monitoring, and audit, along with GTM-engineering expertise as a service, so you skip the infrastructure project and the unicorn search at the same time.
Q5. What do the token economics of RAG vs synthesis-first actually look like at scale? [toc=5. Token Cost Reality]
With RAG, retrieval-augmented generation, every query is a fresh retrieval-plus-reasoning pass, so cost scales with both usage and reasoning depth. A 50-rep team running 10,000 complex queries a week can burn $5K to $15K weekly in tokens alone. Synthesis-first flips it. Heavy compute runs once when activity arrives, and later queries are cheap reads against pre-computed state, so cost flattens with usage. Small language models, around 20 to 30 billion parameters, sharpen this further as cost-effective specialists.
💸 Why RAG cost climbs with usage
Let me be precise, because this is where the architecture decision gets real. With RAG, each question triggers a fresh retrieval pass plus a fresh reasoning pass.
That means cost scales on two axes at once: how many queries you run, and how deep the reasoning has to go. A shallow lookup is cheap. A "what is really happening on this deal" question is not, which is why AI sales forecasting software has to be built around deep deal context.
The deeper the synthesis, the more tokens you burn every single time someone asks. Nothing gets reused.
⏰ The worked math on a real team
Here is a checkable example, so you do not have to take my word for it. Picture 50 reps, each managing 20 deals, asking 10 questions per deal per week.
At realistic RAG pricing for deep queries, that lands around $5K to $15K per week in tokens alone.
That is before salaries, hosting, or monitoring.
RAG token costs bend sharply upward with usage, while a synthesis-first architecture keeps them flat.
Run the numbers against your own seat count and query volume. The point is not the exact figure, it is the shape of the curve. It bends upward as you grow.
⭐ How synthesis-first flattens the curve
Synthesis-first inverts when the expensive work happens. You do the heavy reasoning once, the moment activity arrives, and store the result as a continuously updated semantic view.
Later queries become cheap reads against that pre-computed state, not fresh reasoning passes. So as usage climbs, cost flattens instead of spiking. The synthesis cost is amortized across every future question, an architectural edge we explore across the revenue intelligence platforms we track.
This is also where small language models earn their place. A 20-to-30-billion-parameter model, fine-tuned for one narrow job, can extract a specific signal far cheaper than routing everything through a frontier model. To be clear, RAG is the right tool for many problems. It is just the wrong default for revenue synthesis at scale.
At Oliv, our 100-plus fine-tuned models are this synthesis-first approach in production: heavy compute once as signals land, cheap reads after, grounded in your own secure data workspace.
Q6. What actually happens when a smart team tries to build it themselves? [toc=6. When Build Fails]
A mid-market customer-data company ripped out Gainsight and built its own customer-success stack: Braze for messaging, Mixmax for sequencing, Google Sheets for tracking, and a custom ChatGPT for QBR decks. Each tool worked alone. None talked to each other, and the integration glue was a CSM copying between browser tabs. When leadership mandated end-to-end automation, the stack could not deliver, because the connecting tissue was a human. The build was not wrong in 2023. The market moved underneath it.
🏗️ The situation: a smart, self-built stack
A few quarters back, I sat with a customer-success team at a mid-market customer-data company. They had dropped Gainsight years earlier and built their own stack instead.
It was a reasonable build. Braze handled messaging, Mixmax ran email sequences, Google Sheets tracked accounts, and a custom ChatGPT drafted QBR decks and customer comms. Each piece did its job.
⚠️ The complication: the glue was a person
Here is where it cracked. None of those tools talked to each other. The connecting tissue, the thing that moved data from one to the next, was a CSM copying between browser tabs.
Then leadership mandated end-to-end CS automation. The team realized their stack could not be automated, because the integration layer was a human in tabs, not software.
They ran the real math: Braze plus Mixmax plus ChatGPT tokens, plus the hours of CSM glue work. The number surprised them in both directions. A modern platform came out cheaper and more capable, the same gap we see when comparing revenue orchestration platform tools.
This is the same fragmentation operators describe inside legacy tools, where the human is still doing the stitching, a frustration echoed across Clari alternatives:
"Clari is a tool for sales leaders, it adds no value to reps as far as I can see." u/Msoave, r/SalesOperations Reddit Thread
"It is really just a glorified SFDC overlay... I think it can be useful if you have a complex GTM motion but definitely overkill for most companies." u/conaldinho11, r/SalesOperations Reddit Thread
✅ The resolution: a 2023 stack in a 2026 world
I want to be fair to that team. They made good decisions with the information they had in 2023. The build was not a mistake at the time.
