AI Agents for RevOps: How Forecasting, Lead Routing, Deal Scoring, and CRM Hygiene Agents Compare for B2B SaaS Revenue Teams
Written by
Ishan Chhabra
Last Updated :
June 22, 2026
Skim in :
7
mins
In this article
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions
TL;DR
AI agents for RevOps execute multi-step revenue work autonomously, unlike copilots that wait for prompts or note-takers that only transcribe calls.
The five core agents (forecasting, lead routing, deal scoring, CRM hygiene, renewal) differ most on autonomy and revenue risk.
CRM hygiene and lead routing save 15 to 20 hours weekly and are the safest, reversible first pilots to run.
AI forecasting agents cut variance from 30 to 40 percent down to under 10 percent and kill the weekly forecast scrub.
Most mid-market teams should buy, not build, since in-house GTM agents go obsolete in months without dedicated engineers.
Trustworthy agentic RevOps runs on bounded autonomy: auto-run low-risk work, gate anything touching pricing or reported numbers.
Q1. What are AI agents for RevOps, and how are they different from copilots, note-takers, and dashboards? [toc=1. What Are RevOps AI Agents]
A RevOps lead at a 90-rep SaaS company once showed me her Monday stack. Eleven tabs open. Gong on one, Salesforce on another, a Clari forecast view, two spreadsheets, and a note-taker that had faithfully transcribed forty calls she had no time to read. "I have all the data," she said. "I just have no time to act on it." That gap, between knowing and doing, is exactly where AI agents for RevOps live.
AI agents for RevOps are autonomous software systems that don't just suggest, they execute multi-step revenue work like cleaning CRM records, scoring deals, routing leads, and drafting forecasts, then learn from your corrections. Unlike copilots that wait for prompts or note-takers that only transcribe, agents pursue a goal, re-plan when blocked, and run overnight. Think smart employee, not vending machine.
🤖 Agent vs copilot vs note-taker vs dashboard
Here is the cleanest way I've found to explain the difference to a busy operator.
Only an agent owns a goal end to end, which is what separates true AI agents for RevOps from copilots and note-takers.
Dashboard: shows you what happened. You read it, you decide, you act.
Note-taker: records what was said on a call. It captures, it does not act.
Copilot: answers when asked. You prompt it, it drafts, you still ship the work.
Agent: owns a goal end to end. It pulls context, takes the next step, and asks for help only when it hits a wall.
The analogy I keep coming back to is the vending machine. Traditional automation is a vending machine, fixed input, fixed output, and it breaks the second the payment fails. An agent is more like a coach or a smart employee. It picks a goal, junks the plan if it isn't working, improvises if it is, and goes relentlessly after the outcome.
⚠️ Why most "AI tools" are still just note-takers
Here's the part the category avoids saying out loud. Most companies shipping "AI for sales" built their own note-taker, and many of them stall six or seven months in, still working as note-takers only.
I think we're sitting at a real inflection point. The landscape is moving from chat to agents, and the teams genuinely using agents, not chatbots, report being far more productive in a day's work. I could be slightly off on the exact multiple people quote, but the direction is not in question from what I see inside live revenue teams.
✅ What changes on Monday
The payoff is simple. With a true agent, CRM hygiene runs overnight, stale deals get flagged before your forecast call, and a follow-up draft is waiting before you've finished your coffee. You move from reading dashboards to reviewing decisions.
This is the line we drew when building Oliv. Agentic platforms like deal-level revenue intelligence platforms operate at the deal level, tracking the entire sales cycle rather than transcribing a single meeting, which is precisely what separates an agent from a note-taker. When we rebuilt our own pipeline reviews on Oliv agents, the work shifted from gathering context to checking the agent's judgment, and that's the shift worth chasing.
Q2. Why are traditional RevOps stacks breaking under "manual context-stitching"? [toc=2. The Context-Stitching Problem]
Picture an AE who needs to send one good follow-up. The real workflow looks like this: pull the transcript from Gong, paste it into ChatGPT, write a prompt, paste the output into Outlook, then go hunt for the right PDF to attach. It's so much work that most people just don't do it. That, in one scene, is the disease I call manual context-stitching, and it's quietly breaking RevOps stacks everywhere.
RevOps stacks break because every new tool adds another silo a human must reconcile by hand. You pull a transcript from one app, context from the CRM, a deck from a third, then stitch it together yourself. More technology creates more brittleness, not less. The fix isn't another dashboard. It's an agent that reads across systems and acts.
Manual context-stitching forces reps to reconcile disconnected silos by hand, which is exactly what agents are meant to eliminate.
🔌 The resilience paradox
The standard read says the answer to messy revenue data is more tooling. I think that gets it backwards.
Most RevOps teams now spend the bulk of their week maintaining integrations and rebuilding reports that should have been automated years ago. Every tool you add to "fix visibility" becomes one more surface a human has to keep in sync. Running a growth machine this way is like driving an expensive racing car that's only firing on two cylinders.
🗃️ The CRM-as-dead-air problem
Here's a contrarian truth most vendors won't print. The CRM, as a product, has largely failed at its original promise. For most reps, it's a dumb repository they update weekly because management requires it, not because it makes them faster.
The data isn't wrong because reps are lazy. It's stale because keeping it fresh means more stitching, and stitching is the thing nobody has time for. A "15-tool stack" still can't predict pipeline accurately, because the intelligence is scattered across fifteen places no human can hold at once.
When a six-figure revenue tool gets demoted to "call recorder," that's context-stitching winning and the stack losing.
✅ Load the context, stop the stitching
The mental shift is this: context should be loaded into the agent, not stitched by the human. Your job moves from assembling the picture to approving the action.
This is the core of what we built at Oliv. Our approach to deal-level revenue intelligence collapses the stitching by analyzing at the deal level across the full cycle, so the agent, not the rep, assembles context before a follow-up is ever drafted. From what surfaces when you actually run this, the win isn't a prettier dashboard. It's the half-hour per deal you stop spending in copy-paste limbo.
Q3. How do the five RevOps agent types compare across forecasting, lead routing, deal scoring, CRM hygiene, and renewal? [toc=3. The Five Agents Compared]
Every RevOps leader I talk to wants the same thing: a straight answer on which agent to trust with the keys and which to keep on a short leash. The honest answer is that they're not equal, and treating them as one "AI rollout" is how pilots stall. The five core RevOps agents differ most on autonomy and risk.
CRM hygiene and lead routing run near-autonomously and save the most hours, often 15 to 20 a week. Forecasting and deal scoring need human review because they shape revenue calls. Renewal agents sit in between, scoring churn risk for CS. The rule is simple: match autonomy to revenue risk. Auto-run low-stakes data work, keep humans on anything that touches a reported number.
🎂 The three-layer scoring lens
Before the table, here's the frame I use. Think of any agent as reaching across three layers: a baseline data layer (recording and transcription, now basically commoditized and should be cheap), an intelligence layer (tracking qualification fields and deal health), and an agent layer (shipping proactive reports and actions). The further up an agent reaches, the more value, and the more oversight it needs.
📊 The five agents compared
RevOps Agents: Autonomy, Guardrails, and Mid-Market Fit
Agent type
Integration depth
Autonomy level
Governance guardrail
Time saved
Mid-market fit
CRM hygiene
Deep (writes to CRM)
High, near-autonomous
Auto-run, log every change
15 to 20 hrs/week
⭐ Pilot first
Lead routing
Deep (CRM + SLA rules)
High, near-autonomous
Auto-run, alert on exceptions
High
⭐ Strong
Deal scoring
Medium (intelligence layer)
Medium, recommends
Human reviews flags
Medium
Strong
Forecasting
Deep (full deal cycle)
Medium, drafts the call
Human approves the number
High
⭐ High value
Renewal / churn
Medium (CS + usage data)
Medium, scores risk
CS confirms before action
Medium
Growing
🎯 Pilot-first guidance
CRM hygiene: start here if duplicate accounts and stale fields are skewing every report.
Lead routing: pick this if leads sit unassigned past your SLA.
Deal scoring: add once your data is clean enough to trust the signal.
Forecasting: prioritize if your Monday call runs on stale slides.
Renewal: layer in when CS is reacting to churn instead of predicting it.
What real buyers report lines up with this risk ladder. Forecasting and data access are where the friction shows, and a closer look at how forecasting tools handle data makes the pattern clear:
"While Gong offers valuable insights into call data... our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export capabilities." Neel P., Sales Operations Manager Gong G2 Verified Review
"Some users may find Clari's analytics and forecasting tools complex, requiring significant onboarding and training." Bharat K., Revenue Operations Manager Clari G2 Verified Review
Where most point tools cover a single column, our deal-level forecasting model spans the intelligence and agent layers across forecasting, scoring, and hygiene from one model. In our work with mid-market RevOps teams, the value isn't owning one row of that table, it's that the same context feeds all of them, so a clean record improves the forecast and the renewal score at the same time.
Q4. How accurate are AI forecasting agents, and what time do they actually save? [toc=4. Forecasting Agents & ROI]
Every Thursday and Friday across thousands of B2B SaaS teams, the same ritual plays out. Managers sit with each rep for one to two hours to understand what moved in the pipeline, then manually key that into a forecast and build the report they'll show on Monday. By Monday, the numbers are already a few days stale. That scrub is the single most expensive recurring meeting in revenue, and it's the first thing a forecasting agent kills.
AI forecasting agents cut forecast variance from a typical 30 to 40 percent down to under 10 percent, against Gartner's "healthy" benchmark of 85 percent or higher accuracy. The bigger win is time. Managers reclaim that weekly scrub because the agent pulls live pipeline movement instead of waiting for the slide deck. The rule of thumb: if a rep can't articulate deal status, push it off the forecast.
📈 What the numbers actually say
Let me ground the claim in primary data, because operators rightly screenshot weak stats and roast them.
Variance: integrated AI forecasting moves variance from the common 30 to 40 percent range to under 10 percent.
Baseline: Gartner treats 85 percent or higher as a healthy forecast-accuracy mark, with 90 percent plus for highly disciplined orgs.
Cycle time and quota: LinkedIn's research found 69 percent of sellers using AI cut their sales cycle by about a week, and daily AI users are twice as likely to exceed targets.
I'll add one honest hedge. These lifts assume clean inputs. Forecasting is a RevOps problem before it's a sales-discipline problem, because no agent rescues a forecast built on stale stages and ghost deals.
⏰ The "push it off the forecast" discipline
Here's the Monday-morning move worth stealing. If you've exhausted your qualifying questions and a rep still can't articulate exactly where a deal stands, tell them to remove it from the forecast. An agent makes this enforceable, flagging any commit-stage deal with no logged activity, so the discipline runs automatically instead of depending on a manager's memory.
The friction with legacy tools is usually delay and trust, not raw capability, a theme that runs through honest accounts of Gong forecasting in the wild:
"Gong's deal forecasting we don't use... there's so much in Gong, that we don't use everything." Karel Bos, Head of Sales Gong TrustRadius Verified Review
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit." Dexter L., Customer Success Executive Clari G2 Verified Review
When forecasting features go unused or still need a manual calculator, the time-saving promise quietly evaporates.
This is where speed matters more than people expect. Our deal-level forecasting agent updates within about five minutes of a call and tracks pipeline movement continuously, versus the 20 to 30 minute delay common in legacy tools, so Monday's forecast is built from live reality, not a Thursday memory. From what surfaces when you actually run a forecast call this way, the debate stops being "is the number right" and starts being "what do we do about it."
Q5. Do CRM hygiene and lead routing agents really save 15 to 20 hours a week? [toc=5. Hygiene & Routing Agents]
Walk into any mid-market RevOps team on a quarter-end Friday and you'll find someone hand-merging duplicate Salesforce accounts at 7 PM. That person isn't strategic. They're a data janitor. And the worst part is that next quarter the same duplicates come back, because the cleanup was manual.
Yes, CRM hygiene agents save RevOps teams a documented 15 to 20 hours a week by auto-deduping, enriching, and flagging stale records, while routing agents cut hours of manual assignment and SLA-chasing. They're the safest first pilots because errors are low-stakes and reversible. The catch: agents amplify bad data, so hygiene must come before scoring or forecasting.
⚠️ Why rule-based capture keeps breaking
Old automation follows rigid rules, and revenue data is anything but rigid. Two patterns break it every time.
The first is over-redaction. Einstein activity capture, for example, can flag a normal email as "sensitive" and hide it, even when it isn't, so you never build a complete customer picture. The second is duplicate accounts. Simple rule-based logic has no clean way to decide what happens when it sees two records for the same company.
"It can be complex to set up and often requires skilled administrators or developers to customize and integrate properly, which adds time and cost." Verified User in Marketing Salesforce Agentforce G2 Verified Review
Here's the sequence I'd run, and I'll hedge it: order matters more than speed.
Dedupe and flag stale records first. Clean the foundation so every later agent inherits good data. ✅
Turn on routing and SLA enforcement next. Auto-assign leads and ping when an SLA, your agreed response-time rule, slips. ⏰
Only then add scoring or forecasting. These depend on clean inputs, so they go last. 💰
One warning from the field. If your systems are messy, automation amplifies the mess. A bad "Hello {First_Name}" merge field doesn't save time, it broadcasts the problem to every prospect.
Because our deal-level platform builds a complete, deal-level customer picture, hygiene agents work from clean context instead of redacted or duplicated records, which is exactly the failure mode rule-based capture hits. From what surfaces when you actually run this, the hours saved are real, but the bigger win is that the cleanup finally stops coming back.
Q6. How do deal scoring and renewal/churn agents protect pipeline and revenue? [toc=6. Deal Scoring & Renewal Agents]
A CS lead once told me she found out about a churn three days before the renewal date. The usage had been dropping for two months. The signal was sitting in the product analytics the whole time. Nobody was watching, because watching by hand across 200 accounts is impossible.
Deal scoring agents grade pipeline health continuously, flagging stalled or low-activity deals before they skew the forecast, while renewal agents score churn risk early, giving CS a 90-day window instead of a two-week scramble. A working churn model is simple: a query-volume drop greater than 50 percent adds 25 risk points, and zero queries for seven straight days adds 30 plus. Both turn signals into action, not dashboards.
🔍 How deal scoring reads pipeline health
Deal scoring means grading each open deal on how likely it is to close, using activity, not gut feel. The agent watches the boring signals a human forgets to check.
No logged activity in 14 days? Flagged. Single-threaded with one contact? Flagged. Pushed close date twice? Flagged. Automated hygiene like this catches stale deals before they quietly inflate your forecast.
🧮 A churn model you can copy
Here's the worked example, kept transparent on purpose. A black-box "risk score" is useless if CS can't see why an account is red.
Query volume drops more than 50 percent: +25 points ⚠️
Zero queries for 7 consecutive days: +30 points ❌
Add your own signals (no QBR booked, champion left): +X points
Cross a threshold, and the account surfaces as an action, not a chart. This is the difference between a vending machine and a coach. The agent re-prioritizes the at-risk account on its own and tells CS where to spend the week.
"Not great at forcasting, We just keep playing hot potato with vendors and it can be frustrating." Justin S., Senior Marketing Operations Specialist Chorus by ZoomInfo G2 Verified Review
"I find the AI call scoring to be gimicky and provides little value." Miles W., Senior Manager Customer Success Avoma G2 Verified Review
That second quote is the honest risk. Scoring is only useful when it's tied to live deal context, not bolted onto a transcript.
Our deal-level model scores both pipeline health and renewal risk from the same context, so a stalled deal and an at-risk account surface as actions, not just red cells on a dashboard. In our work across B2B sales cycles, the accounts you save are almost always the ones a 90-day signal caught early.
Q7. Agentforce vs Gong vs deal-level agents: which RevOps tools are actually agentic? [toc=7. Vendor Reality Check]
"Has anyone actually tried Agentforce? Is it even working for you? Are you seeing any ROI?" I see some version of that question in RevOps communities every week. It's the right question, because the word "agent" is doing a lot of marketing work right now that the products don't always back up.
Agentforce is strong at the data-fabric layer but largely chat-driven. A rep still has to go talk to the agent and move the output elsewhere. Gong understands conversations at the meeting level, while deal-level agents like Oliv.ai understand the entire cycle, including pipeline movement and forecasting. Since recording is now commoditized by Zoom and Teams, the value has moved up to the agent layer.
🤔 Chat-driven is not the same as agentic
Here's the contrarian read, said plainly. Many "agents" today are still chat-focused, not deeply woven into your workflows. You ask, it answers, you copy-paste. That's a smarter chatbot, not an autonomous teammate.
"Lots of clicking to get select the right options. UX needs improvement. Everything opens in a new browser tab." Verified User in Consulting Salesforce Agentforce G2 Verified Review
"Gong's lack of open task APIs limits system integration, making it difficult to connect with other essential tools." Verified User Gong G2 Verified Review
⭐ Which to choose, honestly
To be fair to the incumbents: Agentforce genuinely owns the Salesforce data fabric, and Gong's call-coaching depth is still excellent. Choose Gong if conversation intelligence is your core need. Choose Agentforce if you're deeply committed to Salesforce and have admin muscle.
Choose a deal-level agent like our deal-level revenue platform if your pain is the whole cycle, forecasting, pipeline movement, and follow-up, not just the call. The pilot trap is real: many deployments start full of promise and fade before production, so test in your own workflow before you commit budget.
Q8. What governance guardrails and autonomy levels keep agentic revenue work trustworthy? [toc=8. Governance & Autonomy Tiers]
The first time we let agents run loose on outbound, we learned something uncomfortable. One teammate had to spend 10 to 15 hours a week reviewing the outputs, because the agents work all night, every night. Autonomy without guardrails doesn't remove work. It just moves it.
Trustworthy agentic RevOps runs on bounded autonomy. Agents auto-execute low-risk work like dedupe, enrich, and route, draft medium-risk work for one-click approval like emails and forecast updates, and stay blocked from pricing, legal terms, and customer commitments. Around 73 percent of orgs already run AI in core GTM workflows, and the ones succeeding govern it with clear approval tiers, not blind trust.
⚖️ Pillar one: match autonomy to revenue risk
The governing idea is simple. The more a task touches money you'll report, the more a human stays in the loop.
Bounded autonomy keeps agentic RevOps trustworthy by matching how much freedom an agent gets to how much revenue risk a task carries.
Auto-run (low risk): data hygiene, enrichment, and lead routing. ✅
Draft for approval (medium risk): follow-up emails, and forecast updates. ⏰
Blocked (high risk): pricing, contract terms, and customer commitments. ❌
🧑💻 Pillar two: someone still reviews
Here's the honest "what we got wrong" moment. Agents that never sleep create a new review burden, and it's not a job for lazy people. The fix is a rhythm, not blind faith.
I lean on the 10/80/10 rule. Humans own the first 10 percent (the idea and the taste) and the last 10 percent (the quality check). The agent owns the 80 percent of heavy lifting in between. Pair that with a 30-day correction habit, where you spend an hour or two fixing the agent's mistakes daily, and by day 30 the output is genuinely good.
"Effectively crafting prompts and configuring the underlying actions demands a specific skill set often called prompt engineering." Alessandro N., Salesforce Administrator Salesforce Agentforce G2 Verified Review
"It still needs some serious debugging... could not get past an error when I clicked Create." Jessica C., Senior Business Analyst Salesforce Agentforce G2 Verified Review
🛡️ Pillar three: governance is now a buying criterion
Buyers increasingly screen for SOC 2 (a security audit standard), GDPR and CCPA (data-privacy laws), two-party consent for recording, and the EU AI Act's rules on autonomous agents. These aren't legal footnotes anymore. They decide which vendor clears procurement.
Our agentic revenue approach ships agent outputs as reviewable, deal-level one-pagers, so the human review tier the 10/80/10 rule requires is built in rather than bolted on. I could be early on this, but where my head is right now is that governance, not raw capability, becomes the real moat in the next two years.
Q9. Should mid-market B2B SaaS teams build their own RevOps agents or buy them? [toc=9. Build vs Buy]
A founder I respect once bragged to me that he was a top 1 percent Replit user, having shipped 12 internal apps in 150 days. Then he dropped the line that stuck with me. None of the go-to-market stuff, he said, did they build themselves. The guy who could build anything chose not to build this.