The market simply moved underneath them. What they had was a 2023 stack living in a 2026 world, held together by a person clicking between tabs.
The team did not need another tool to glue together. They needed the glue itself to be the product, which is exactly what a Gen-3 agentic platform like Oliv is built to be.
Q7. How do you decide for your own team, the five questions to ask? [toc=7. The Decision Framework]
Ask five honest questions. One, what is the expected annual value: under $20K, build; over $50K, buy. Two, do you have a GTM engineer, or can you hire one in 90 days? Three, is this a synthesis problem or a retrieval problem? Four, will it need to survive an audit? Five, what is your actual core competency, revenue or AI infrastructure? For most readers, two or three answers lean build and two or three lean buy. The point is not to flip you, it is to make you ask the right questions.
✅ The five checks, with real thresholds
By the end of this, you will have a framework you can hand to your CFO or your lead engineer. Five questions, each a genuine check, not a rigged one.
Build vs Buy: A Five-Question Decision Test
Question
Leans build
Leans buy
1. Expected annual value?
Under $20K
Over $50K
2. GTM engineer on staff or hireable in 90 days?
Yes
No
3. Synthesis or retrieval problem?
Retrieval (summaries)
Synthesis (reasoning across months)
4. Must it survive an audit?
No
Yes
5. Core competency?
AI infrastructure
Revenue
Walk each one honestly. If you mostly summarize calls, retrieval is fine and a build is reasonable. If you need to reason across six months of deal activity, that is synthesis, and a DIY build gets expensive fast. Matching the problem to the right tool is the same exercise behind picking the best sales intelligence platform.
⚠️ The honest read of your score
Here is what I will not pretend. For most readers, two or three answers lean build and two or three lean buy. That split is normal, and it is the point.
I am not trying to flip every answer to buy. I am trying to make sure you ask the right five questions before you commit a quarter of engineering time. The audit question alone catches teams off guard, because permissions, monitoring, and audit logs are a separate six-month project, a reality we cover in our implementation timeline breakdown.
If your answers lean buy, you do not have to buy a whole suite on day one. The cheapest next experiment is a single-use-case pilot. Oliv starts at $19 per user and adds agents one at a time, so you can validate the buy path for roughly the cost of an engineer-hour.
Q8. If you are going to keep building, when should you come back and buy instead? [toc=8. When You Hit the Wall]
Many readers will keep building, and that is fine. Come back when context windows blow up, when the GTM engineer leaves, or when the CFO asks why the project is still running. Oliv is not a different way to build the same thing. It is the application layer already built so you do not have to: the Context Graph for synthesis, the agent harness for production, and GTM engineering as a service. When you hit the wall, you will know where to look.
📌 The three moments to bookmark this
I am not going to pretend everyone reading this will buy. A lot of you will keep building, and honestly, that can be the right call for where you are today.
So let me just leave a marker. Come back to this page at one of three moments.
When your context windows blow up and synthesis gets too slow or too expensive.
When your one GTM engineer leaves, and the build leaves with them.
When your CFO asks why this project is still running two quarters in.
⭐ What the application layer already solves
When that moment comes, here is the shift in how I think about it. Oliv is not a smarter way to build the same thing yourself. It is the application layer that has already been built, so you do not have to, much like the shift we map from revenue ops to intelligence to orchestration.
Three pieces map directly to the three walls most builds hit. The Context Graph handles synthesis, the agent harness handles production guardrails, permissions, and monitoring, and GTM engineering comes as a service so you skip the unicorn hire. If you are weighing this against incumbents, our Agentforce alternatives guide is a fair place to start.
We are here when you hit the wall, not to tell you "I told you so." If you are curious now, see how the Context Graph handles synthesis across 100-plus signals per deal in a 7-minute walkthrough with the founder.
References [toc=9. References]
Salesforce. Company history and founding (1999). Foundational context for the year-2000 application-layer pattern, cited as a historical anchor, not a recent source.
NetSuite. Company history and founding (1998). Foundational context for the in-house ERP-to-SaaS migration wave.
NotebookLM build-versus-buy brief. "Year 2000 cycle, real cost math, the $20K threshold, the three traps, token economics, the self-built CS-stack composite, the five-question framework, and the soft-close triggers." First-party brief, 2026.
Anthropic. "Claude API pricing and documentation." Last updated: 2026.
Oliv AI. "Brand messaging guidelines, product overview, and pricing." Vendor documentation. Last updated: April 2026.