For most mid-market B2B SaaS teams, buy, don't build. Even top builders warn against building GTM agents in-house, because without dedicated go-to-market engineers they go obsolete in months. Build only where you have a true "zone of genius" edge. Buy the forecasting, routing, scoring, and hygiene agents that vendors already maintain and govern.
⚠️ The build scar tissue
Here's the contrarian truth the "just build it with AI" crowd skips. You're not Vercel. An internal agent build that isn't carefully maintained becomes obsolete in a couple of months as models move.
I've watched this in the wild, and it's almost funny. We did a call with a public B2B company worth over 10 billion dollars, the kind you'd assume is an AI leader. When we asked how much of their agent stack they'd built themselves, it was crickets on a call of 20 people. Nobody had done it.
💰 Build vs buy, decided on criteria
The decision isn't ideology. It's whether you have the engineering muscle and a real edge. Here's the rule of thumb I use.
Build vs Buy: Factor-by-Factor Signals
Decision factor
Build if...
Buy if...
GTM engineers
You have dedicated ones
You don't ✅
The workflow
It's your "zone of genius"
It's standard RevOps work
Maintenance
You can fund it forever
You want it to stay current ✅
Time to value
You can wait quarters
You need it this quarter
Model upgrades
You'll re-architect
Vendor handles it ✅
Operators feel the maintenance tax of even bought tools when setup runs deep, a friction that surfaces across comparisons of forecasting platforms:
"I find the setup process challenging, especially when migrating fields from Salesforce, as it can't handle formula fields directly." Josiah R., Head of Sales Operations Clari G2 Verified Review
The economics also reset the goalposts. The old target of 300,000 to 500,000 dollars of revenue per rep is giving way to 3 to 5 million per AI-leveraged rep. You don't hit that by paying engineers to maintain a forecasting bot.
A maintained, deal-level platform like our revenue intelligence platform is the buy-side answer for teams without GTM engineers, because the agents stay current as models change instead of decaying in your codebase. From what surfaces when you actually run this, the build-it dream usually ends as a maintenance bill nobody budgeted for.
Q10. Which RevOps agent should you pilot first, and how do you prove ROI in 90 days? [toc=10. 90-Day Pilot Playbook]
Here's the cheapest experiment in revenue, and almost nobody runs it. Open an incognito browser, go to your own product or process, and do everything a customer or rep does, start to finish. If you do this honestly, you're going to cry at some of what you find. Then pick the thing that made you cry the most, and go buy the agent that fixes it.
Pilot CRM hygiene first. It's low-risk, reversible, and unlocks every other agent by cleaning the data they depend on. Then layer routing, deal scoring, forecasting, and renewal. Prove ROI in 90 days by measuring hours reclaimed (15 to 20 a week on hygiene), forecast-variance drop, and cycle-time reduction.
⏰ The 90-day sequence
By the end of this, you'll have one agent in production and a number to show your board. Run it in order.
A low-risk-first 90-day pilot sequence takes teams from CRM hygiene to forecasting while building a board-ready ROI case.
Days 1 to 30, hygiene. Turn on dedupe and stale-record flagging. Expected outcome: hours reclaimed, and clean data for everything next. ✅
Days 30 to 60, routing and scoring. Auto-assign leads, and flag stalled deals. Expected outcome: faster SLA response, and fewer ghost deals. ⏰
Days 60 to 90, forecasting. Run the forecast call on live pipeline. Expected outcome: tighter variance, and a shorter Monday meeting. 💰
📊 The metrics that prove it worked
Don't measure vanity. A rep doing 300 calls to people who could never buy is a vanity metric, not progress. Track the numbers a CFO respects.
Hours reclaimed per week (target 15 to 20 on hygiene). ⭐
Forecast variance before and after the pilot.
Sales-cycle days saved (often around a week with AI).
Stalled deals caught before quarter-end.
A word on the skill that makes all this stick. The durable advantage isn't clever prompts, it's context engineering, loading the agent with everything about your business so your instructions can stay simple. Pair that with a 30-day correction habit, and the agent gets genuinely good by week four.
"Once set up and installed, Clari is very intuitive to use... it does a great job pulling in data from various sources." Rob W., Sr. Director of Revenue Operations Clari G2 Verified Review
That contrast is the whole game. Time-to-value, not feature count, decides whether a pilot reaches production. If the workflow that made you cry was forecast scrubs or follow-up stitching, that's the deal-level work our AI forecasting agents were built to run. So here's the question I'm sitting with, and I'd genuinely like your take: in two years, does the SaaS you log into quietly become the agents that work for you, turning revenue orchestration into revenue engineering? Tell me what's breaking in your pipeline right now, and I'll show you where an agent actually fits.
Q1. What are AI agents for RevOps, and how are they different from copilots, note-takers, and dashboards? [toc=1. What Are RevOps AI Agents]
A RevOps lead at a 90-rep SaaS company once showed me her Monday stack. Eleven tabs open. Gong on one, Salesforce on another, a Clari forecast view, two spreadsheets, and a note-taker that had faithfully transcribed forty calls she had no time to read. "I have all the data," she said. "I just have no time to act on it." That gap, between knowing and doing, is exactly where AI agents for RevOps live.
AI agents for RevOps are autonomous software systems that don't just suggest, they execute multi-step revenue work like cleaning CRM records, scoring deals, routing leads, and drafting forecasts, then learn from your corrections. Unlike copilots that wait for prompts or note-takers that only transcribe, agents pursue a goal, re-plan when blocked, and run overnight. Think smart employee, not vending machine.
🤖 Agent vs copilot vs note-taker vs dashboard
Here is the cleanest way I've found to explain the difference to a busy operator.
Only an agent owns a goal end to end, which is what separates true AI agents for RevOps from copilots and note-takers.
Dashboard: shows you what happened. You read it, you decide, you act.
Note-taker: records what was said on a call. It captures, it does not act.
Copilot: answers when asked. You prompt it, it drafts, you still ship the work.
Agent: owns a goal end to end. It pulls context, takes the next step, and asks for help only when it hits a wall.
The analogy I keep coming back to is the vending machine. Traditional automation is a vending machine, fixed input, fixed output, and it breaks the second the payment fails. An agent is more like a coach or a smart employee. It picks a goal, junks the plan if it isn't working, improvises if it is, and goes relentlessly after the outcome.
⚠️ Why most "AI tools" are still just note-takers
Here's the part the category avoids saying out loud. Most companies shipping "AI for sales" built their own note-taker, and many of them stall six or seven months in, still working as note-takers only.
I think we're sitting at a real inflection point. The landscape is moving from chat to agents, and the teams genuinely using agents, not chatbots, report being far more productive in a day's work. I could be slightly off on the exact multiple people quote, but the direction is not in question from what I see inside live revenue teams.
✅ What changes on Monday
The payoff is simple. With a true agent, CRM hygiene runs overnight, stale deals get flagged before your forecast call, and a follow-up draft is waiting before you've finished your coffee. You move from reading dashboards to reviewing decisions.
This is the line we drew when building Oliv. Agentic platforms like deal-level revenue intelligence platforms operate at the deal level, tracking the entire sales cycle rather than transcribing a single meeting, which is precisely what separates an agent from a note-taker. When we rebuilt our own pipeline reviews on Oliv agents, the work shifted from gathering context to checking the agent's judgment, and that's the shift worth chasing.
Q2. Why are traditional RevOps stacks breaking under "manual context-stitching"? [toc=2. The Context-Stitching Problem]
Picture an AE who needs to send one good follow-up. The real workflow looks like this: pull the transcript from Gong, paste it into ChatGPT, write a prompt, paste the output into Outlook, then go hunt for the right PDF to attach. It's so much work that most people just don't do it. That, in one scene, is the disease I call manual context-stitching, and it's quietly breaking RevOps stacks everywhere.
RevOps stacks break because every new tool adds another silo a human must reconcile by hand. You pull a transcript from one app, context from the CRM, a deck from a third, then stitch it together yourself. More technology creates more brittleness, not less. The fix isn't another dashboard. It's an agent that reads across systems and acts.
Manual context-stitching forces reps to reconcile disconnected silos by hand, which is exactly what agents are meant to eliminate.
🔌 The resilience paradox
The standard read says the answer to messy revenue data is more tooling. I think that gets it backwards.
Most RevOps teams now spend the bulk of their week maintaining integrations and rebuilding reports that should have been automated years ago. Every tool you add to "fix visibility" becomes one more surface a human has to keep in sync. Running a growth machine this way is like driving an expensive racing car that's only firing on two cylinders.
🗃️ The CRM-as-dead-air problem
Here's a contrarian truth most vendors won't print. The CRM, as a product, has largely failed at its original promise. For most reps, it's a dumb repository they update weekly because management requires it, not because it makes them faster.
The data isn't wrong because reps are lazy. It's stale because keeping it fresh means more stitching, and stitching is the thing nobody has time for. A "15-tool stack" still can't predict pipeline accurately, because the intelligence is scattered across fifteen places no human can hold at once.
When a six-figure revenue tool gets demoted to "call recorder," that's context-stitching winning and the stack losing.
✅ Load the context, stop the stitching
The mental shift is this: context should be loaded into the agent, not stitched by the human. Your job moves from assembling the picture to approving the action.
This is the core of what we built at Oliv. Our approach to deal-level revenue intelligence collapses the stitching by analyzing at the deal level across the full cycle, so the agent, not the rep, assembles context before a follow-up is ever drafted. From what surfaces when you actually run this, the win isn't a prettier dashboard. It's the half-hour per deal you stop spending in copy-paste limbo.
Q3. How do the five RevOps agent types compare across forecasting, lead routing, deal scoring, CRM hygiene, and renewal? [toc=3. The Five Agents Compared]
Every RevOps leader I talk to wants the same thing: a straight answer on which agent to trust with the keys and which to keep on a short leash. The honest answer is that they're not equal, and treating them as one "AI rollout" is how pilots stall. The five core RevOps agents differ most on autonomy and risk.
CRM hygiene and lead routing run near-autonomously and save the most hours, often 15 to 20 a week. Forecasting and deal scoring need human review because they shape revenue calls. Renewal agents sit in between, scoring churn risk for CS. The rule is simple: match autonomy to revenue risk. Auto-run low-stakes data work, keep humans on anything that touches a reported number.
🎂 The three-layer scoring lens
Before the table, here's the frame I use. Think of any agent as reaching across three layers: a baseline data layer (recording and transcription, now basically commoditized and should be cheap), an intelligence layer (tracking qualification fields and deal health), and an agent layer (shipping proactive reports and actions). The further up an agent reaches, the more value, and the more oversight it needs.
📊 The five agents compared
RevOps Agents: Autonomy, Guardrails, and Mid-Market Fit
Agent type
Integration depth
Autonomy level
Governance guardrail
Time saved
Mid-market fit
CRM hygiene
Deep (writes to CRM)
High, near-autonomous
Auto-run, log every change
15 to 20 hrs/week
⭐ Pilot first
Lead routing
Deep (CRM + SLA rules)
High, near-autonomous
Auto-run, alert on exceptions
High
⭐ Strong
Deal scoring
Medium (intelligence layer)
Medium, recommends
Human reviews flags
Medium
Strong
Forecasting
Deep (full deal cycle)
Medium, drafts the call
Human approves the number
High
⭐ High value
Renewal / churn
Medium (CS + usage data)
Medium, scores risk
CS confirms before action
Medium
Growing
🎯 Pilot-first guidance
CRM hygiene: start here if duplicate accounts and stale fields are skewing every report.
Lead routing: pick this if leads sit unassigned past your SLA.
Deal scoring: add once your data is clean enough to trust the signal.
Forecasting: prioritize if your Monday call runs on stale slides.
Renewal: layer in when CS is reacting to churn instead of predicting it.
What real buyers report lines up with this risk ladder. Forecasting and data access are where the friction shows, and a closer look at how forecasting tools handle data makes the pattern clear:
"While Gong offers valuable insights into call data... our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export capabilities." Neel P., Sales Operations Manager Gong G2 Verified Review
"Some users may find Clari's analytics and forecasting tools complex, requiring significant onboarding and training." Bharat K., Revenue Operations Manager Clari G2 Verified Review
Where most point tools cover a single column, our deal-level forecasting model spans the intelligence and agent layers across forecasting, scoring, and hygiene from one model. In our work with mid-market RevOps teams, the value isn't owning one row of that table, it's that the same context feeds all of them, so a clean record improves the forecast and the renewal score at the same time.
Q4. How accurate are AI forecasting agents, and what time do they actually save? [toc=4. Forecasting Agents & ROI]
Every Thursday and Friday across thousands of B2B SaaS teams, the same ritual plays out. Managers sit with each rep for one to two hours to understand what moved in the pipeline, then manually key that into a forecast and build the report they'll show on Monday. By Monday, the numbers are already a few days stale. That scrub is the single most expensive recurring meeting in revenue, and it's the first thing a forecasting agent kills.
AI forecasting agents cut forecast variance from a typical 30 to 40 percent down to under 10 percent, against Gartner's "healthy" benchmark of 85 percent or higher accuracy. The bigger win is time. Managers reclaim that weekly scrub because the agent pulls live pipeline movement instead of waiting for the slide deck. The rule of thumb: if a rep can't articulate deal status, push it off the forecast.
📈 What the numbers actually say
Let me ground the claim in primary data, because operators rightly screenshot weak stats and roast them.
Variance: integrated AI forecasting moves variance from the common 30 to 40 percent range to under 10 percent.
Baseline: Gartner treats 85 percent or higher as a healthy forecast-accuracy mark, with 90 percent plus for highly disciplined orgs.
Cycle time and quota: LinkedIn's research found 69 percent of sellers using AI cut their sales cycle by about a week, and daily AI users are twice as likely to exceed targets.
I'll add one honest hedge. These lifts assume clean inputs. Forecasting is a RevOps problem before it's a sales-discipline problem, because no agent rescues a forecast built on stale stages and ghost deals.
⏰ The "push it off the forecast" discipline
Here's the Monday-morning move worth stealing. If you've exhausted your qualifying questions and a rep still can't articulate exactly where a deal stands, tell them to remove it from the forecast. An agent makes this enforceable, flagging any commit-stage deal with no logged activity, so the discipline runs automatically instead of depending on a manager's memory.
The friction with legacy tools is usually delay and trust, not raw capability, a theme that runs through honest accounts of Gong forecasting in the wild:
"Gong's deal forecasting we don't use... there's so much in Gong, that we don't use everything." Karel Bos, Head of Sales Gong TrustRadius Verified Review
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit." Dexter L., Customer Success Executive Clari G2 Verified Review
When forecasting features go unused or still need a manual calculator, the time-saving promise quietly evaporates.
This is where speed matters more than people expect. Our deal-level forecasting agent updates within about five minutes of a call and tracks pipeline movement continuously, versus the 20 to 30 minute delay common in legacy tools, so Monday's forecast is built from live reality, not a Thursday memory. From what surfaces when you actually run a forecast call this way, the debate stops being "is the number right" and starts being "what do we do about it."
Q5. Do CRM hygiene and lead routing agents really save 15 to 20 hours a week? [toc=5. Hygiene & Routing Agents]
Walk into any mid-market RevOps team on a quarter-end Friday and you'll find someone hand-merging duplicate Salesforce accounts at 7 PM. That person isn't strategic. They're a data janitor. And the worst part is that next quarter the same duplicates come back, because the cleanup was manual.
Yes, CRM hygiene agents save RevOps teams a documented 15 to 20 hours a week by auto-deduping, enriching, and flagging stale records, while routing agents cut hours of manual assignment and SLA-chasing. They're the safest first pilots because errors are low-stakes and reversible. The catch: agents amplify bad data, so hygiene must come before scoring or forecasting.
⚠️ Why rule-based capture keeps breaking
Old automation follows rigid rules, and revenue data is anything but rigid. Two patterns break it every time.
The first is over-redaction. Einstein activity capture, for example, can flag a normal email as "sensitive" and hide it, even when it isn't, so you never build a complete customer picture. The second is duplicate accounts. Simple rule-based logic has no clean way to decide what happens when it sees two records for the same company.
"It can be complex to set up and often requires skilled administrators or developers to customize and integrate properly, which adds time and cost." Verified User in Marketing Salesforce Agentforce G2 Verified Review
Here's the sequence I'd run, and I'll hedge it: order matters more than speed.
Dedupe and flag stale records first. Clean the foundation so every later agent inherits good data. ✅
Turn on routing and SLA enforcement next. Auto-assign leads and ping when an SLA, your agreed response-time rule, slips. ⏰
Only then add scoring or forecasting. These depend on clean inputs, so they go last. 💰
One warning from the field. If your systems are messy, automation amplifies the mess. A bad "Hello {First_Name}" merge field doesn't save time, it broadcasts the problem to every prospect.
Because our deal-level platform builds a complete, deal-level customer picture, hygiene agents work from clean context instead of redacted or duplicated records, which is exactly the failure mode rule-based capture hits. From what surfaces when you actually run this, the hours saved are real, but the bigger win is that the cleanup finally stops coming back.
Q6. How do deal scoring and renewal/churn agents protect pipeline and revenue? [toc=6. Deal Scoring & Renewal Agents]
A CS lead once told me she found out about a churn three days before the renewal date. The usage had been dropping for two months. The signal was sitting in the product analytics the whole time. Nobody was watching, because watching by hand across 200 accounts is impossible.
Deal scoring agents grade pipeline health continuously, flagging stalled or low-activity deals before they skew the forecast, while renewal agents score churn risk early, giving CS a 90-day window instead of a two-week scramble. A working churn model is simple: a query-volume drop greater than 50 percent adds 25 risk points, and zero queries for seven straight days adds 30 plus. Both turn signals into action, not dashboards.
🔍 How deal scoring reads pipeline health
Deal scoring means grading each open deal on how likely it is to close, using activity, not gut feel. The agent watches the boring signals a human forgets to check.
No logged activity in 14 days? Flagged. Single-threaded with one contact? Flagged. Pushed close date twice? Flagged. Automated hygiene like this catches stale deals before they quietly inflate your forecast.
🧮 A churn model you can copy
Here's the worked example, kept transparent on purpose. A black-box "risk score" is useless if CS can't see why an account is red.
Query volume drops more than 50 percent: +25 points ⚠️
Zero queries for 7 consecutive days: +30 points ❌
Add your own signals (no QBR booked, champion left): +X points
Cross a threshold, and the account surfaces as an action, not a chart. This is the difference between a vending machine and a coach. The agent re-prioritizes the at-risk account on its own and tells CS where to spend the week.
"Not great at forcasting, We just keep playing hot potato with vendors and it can be frustrating." Justin S., Senior Marketing Operations Specialist Chorus by ZoomInfo G2 Verified Review
"I find the AI call scoring to be gimicky and provides little value." Miles W., Senior Manager Customer Success Avoma G2 Verified Review
That second quote is the honest risk. Scoring is only useful when it's tied to live deal context, not bolted onto a transcript.
Our deal-level model scores both pipeline health and renewal risk from the same context, so a stalled deal and an at-risk account surface as actions, not just red cells on a dashboard. In our work across B2B sales cycles, the accounts you save are almost always the ones a 90-day signal caught early.
Q7. Agentforce vs Gong vs deal-level agents: which RevOps tools are actually agentic? [toc=7. Vendor Reality Check]
"Has anyone actually tried Agentforce? Is it even working for you? Are you seeing any ROI?" I see some version of that question in RevOps communities every week. It's the right question, because the word "agent" is doing a lot of marketing work right now that the products don't always back up.
Agentforce is strong at the data-fabric layer but largely chat-driven. A rep still has to go talk to the agent and move the output elsewhere. Gong understands conversations at the meeting level, while deal-level agents like Oliv.ai understand the entire cycle, including pipeline movement and forecasting. Since recording is now commoditized by Zoom and Teams, the value has moved up to the agent layer.