FAQ's
Is building your own revenue AI in 2026 a smart move or a repeat of past mistakes?
We think it is a rational move with a real expiration date. In 2000, Oracle databases existed but Salesforce, Workday, and NetSuite did not, so companies built their own CRMs, ERPs, and HR systems in-house. Most were quietly retired within five years once the application layer matured.
AI today sits in the same spot. The foundation models are powerful and cheap to call, but the application layer for revenue teams is still young. Building right now can be completely rational.
The honest risk is timing. A build that makes sense in 2026 can age into a 2023-shaped liability by 2028, exactly like those year-2000 ERPs. We map this same arc in our breakdown of how revenue ops evolved into orchestration.
Building is the correct read of where the technology sits today.
The question is not whether to build, but whether what you build survives the next two years.
What does building revenue AI actually cost compared to buying a platform?
We always start with the honest threshold. Below about $20K of expected annual value, building is genuinely cheaper. Above $50K, buying compounds in your favor and is rarely close.
A realistic build is not just an API call. It runs 1 to 2 engineers for 3 to 9 months, roughly $80K to $200K loaded, plus 20% to 30% of that yearly in maintenance, plus $10K to $30K in hosting and observability, plus production-scale token costs that grow with usage.
Buying a mid-market platform typically runs $20K to $50K a year, with maintenance, hosting, and tokens included. The cost most buyers forget is opportunity cost: engineer time on this build is time not spent on the product you actually sell.
Build: frequently $150K+ in year one.
Buy: usually $20K to $50K per year.
We price for exactly this math. Our plans are modular and seat-based, and you can compare the wider market in our guide to the best AI sales tools.
Why does a Claude plus RAG build over our CRM break in production?
We see this build constantly, and it demos beautifully before it breaks. RAG, retrieval-augmented generation, grabs relevant chunks at query time and hands them to the model. That works for shallow tasks like summarizing a call.
It collapses on synthesis. Ask what the real risk is on a deal across six months of activity and a dozen stakeholders, and the system must reason from scratch every time. At scale, that means thousands of dollars and real minutes per complex query.
It fails worst on exactly the long, multi-threaded deals you most need help with. The fix is architectural: pre-compute synthesis as activity arrives, so query time becomes a cheap read.
RAG is right for retrieval, wrong for revenue synthesis at scale.
Around 2018, Gong won by pre-computing deal signals, not by a smarter algorithm.
We unpack the limits of that older approach in our look at Gong forecasting, and our Context Graph applies the same idea to semantic signals.
What do the token economics of RAG versus synthesis-first look like at scale?
We like this question because the math is checkable. With RAG, every query is a fresh retrieval-plus-reasoning pass, so cost scales with both usage and reasoning depth.
Picture 50 reps, each managing 20 deals, asking 10 questions per deal each week. That is 10,000 complex queries weekly, which can burn $5K to $15K per week in tokens alone, before salaries or hosting.
Synthesis-first flips it. Heavy compute runs once when activity arrives, and later queries are cheap reads against pre-computed state, so cost flattens as usage grows. Small language models, around 20 to 30 billion parameters, sharpen this further as cost-effective specialists.
RAG cost bends upward as you scale.
Synthesis-first amortizes the heavy work across every future question.
Our 100-plus fine-tuned models are this approach in production, and you can see how it fits the wider category in our roundup of revenue intelligence platforms.
Who can actually build and run a production revenue AI agent in-house?
We find this is the trap nobody prices in. A prototype runs on a laptop and breaks when the schema changes. A production agent needs guardrails, permissions, monitoring, memory management, audit trails, and hallucination handling, each its own project.
Running it needs a GTM engineer who understands both deal stages and agent infrastructure. That person has to speak MEDDPICC and forecast categories on one side, and prompts, observability, and evaluation frameworks on the other.
Those two skill sets almost never live in one person. RevOps folks do not speak prompts, and ML engineers do not speak deal stages.
Time to fill: 6 to 12 months.
Loaded cost: $250K to $400K per year.
Turnover risk: high, because they are in demand everywhere.
Translating a method like the MEDDIC sales methodology into live agent logic is itself a specialist skill, which is why we offer GTM engineering as a service.
How do I decide between build and buy for my own revenue team?
We hand readers five honest questions, not a rigged conclusion. One, what is the expected annual value: under $20K leans build, over $50K leans buy. Two, do you have a GTM engineer, or can you hire one in 90 days?
Three, is this a synthesis problem or a retrieval problem? Four, will it need to survive an audit? Five, what is your actual core competency, revenue or AI infrastructure?