🤔 Chat-driven is not the same as agentic
Here's the contrarian read, said plainly. Many "agents" today are still chat-focused, not deeply woven into your workflows. You ask, it answers, you copy-paste. That's a smarter chatbot, not an autonomous teammate.
"Lots of clicking to get select the right options. UX needs improvement. Everything opens in a new browser tab." Verified User in Consulting Salesforce Agentforce G2 Verified Review
"Gong's lack of open task APIs limits system integration, making it difficult to connect with other essential tools." Verified User Gong G2 Verified Review
⭐ Which to choose, honestly
To be fair to the incumbents: Agentforce genuinely owns the Salesforce data fabric, and Gong's call-coaching depth is still excellent. Choose Gong if conversation intelligence is your core need. Choose Agentforce if you're deeply committed to Salesforce and have admin muscle.
Choose a deal-level agent like our deal-level revenue platform if your pain is the whole cycle, forecasting, pipeline movement, and follow-up, not just the call. The pilot trap is real: many deployments start full of promise and fade before production, so test in your own workflow before you commit budget.
Q8. What governance guardrails and autonomy levels keep agentic revenue work trustworthy? [toc=8. Governance & Autonomy Tiers]
The first time we let agents run loose on outbound, we learned something uncomfortable. One teammate had to spend 10 to 15 hours a week reviewing the outputs, because the agents work all night, every night. Autonomy without guardrails doesn't remove work. It just moves it.
Trustworthy agentic RevOps runs on bounded autonomy. Agents auto-execute low-risk work like dedupe, enrich, and route, draft medium-risk work for one-click approval like emails and forecast updates, and stay blocked from pricing, legal terms, and customer commitments. Around 73 percent of orgs already run AI in core GTM workflows, and the ones succeeding govern it with clear approval tiers, not blind trust.
⚖️ Pillar one: match autonomy to revenue risk
The governing idea is simple. The more a task touches money you'll report, the more a human stays in the loop.
Bounded autonomy keeps agentic RevOps trustworthy by matching how much freedom an agent gets to how much revenue risk a task carries.
Auto-run (low risk): data hygiene, enrichment, and lead routing. ✅
Draft for approval (medium risk): follow-up emails, and forecast updates. ⏰
Blocked (high risk): pricing, contract terms, and customer commitments. ❌
🧑💻 Pillar two: someone still reviews
Here's the honest "what we got wrong" moment. Agents that never sleep create a new review burden, and it's not a job for lazy people. The fix is a rhythm, not blind faith.
I lean on the 10/80/10 rule. Humans own the first 10 percent (the idea and the taste) and the last 10 percent (the quality check). The agent owns the 80 percent of heavy lifting in between. Pair that with a 30-day correction habit, where you spend an hour or two fixing the agent's mistakes daily, and by day 30 the output is genuinely good.
"Effectively crafting prompts and configuring the underlying actions demands a specific skill set often called prompt engineering." Alessandro N., Salesforce Administrator Salesforce Agentforce G2 Verified Review
"It still needs some serious debugging... could not get past an error when I clicked Create." Jessica C., Senior Business Analyst Salesforce Agentforce G2 Verified Review
🛡️ Pillar three: governance is now a buying criterion
Buyers increasingly screen for SOC 2 (a security audit standard), GDPR and CCPA (data-privacy laws), two-party consent for recording, and the EU AI Act's rules on autonomous agents. These aren't legal footnotes anymore. They decide which vendor clears procurement.
Our agentic revenue approach ships agent outputs as reviewable, deal-level one-pagers, so the human review tier the 10/80/10 rule requires is built in rather than bolted on. I could be early on this, but where my head is right now is that governance, not raw capability, becomes the real moat in the next two years.
Q9. Should mid-market B2B SaaS teams build their own RevOps agents or buy them? [toc=9. Build vs Buy]
A founder I respect once bragged to me that he was a top 1 percent Replit user, having shipped 12 internal apps in 150 days. Then he dropped the line that stuck with me. None of the go-to-market stuff, he said, did they build themselves. The guy who could build anything chose not to build this.
For most mid-market B2B SaaS teams, buy, don't build. Even top builders warn against building GTM agents in-house, because without dedicated go-to-market engineers they go obsolete in months. Build only where you have a true "zone of genius" edge. Buy the forecasting, routing, scoring, and hygiene agents that vendors already maintain and govern.
⚠️ The build scar tissue
Here's the contrarian truth the "just build it with AI" crowd skips. You're not Vercel. An internal agent build that isn't carefully maintained becomes obsolete in a couple of months as models move.
I've watched this in the wild, and it's almost funny. We did a call with a public B2B company worth over 10 billion dollars, the kind you'd assume is an AI leader. When we asked how much of their agent stack they'd built themselves, it was crickets on a call of 20 people. Nobody had done it.
💰 Build vs buy, decided on criteria
The decision isn't ideology. It's whether you have the engineering muscle and a real edge. Here's the rule of thumb I use.
Build vs Buy: Factor-by-Factor Signals
Decision factor
Build if...
Buy if...
GTM engineers
You have dedicated ones
You don't ✅
The workflow
It's your "zone of genius"
It's standard RevOps work
Maintenance
You can fund it forever
You want it to stay current ✅
Time to value
You can wait quarters
You need it this quarter
Model upgrades
You'll re-architect
Vendor handles it ✅
Operators feel the maintenance tax of even bought tools when setup runs deep, a friction that surfaces across comparisons of forecasting platforms:
"I find the setup process challenging, especially when migrating fields from Salesforce, as it can't handle formula fields directly." Josiah R., Head of Sales Operations Clari G2 Verified Review
The economics also reset the goalposts. The old target of 300,000 to 500,000 dollars of revenue per rep is giving way to 3 to 5 million per AI-leveraged rep. You don't hit that by paying engineers to maintain a forecasting bot.
A maintained, deal-level platform like our revenue intelligence platform is the buy-side answer for teams without GTM engineers, because the agents stay current as models change instead of decaying in your codebase. From what surfaces when you actually run this, the build-it dream usually ends as a maintenance bill nobody budgeted for.
Q10. Which RevOps agent should you pilot first, and how do you prove ROI in 90 days? [toc=10. 90-Day Pilot Playbook]
Here's the cheapest experiment in revenue, and almost nobody runs it. Open an incognito browser, go to your own product or process, and do everything a customer or rep does, start to finish. If you do this honestly, you're going to cry at some of what you find. Then pick the thing that made you cry the most, and go buy the agent that fixes it.
Pilot CRM hygiene first. It's low-risk, reversible, and unlocks every other agent by cleaning the data they depend on. Then layer routing, deal scoring, forecasting, and renewal. Prove ROI in 90 days by measuring hours reclaimed (15 to 20 a week on hygiene), forecast-variance drop, and cycle-time reduction.
⏰ The 90-day sequence
By the end of this, you'll have one agent in production and a number to show your board. Run it in order.
A low-risk-first 90-day pilot sequence takes teams from CRM hygiene to forecasting while building a board-ready ROI case.
Days 1 to 30, hygiene. Turn on dedupe and stale-record flagging. Expected outcome: hours reclaimed, and clean data for everything next. ✅
Days 30 to 60, routing and scoring. Auto-assign leads, and flag stalled deals. Expected outcome: faster SLA response, and fewer ghost deals. ⏰
Days 60 to 90, forecasting. Run the forecast call on live pipeline. Expected outcome: tighter variance, and a shorter Monday meeting. 💰
📊 The metrics that prove it worked
Don't measure vanity. A rep doing 300 calls to people who could never buy is a vanity metric, not progress. Track the numbers a CFO respects.
Hours reclaimed per week (target 15 to 20 on hygiene). ⭐
Forecast variance before and after the pilot.
Sales-cycle days saved (often around a week with AI).
Stalled deals caught before quarter-end.
A word on the skill that makes all this stick. The durable advantage isn't clever prompts, it's context engineering, loading the agent with everything about your business so your instructions can stay simple. Pair that with a 30-day correction habit, and the agent gets genuinely good by week four.
"Once set up and installed, Clari is very intuitive to use... it does a great job pulling in data from various sources." Rob W., Sr. Director of Revenue Operations Clari G2 Verified Review
That contrast is the whole game. Time-to-value, not feature count, decides whether a pilot reaches production. If the workflow that made you cry was forecast scrubs or follow-up stitching, that's the deal-level work our AI forecasting agents were built to run. So here's the question I'm sitting with, and I'd genuinely like your take: in two years, does the SaaS you log into quietly become the agents that work for you, turning revenue orchestration into revenue engineering? Tell me what's breaking in your pipeline right now, and I'll show you where an agent actually fits.
Q1. What are AI agents for RevOps, and how are they different from copilots, note-takers, and dashboards? [toc=1. What Are RevOps AI Agents]
A RevOps lead at a 90-rep SaaS company once showed me her Monday stack. Eleven tabs open. Gong on one, Salesforce on another, a Clari forecast view, two spreadsheets, and a note-taker that had faithfully transcribed forty calls she had no time to read. "I have all the data," she said. "I just have no time to act on it." That gap, between knowing and doing, is exactly where AI agents for RevOps live.
AI agents for RevOps are autonomous software systems that don't just suggest, they execute multi-step revenue work like cleaning CRM records, scoring deals, routing leads, and drafting forecasts, then learn from your corrections. Unlike copilots that wait for prompts or note-takers that only transcribe, agents pursue a goal, re-plan when blocked, and run overnight. Think smart employee, not vending machine.
🤖 Agent vs copilot vs note-taker vs dashboard
Here is the cleanest way I've found to explain the difference to a busy operator.
Only an agent owns a goal end to end, which is what separates true AI agents for RevOps from copilots and note-takers.
Dashboard: shows you what happened. You read it, you decide, you act.
Note-taker: records what was said on a call. It captures, it does not act.
Copilot: answers when asked. You prompt it, it drafts, you still ship the work.
Agent: owns a goal end to end. It pulls context, takes the next step, and asks for help only when it hits a wall.
The analogy I keep coming back to is the vending machine. Traditional automation is a vending machine, fixed input, fixed output, and it breaks the second the payment fails. An agent is more like a coach or a smart employee. It picks a goal, junks the plan if it isn't working, improvises if it is, and goes relentlessly after the outcome.
⚠️ Why most "AI tools" are still just note-takers
Here's the part the category avoids saying out loud. Most companies shipping "AI for sales" built their own note-taker, and many of them stall six or seven months in, still working as note-takers only.
I think we're sitting at a real inflection point. The landscape is moving from chat to agents, and the teams genuinely using agents, not chatbots, report being far more productive in a day's work. I could be slightly off on the exact multiple people quote, but the direction is not in question from what I see inside live revenue teams.
✅ What changes on Monday
The payoff is simple. With a true agent, CRM hygiene runs overnight, stale deals get flagged before your forecast call, and a follow-up draft is waiting before you've finished your coffee. You move from reading dashboards to reviewing decisions.
This is the line we drew when building Oliv. Agentic platforms like deal-level revenue intelligence platforms operate at the deal level, tracking the entire sales cycle rather than transcribing a single meeting, which is precisely what separates an agent from a note-taker. When we rebuilt our own pipeline reviews on Oliv agents, the work shifted from gathering context to checking the agent's judgment, and that's the shift worth chasing.
Q2. Why are traditional RevOps stacks breaking under "manual context-stitching"? [toc=2. The Context-Stitching Problem]
Picture an AE who needs to send one good follow-up. The real workflow looks like this: pull the transcript from Gong, paste it into ChatGPT, write a prompt, paste the output into Outlook, then go hunt for the right PDF to attach. It's so much work that most people just don't do it. That, in one scene, is the disease I call manual context-stitching, and it's quietly breaking RevOps stacks everywhere.
RevOps stacks break because every new tool adds another silo a human must reconcile by hand. You pull a transcript from one app, context from the CRM, a deck from a third, then stitch it together yourself. More technology creates more brittleness, not less. The fix isn't another dashboard. It's an agent that reads across systems and acts.
Manual context-stitching forces reps to reconcile disconnected silos by hand, which is exactly what agents are meant to eliminate.
🔌 The resilience paradox
The standard read says the answer to messy revenue data is more tooling. I think that gets it backwards.
Most RevOps teams now spend the bulk of their week maintaining integrations and rebuilding reports that should have been automated years ago. Every tool you add to "fix visibility" becomes one more surface a human has to keep in sync. Running a growth machine this way is like driving an expensive racing car that's only firing on two cylinders.
🗃️ The CRM-as-dead-air problem
Here's a contrarian truth most vendors won't print. The CRM, as a product, has largely failed at its original promise. For most reps, it's a dumb repository they update weekly because management requires it, not because it makes them faster.
The data isn't wrong because reps are lazy. It's stale because keeping it fresh means more stitching, and stitching is the thing nobody has time for. A "15-tool stack" still can't predict pipeline accurately, because the intelligence is scattered across fifteen places no human can hold at once.
When a six-figure revenue tool gets demoted to "call recorder," that's context-stitching winning and the stack losing.
✅ Load the context, stop the stitching
The mental shift is this: context should be loaded into the agent, not stitched by the human. Your job moves from assembling the picture to approving the action.
This is the core of what we built at Oliv. Our approach to deal-level revenue intelligence collapses the stitching by analyzing at the deal level across the full cycle, so the agent, not the rep, assembles context before a follow-up is ever drafted. From what surfaces when you actually run this, the win isn't a prettier dashboard. It's the half-hour per deal you stop spending in copy-paste limbo.
Q3. How do the five RevOps agent types compare across forecasting, lead routing, deal scoring, CRM hygiene, and renewal? [toc=3. The Five Agents Compared]
Every RevOps leader I talk to wants the same thing: a straight answer on which agent to trust with the keys and which to keep on a short leash. The honest answer is that they're not equal, and treating them as one "AI rollout" is how pilots stall. The five core RevOps agents differ most on autonomy and risk.
CRM hygiene and lead routing run near-autonomously and save the most hours, often 15 to 20 a week. Forecasting and deal scoring need human review because they shape revenue calls. Renewal agents sit in between, scoring churn risk for CS. The rule is simple: match autonomy to revenue risk. Auto-run low-stakes data work, keep humans on anything that touches a reported number.
🎂 The three-layer scoring lens
Before the table, here's the frame I use. Think of any agent as reaching across three layers: a baseline data layer (recording and transcription, now basically commoditized and should be cheap), an intelligence layer (tracking qualification fields and deal health), and an agent layer (shipping proactive reports and actions). The further up an agent reaches, the more value, and the more oversight it needs.
📊 The five agents compared
RevOps Agents: Autonomy, Guardrails, and Mid-Market Fit
Agent type
Integration depth
Autonomy level
Governance guardrail
Time saved
Mid-market fit
CRM hygiene
Deep (writes to CRM)
High, near-autonomous
Auto-run, log every change
15 to 20 hrs/week
⭐ Pilot first
Lead routing
Deep (CRM + SLA rules)
High, near-autonomous
Auto-run, alert on exceptions
High
⭐ Strong
Deal scoring
Medium (intelligence layer)
Medium, recommends
Human reviews flags
Medium
Strong
Forecasting
Deep (full deal cycle)
Medium, drafts the call
Human approves the number
High
⭐ High value
Renewal / churn
Medium (CS + usage data)
Medium, scores risk
CS confirms before action
Medium
Growing
🎯 Pilot-first guidance
CRM hygiene: start here if duplicate accounts and stale fields are skewing every report.
Lead routing: pick this if leads sit unassigned past your SLA.
Deal scoring: add once your data is clean enough to trust the signal.
Forecasting: prioritize if your Monday call runs on stale slides.
Renewal: layer in when CS is reacting to churn instead of predicting it.
What real buyers report lines up with this risk ladder. Forecasting and data access are where the friction shows, and a closer look at how forecasting tools handle data makes the pattern clear:
"While Gong offers valuable insights into call data... our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export capabilities." Neel P., Sales Operations Manager Gong G2 Verified Review
"Some users may find Clari's analytics and forecasting tools complex, requiring significant onboarding and training." Bharat K., Revenue Operations Manager Clari G2 Verified Review
Where most point tools cover a single column, our deal-level forecasting model spans the intelligence and agent layers across forecasting, scoring, and hygiene from one model. In our work with mid-market RevOps teams, the value isn't owning one row of that table, it's that the same context feeds all of them, so a clean record improves the forecast and the renewal score at the same time.
Q4. How accurate are AI forecasting agents, and what time do they actually save? [toc=4. Forecasting Agents & ROI]
Every Thursday and Friday across thousands of B2B SaaS teams, the same ritual plays out. Managers sit with each rep for one to two hours to understand what moved in the pipeline, then manually key that into a forecast and build the report they'll show on Monday. By Monday, the numbers are already a few days stale. That scrub is the single most expensive recurring meeting in revenue, and it's the first thing a forecasting agent kills.
AI forecasting agents cut forecast variance from a typical 30 to 40 percent down to under 10 percent, against Gartner's "healthy" benchmark of 85 percent or higher accuracy. The bigger win is time. Managers reclaim that weekly scrub because the agent pulls live pipeline movement instead of waiting for the slide deck. The rule of thumb: if a rep can't articulate deal status, push it off the forecast.
📈 What the numbers actually say
Let me ground the claim in primary data, because operators rightly screenshot weak stats and roast them.
Variance: integrated AI forecasting moves variance from the common 30 to 40 percent range to under 10 percent.
Baseline: Gartner treats 85 percent or higher as a healthy forecast-accuracy mark, with 90 percent plus for highly disciplined orgs.
Cycle time and quota: LinkedIn's research found 69 percent of sellers using AI cut their sales cycle by about a week, and daily AI users are twice as likely to exceed targets.
I'll add one honest hedge. These lifts assume clean inputs. Forecasting is a RevOps problem before it's a sales-discipline problem, because no agent rescues a forecast built on stale stages and ghost deals.
⏰ The "push it off the forecast" discipline
Here's the Monday-morning move worth stealing. If you've exhausted your qualifying questions and a rep still can't articulate exactly where a deal stands, tell them to remove it from the forecast. An agent makes this enforceable, flagging any commit-stage deal with no logged activity, so the discipline runs automatically instead of depending on a manager's memory.
The friction with legacy tools is usually delay and trust, not raw capability, a theme that runs through honest accounts of Gong forecasting in the wild:
"Gong's deal forecasting we don't use... there's so much in Gong, that we don't use everything." Karel Bos, Head of Sales Gong TrustRadius Verified Review
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit." Dexter L., Customer Success Executive Clari G2 Verified Review
When forecasting features go unused or still need a manual calculator, the time-saving promise quietly evaporates.
This is where speed matters more than people expect. Our deal-level forecasting agent updates within about five minutes of a call and tracks pipeline movement continuously, versus the 20 to 30 minute delay common in legacy tools, so Monday's forecast is built from live reality, not a Thursday memory. From what surfaces when you actually run a forecast call this way, the debate stops being "is the number right" and starts being "what do we do about it."
Q5. Do CRM hygiene and lead routing agents really save 15 to 20 hours a week? [toc=5. Hygiene & Routing Agents]
Walk into any mid-market RevOps team on a quarter-end Friday and you'll find someone hand-merging duplicate Salesforce accounts at 7 PM. That person isn't strategic. They're a data janitor. And the worst part is that next quarter the same duplicates come back, because the cleanup was manual.
Yes, CRM hygiene agents save RevOps teams a documented 15 to 20 hours a week by auto-deduping, enriching, and flagging stale records, while routing agents cut hours of manual assignment and SLA-chasing. They're the safest first pilots because errors are low-stakes and reversible. The catch: agents amplify bad data, so hygiene must come before scoring or forecasting.
⚠️ Why rule-based capture keeps breaking
Old automation follows rigid rules, and revenue data is anything but rigid. Two patterns break it every time.
The first is over-redaction. Einstein activity capture, for example, can flag a normal email as "sensitive" and hide it, even when it isn't, so you never build a complete customer picture. The second is duplicate accounts. Simple rule-based logic has no clean way to decide what happens when it sees two records for the same company.