For most readers, two or three answers lean build and two or three lean buy. That split is normal, and it is the point. We are not trying to flip every answer, just to make sure you ask the right ones before committing a quarter of engineering time.
If your answers lean buy, a single-use-case pilot is the cheapest next experiment.
If we keep building, when should we come back and buy instead?
We think many readers will keep building, and that is fine. The job here is to leave a marker for the moment the build stalls.
Come back at one of three moments: when context windows blow up and synthesis gets too slow or expensive, when your one GTM engineer leaves and the build leaves with them, or when your CFO asks why the project is still running two quarters in.
At that point, the shift is simple. A modern platform is not a smarter way to build the same thing yourself. It is the application layer already built, so you do not have to.
Context Graph handles synthesis.
The agent harness handles production guardrails and monitoring.
GTM engineering comes as a service, so you skip the unicorn hire.
If you are weighing this against incumbents, our Agentforce alternatives guide is a fair place to start.
Enjoyed the read? Join our founder for a quick 7-minute chat — no pitch, just a real conversation on how we’re rethinking RevOps with AI.
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields, all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions

.avif)
.png)









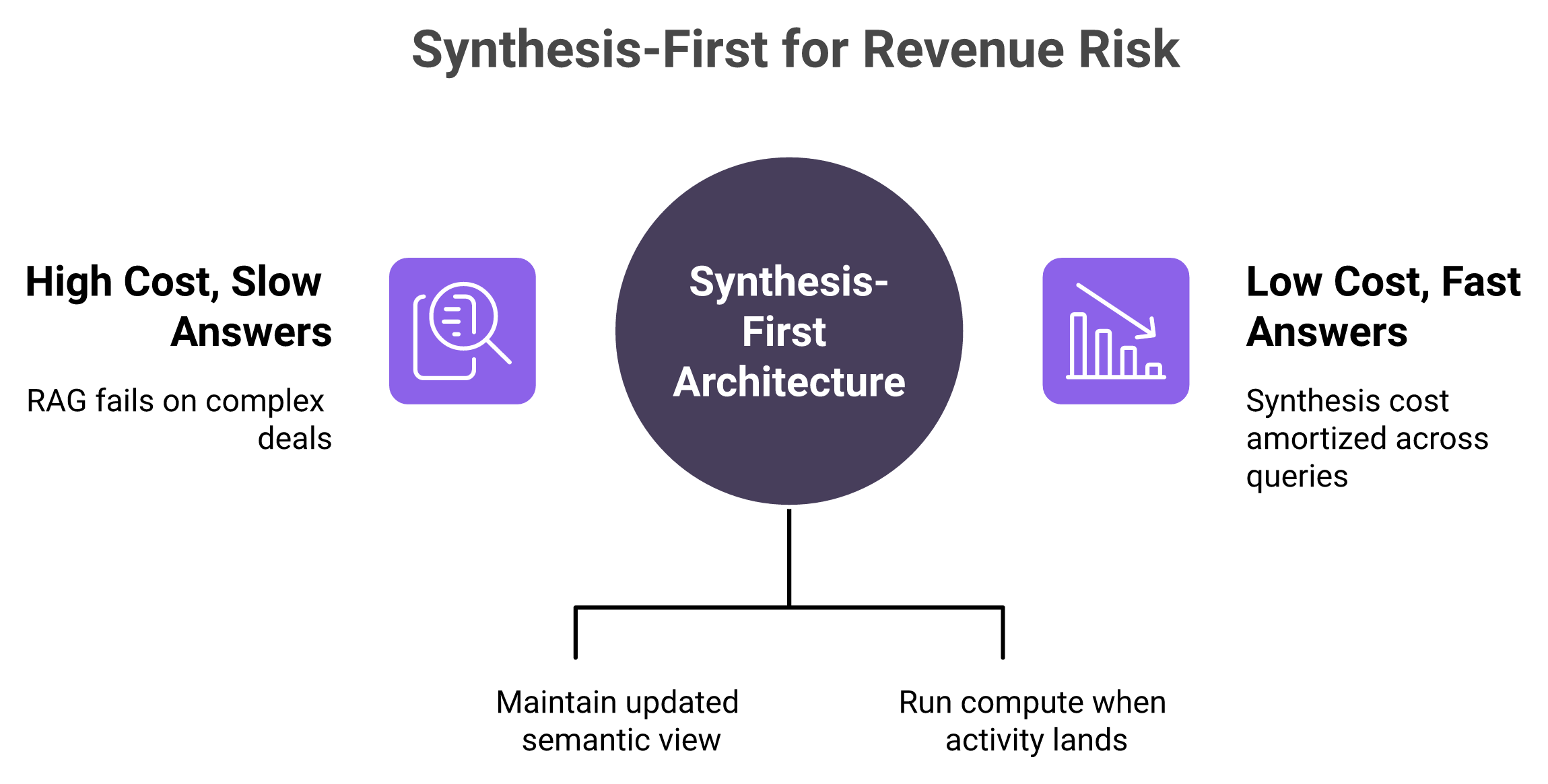

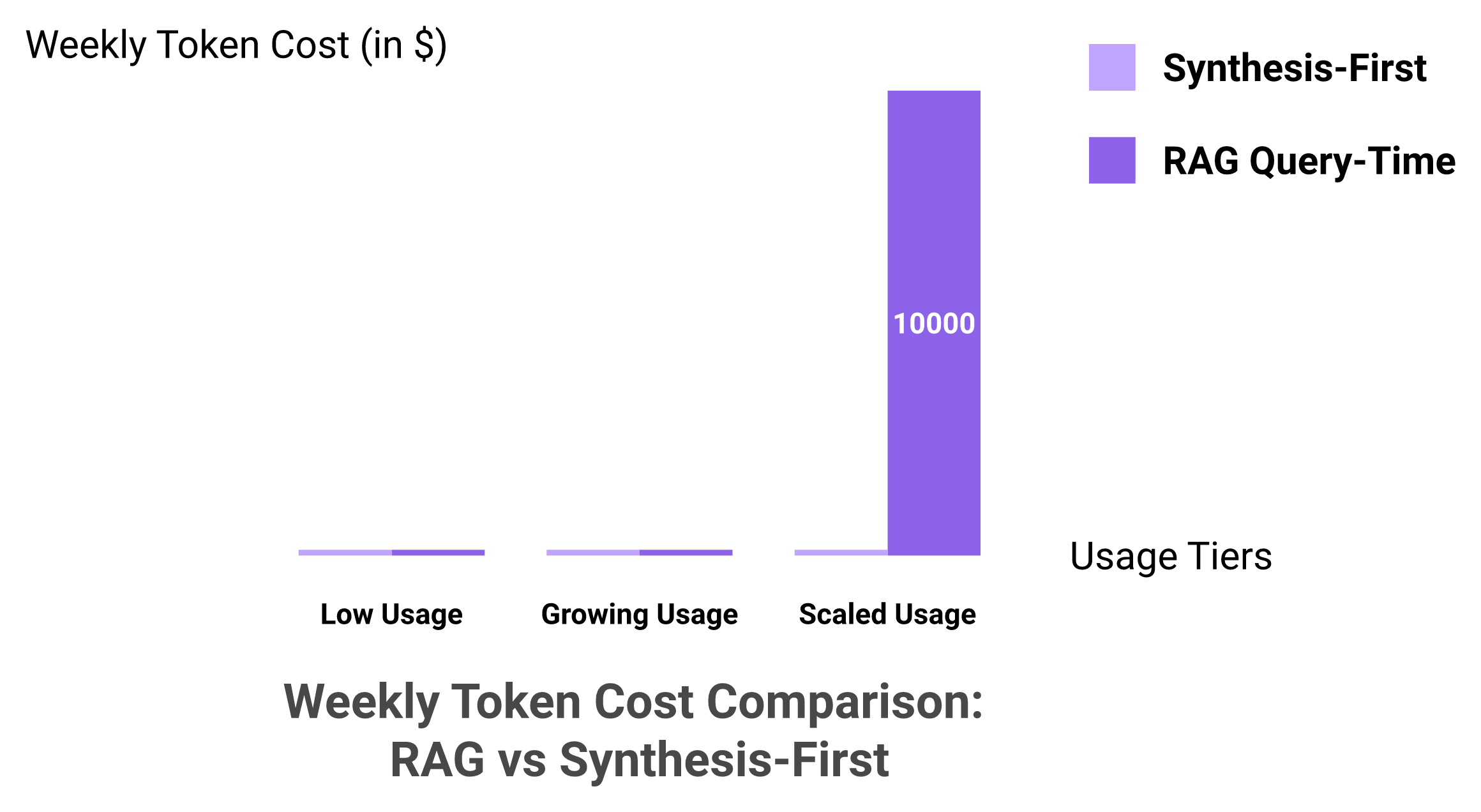

.png)
.png)
.png)