"It can be complex to set up and often requires skilled administrators or developers to customize and integrate properly, which adds time and cost." Verified User in Marketing Salesforce Agentforce G2 Verified Review
Here's the sequence I'd run, and I'll hedge it: order matters more than speed.
Dedupe and flag stale records first. Clean the foundation so every later agent inherits good data. ✅
Turn on routing and SLA enforcement next. Auto-assign leads and ping when an SLA, your agreed response-time rule, slips. ⏰
Only then add scoring or forecasting. These depend on clean inputs, so they go last. 💰
One warning from the field. If your systems are messy, automation amplifies the mess. A bad "Hello {First_Name}" merge field doesn't save time, it broadcasts the problem to every prospect.
Because our deal-level platform builds a complete, deal-level customer picture, hygiene agents work from clean context instead of redacted or duplicated records, which is exactly the failure mode rule-based capture hits. From what surfaces when you actually run this, the hours saved are real, but the bigger win is that the cleanup finally stops coming back.
Q6. How do deal scoring and renewal/churn agents protect pipeline and revenue? [toc=6. Deal Scoring & Renewal Agents]
A CS lead once told me she found out about a churn three days before the renewal date. The usage had been dropping for two months. The signal was sitting in the product analytics the whole time. Nobody was watching, because watching by hand across 200 accounts is impossible.
Deal scoring agents grade pipeline health continuously, flagging stalled or low-activity deals before they skew the forecast, while renewal agents score churn risk early, giving CS a 90-day window instead of a two-week scramble. A working churn model is simple: a query-volume drop greater than 50 percent adds 25 risk points, and zero queries for seven straight days adds 30 plus. Both turn signals into action, not dashboards.
🔍 How deal scoring reads pipeline health
Deal scoring means grading each open deal on how likely it is to close, using activity, not gut feel. The agent watches the boring signals a human forgets to check.
No logged activity in 14 days? Flagged. Single-threaded with one contact? Flagged. Pushed close date twice? Flagged. Automated hygiene like this catches stale deals before they quietly inflate your forecast.
🧮 A churn model you can copy
Here's the worked example, kept transparent on purpose. A black-box "risk score" is useless if CS can't see why an account is red.
Query volume drops more than 50 percent: +25 points ⚠️
Zero queries for 7 consecutive days: +30 points ❌
Add your own signals (no QBR booked, champion left): +X points
Cross a threshold, and the account surfaces as an action, not a chart. This is the difference between a vending machine and a coach. The agent re-prioritizes the at-risk account on its own and tells CS where to spend the week.
"Not great at forcasting, We just keep playing hot potato with vendors and it can be frustrating." Justin S., Senior Marketing Operations Specialist Chorus by ZoomInfo G2 Verified Review
"I find the AI call scoring to be gimicky and provides little value." Miles W., Senior Manager Customer Success Avoma G2 Verified Review
That second quote is the honest risk. Scoring is only useful when it's tied to live deal context, not bolted onto a transcript.
Our deal-level model scores both pipeline health and renewal risk from the same context, so a stalled deal and an at-risk account surface as actions, not just red cells on a dashboard. In our work across B2B sales cycles, the accounts you save are almost always the ones a 90-day signal caught early.
Q7. Agentforce vs Gong vs deal-level agents: which RevOps tools are actually agentic? [toc=7. Vendor Reality Check]
"Has anyone actually tried Agentforce? Is it even working for you? Are you seeing any ROI?" I see some version of that question in RevOps communities every week. It's the right question, because the word "agent" is doing a lot of marketing work right now that the products don't always back up.
Agentforce is strong at the data-fabric layer but largely chat-driven. A rep still has to go talk to the agent and move the output elsewhere. Gong understands conversations at the meeting level, while deal-level agents like Oliv.ai understand the entire cycle, including pipeline movement and forecasting. Since recording is now commoditized by Zoom and Teams, the value has moved up to the agent layer.
🤔 Chat-driven is not the same as agentic
Here's the contrarian read, said plainly. Many "agents" today are still chat-focused, not deeply woven into your workflows. You ask, it answers, you copy-paste. That's a smarter chatbot, not an autonomous teammate.
"Lots of clicking to get select the right options. UX needs improvement. Everything opens in a new browser tab." Verified User in Consulting Salesforce Agentforce G2 Verified Review
"Gong's lack of open task APIs limits system integration, making it difficult to connect with other essential tools." Verified User Gong G2 Verified Review
⭐ Which to choose, honestly
To be fair to the incumbents: Agentforce genuinely owns the Salesforce data fabric, and Gong's call-coaching depth is still excellent. Choose Gong if conversation intelligence is your core need. Choose Agentforce if you're deeply committed to Salesforce and have admin muscle.
Choose a deal-level agent like our deal-level revenue platform if your pain is the whole cycle, forecasting, pipeline movement, and follow-up, not just the call. The pilot trap is real: many deployments start full of promise and fade before production, so test in your own workflow before you commit budget.
Q8. What governance guardrails and autonomy levels keep agentic revenue work trustworthy? [toc=8. Governance & Autonomy Tiers]
The first time we let agents run loose on outbound, we learned something uncomfortable. One teammate had to spend 10 to 15 hours a week reviewing the outputs, because the agents work all night, every night. Autonomy without guardrails doesn't remove work. It just moves it.
Trustworthy agentic RevOps runs on bounded autonomy. Agents auto-execute low-risk work like dedupe, enrich, and route, draft medium-risk work for one-click approval like emails and forecast updates, and stay blocked from pricing, legal terms, and customer commitments. Around 73 percent of orgs already run AI in core GTM workflows, and the ones succeeding govern it with clear approval tiers, not blind trust.
⚖️ Pillar one: match autonomy to revenue risk
The governing idea is simple. The more a task touches money you'll report, the more a human stays in the loop.
Bounded autonomy keeps agentic RevOps trustworthy by matching how much freedom an agent gets to how much revenue risk a task carries.
Auto-run (low risk): data hygiene, enrichment, and lead routing. ✅
Draft for approval (medium risk): follow-up emails, and forecast updates. ⏰
Blocked (high risk): pricing, contract terms, and customer commitments. ❌
🧑💻 Pillar two: someone still reviews
Here's the honest "what we got wrong" moment. Agents that never sleep create a new review burden, and it's not a job for lazy people. The fix is a rhythm, not blind faith.
I lean on the 10/80/10 rule. Humans own the first 10 percent (the idea and the taste) and the last 10 percent (the quality check). The agent owns the 80 percent of heavy lifting in between. Pair that with a 30-day correction habit, where you spend an hour or two fixing the agent's mistakes daily, and by day 30 the output is genuinely good.
"Effectively crafting prompts and configuring the underlying actions demands a specific skill set often called prompt engineering." Alessandro N., Salesforce Administrator Salesforce Agentforce G2 Verified Review
"It still needs some serious debugging... could not get past an error when I clicked Create." Jessica C., Senior Business Analyst Salesforce Agentforce G2 Verified Review
🛡️ Pillar three: governance is now a buying criterion
Buyers increasingly screen for SOC 2 (a security audit standard), GDPR and CCPA (data-privacy laws), two-party consent for recording, and the EU AI Act's rules on autonomous agents. These aren't legal footnotes anymore. They decide which vendor clears procurement.
Our agentic revenue approach ships agent outputs as reviewable, deal-level one-pagers, so the human review tier the 10/80/10 rule requires is built in rather than bolted on. I could be early on this, but where my head is right now is that governance, not raw capability, becomes the real moat in the next two years.
Q9. Should mid-market B2B SaaS teams build their own RevOps agents or buy them? [toc=9. Build vs Buy]
A founder I respect once bragged to me that he was a top 1 percent Replit user, having shipped 12 internal apps in 150 days. Then he dropped the line that stuck with me. None of the go-to-market stuff, he said, did they build themselves. The guy who could build anything chose not to build this.
For most mid-market B2B SaaS teams, buy, don't build. Even top builders warn against building GTM agents in-house, because without dedicated go-to-market engineers they go obsolete in months. Build only where you have a true "zone of genius" edge. Buy the forecasting, routing, scoring, and hygiene agents that vendors already maintain and govern.
⚠️ The build scar tissue
Here's the contrarian truth the "just build it with AI" crowd skips. You're not Vercel. An internal agent build that isn't carefully maintained becomes obsolete in a couple of months as models move.
I've watched this in the wild, and it's almost funny. We did a call with a public B2B company worth over 10 billion dollars, the kind you'd assume is an AI leader. When we asked how much of their agent stack they'd built themselves, it was crickets on a call of 20 people. Nobody had done it.
💰 Build vs buy, decided on criteria
The decision isn't ideology. It's whether you have the engineering muscle and a real edge. Here's the rule of thumb I use.
Build vs Buy: Factor-by-Factor Signals
Decision factor
Build if...
Buy if...
GTM engineers
You have dedicated ones
You don't ✅
The workflow
It's your "zone of genius"
It's standard RevOps work
Maintenance
You can fund it forever
You want it to stay current ✅
Time to value
You can wait quarters
You need it this quarter
Model upgrades
You'll re-architect
Vendor handles it ✅
Operators feel the maintenance tax of even bought tools when setup runs deep, a friction that surfaces across comparisons of forecasting platforms:
"I find the setup process challenging, especially when migrating fields from Salesforce, as it can't handle formula fields directly." Josiah R., Head of Sales Operations Clari G2 Verified Review
The economics also reset the goalposts. The old target of 300,000 to 500,000 dollars of revenue per rep is giving way to 3 to 5 million per AI-leveraged rep. You don't hit that by paying engineers to maintain a forecasting bot.
A maintained, deal-level platform like our revenue intelligence platform is the buy-side answer for teams without GTM engineers, because the agents stay current as models change instead of decaying in your codebase. From what surfaces when you actually run this, the build-it dream usually ends as a maintenance bill nobody budgeted for.
Q10. Which RevOps agent should you pilot first, and how do you prove ROI in 90 days? [toc=10. 90-Day Pilot Playbook]
Here's the cheapest experiment in revenue, and almost nobody runs it. Open an incognito browser, go to your own product or process, and do everything a customer or rep does, start to finish. If you do this honestly, you're going to cry at some of what you find. Then pick the thing that made you cry the most, and go buy the agent that fixes it.
Pilot CRM hygiene first. It's low-risk, reversible, and unlocks every other agent by cleaning the data they depend on. Then layer routing, deal scoring, forecasting, and renewal. Prove ROI in 90 days by measuring hours reclaimed (15 to 20 a week on hygiene), forecast-variance drop, and cycle-time reduction.
⏰ The 90-day sequence
By the end of this, you'll have one agent in production and a number to show your board. Run it in order.
A low-risk-first 90-day pilot sequence takes teams from CRM hygiene to forecasting while building a board-ready ROI case.
Days 1 to 30, hygiene. Turn on dedupe and stale-record flagging. Expected outcome: hours reclaimed, and clean data for everything next. ✅
Days 30 to 60, routing and scoring. Auto-assign leads, and flag stalled deals. Expected outcome: faster SLA response, and fewer ghost deals. ⏰
Days 60 to 90, forecasting. Run the forecast call on live pipeline. Expected outcome: tighter variance, and a shorter Monday meeting. 💰
📊 The metrics that prove it worked
Don't measure vanity. A rep doing 300 calls to people who could never buy is a vanity metric, not progress. Track the numbers a CFO respects.
Hours reclaimed per week (target 15 to 20 on hygiene). ⭐
Forecast variance before and after the pilot.
Sales-cycle days saved (often around a week with AI).
Stalled deals caught before quarter-end.
A word on the skill that makes all this stick. The durable advantage isn't clever prompts, it's context engineering, loading the agent with everything about your business so your instructions can stay simple. Pair that with a 30-day correction habit, and the agent gets genuinely good by week four.
"Once set up and installed, Clari is very intuitive to use... it does a great job pulling in data from various sources." Rob W., Sr. Director of Revenue Operations Clari G2 Verified Review
That contrast is the whole game. Time-to-value, not feature count, decides whether a pilot reaches production. If the workflow that made you cry was forecast scrubs or follow-up stitching, that's the deal-level work our AI forecasting agents were built to run. So here's the question I'm sitting with, and I'd genuinely like your take: in two years, does the SaaS you log into quietly become the agents that work for you, turning revenue orchestration into revenue engineering? Tell me what's breaking in your pipeline right now, and I'll show you where an agent actually fits.
Q1. What are AI agents for RevOps, and how are they different from copilots, note-takers, and dashboards? [toc=1. What Are RevOps AI Agents]
A RevOps lead at a 90-rep SaaS company once showed me her Monday stack. Eleven tabs open. Gong on one, Salesforce on another, a Clari forecast view, two spreadsheets, and a note-taker that had faithfully transcribed forty calls she had no time to read. "I have all the data," she said. "I just have no time to act on it." That gap, between knowing and doing, is exactly where AI agents for RevOps live.
AI agents for RevOps are autonomous software systems that don't just suggest, they execute multi-step revenue work like cleaning CRM records, scoring deals, routing leads, and drafting forecasts, then learn from your corrections. Unlike copilots that wait for prompts or note-takers that only transcribe, agents pursue a goal, re-plan when blocked, and run overnight. Think smart employee, not vending machine.
🤖 Agent vs copilot vs note-taker vs dashboard
Here is the cleanest way I've found to explain the difference to a busy operator.
Only an agent owns a goal end to end, which is what separates true AI agents for RevOps from copilots and note-takers.
Dashboard: shows you what happened. You read it, you decide, you act.
Note-taker: records what was said on a call. It captures, it does not act.
Copilot: answers when asked. You prompt it, it drafts, you still ship the work.
Agent: owns a goal end to end. It pulls context, takes the next step, and asks for help only when it hits a wall.
The analogy I keep coming back to is the vending machine. Traditional automation is a vending machine, fixed input, fixed output, and it breaks the second the payment fails. An agent is more like a coach or a smart employee. It picks a goal, junks the plan if it isn't working, improvises if it is, and goes relentlessly after the outcome.
⚠️ Why most "AI tools" are still just note-takers
Here's the part the category avoids saying out loud. Most companies shipping "AI for sales" built their own note-taker, and many of them stall six or seven months in, still working as note-takers only.
I think we're sitting at a real inflection point. The landscape is moving from chat to agents, and the teams genuinely using agents, not chatbots, report being far more productive in a day's work. I could be slightly off on the exact multiple people quote, but the direction is not in question from what I see inside live revenue teams.
✅ What changes on Monday
The payoff is simple. With a true agent, CRM hygiene runs overnight, stale deals get flagged before your forecast call, and a follow-up draft is waiting before you've finished your coffee. You move from reading dashboards to reviewing decisions.
This is the line we drew when building Oliv. Agentic platforms like deal-level revenue intelligence platforms operate at the deal level, tracking the entire sales cycle rather than transcribing a single meeting, which is precisely what separates an agent from a note-taker. When we rebuilt our own pipeline reviews on Oliv agents, the work shifted from gathering context to checking the agent's judgment, and that's the shift worth chasing.
Q2. Why are traditional RevOps stacks breaking under "manual context-stitching"? [toc=2. The Context-Stitching Problem]
Picture an AE who needs to send one good follow-up. The real workflow looks like this: pull the transcript from Gong, paste it into ChatGPT, write a prompt, paste the output into Outlook, then go hunt for the right PDF to attach. It's so much work that most people just don't do it. That, in one scene, is the disease I call manual context-stitching, and it's quietly breaking RevOps stacks everywhere.
RevOps stacks break because every new tool adds another silo a human must reconcile by hand. You pull a transcript from one app, context from the CRM, a deck from a third, then stitch it together yourself. More technology creates more brittleness, not less. The fix isn't another dashboard. It's an agent that reads across systems and acts.
Manual context-stitching forces reps to reconcile disconnected silos by hand, which is exactly what agents are meant to eliminate.
🔌 The resilience paradox
The standard read says the answer to messy revenue data is more tooling. I think that gets it backwards.
Most RevOps teams now spend the bulk of their week maintaining integrations and rebuilding reports that should have been automated years ago. Every tool you add to "fix visibility" becomes one more surface a human has to keep in sync. Running a growth machine this way is like driving an expensive racing car that's only firing on two cylinders.
🗃️ The CRM-as-dead-air problem
Here's a contrarian truth most vendors won't print. The CRM, as a product, has largely failed at its original promise. For most reps, it's a dumb repository they update weekly because management requires it, not because it makes them faster.
The data isn't wrong because reps are lazy. It's stale because keeping it fresh means more stitching, and stitching is the thing nobody has time for. A "15-tool stack" still can't predict pipeline accurately, because the intelligence is scattered across fifteen places no human can hold at once.
When a six-figure revenue tool gets demoted to "call recorder," that's context-stitching winning and the stack losing.
✅ Load the context, stop the stitching
The mental shift is this: context should be loaded into the agent, not stitched by the human. Your job moves from assembling the picture to approving the action.
This is the core of what we built at Oliv. Our approach to deal-level revenue intelligence collapses the stitching by analyzing at the deal level across the full cycle, so the agent, not the rep, assembles context before a follow-up is ever drafted. From what surfaces when you actually run this, the win isn't a prettier dashboard. It's the half-hour per deal you stop spending in copy-paste limbo.
Q3. How do the five RevOps agent types compare across forecasting, lead routing, deal scoring, CRM hygiene, and renewal? [toc=3. The Five Agents Compared]
Every RevOps leader I talk to wants the same thing: a straight answer on which agent to trust with the keys and which to keep on a short leash. The honest answer is that they're not equal, and treating them as one "AI rollout" is how pilots stall. The five core RevOps agents differ most on autonomy and risk.
CRM hygiene and lead routing run near-autonomously and save the most hours, often 15 to 20 a week. Forecasting and deal scoring need human review because they shape revenue calls. Renewal agents sit in between, scoring churn risk for CS. The rule is simple: match autonomy to revenue risk. Auto-run low-stakes data work, keep humans on anything that touches a reported number.
🎂 The three-layer scoring lens
Before the table, here's the frame I use. Think of any agent as reaching across three layers: a baseline data layer (recording and transcription, now basically commoditized and should be cheap), an intelligence layer (tracking qualification fields and deal health), and an agent layer (shipping proactive reports and actions). The further up an agent reaches, the more value, and the more oversight it needs.
📊 The five agents compared
RevOps Agents: Autonomy, Guardrails, and Mid-Market Fit
Agent type
Integration depth
Autonomy level
Governance guardrail
Time saved
Mid-market fit
CRM hygiene
Deep (writes to CRM)
High, near-autonomous
Auto-run, log every change
15 to 20 hrs/week
⭐ Pilot first
Lead routing
Deep (CRM + SLA rules)
High, near-autonomous
Auto-run, alert on exceptions
High
⭐ Strong
Deal scoring
Medium (intelligence layer)
Medium, recommends
Human reviews flags
Medium
Strong
Forecasting
Deep (full deal cycle)
Medium, drafts the call
Human approves the number
High
⭐ High value
Renewal / churn
Medium (CS + usage data)
Medium, scores risk
CS confirms before action
Medium
Growing
🎯 Pilot-first guidance
CRM hygiene: start here if duplicate accounts and stale fields are skewing every report.
Lead routing: pick this if leads sit unassigned past your SLA.
Deal scoring: add once your data is clean enough to trust the signal.
Forecasting: prioritize if your Monday call runs on stale slides.
Renewal: layer in when CS is reacting to churn instead of predicting it.
What real buyers report lines up with this risk ladder. Forecasting and data access are where the friction shows, and a closer look at how forecasting tools handle data makes the pattern clear:
"While Gong offers valuable insights into call data... our experience has been impacted by significant data access limitations, especially concerning data portability and bulk export capabilities." Neel P., Sales Operations Manager Gong G2 Verified Review
"Some users may find Clari's analytics and forecasting tools complex, requiring significant onboarding and training." Bharat K., Revenue Operations Manager Clari G2 Verified Review
Where most point tools cover a single column, our deal-level forecasting model spans the intelligence and agent layers across forecasting, scoring, and hygiene from one model. In our work with mid-market RevOps teams, the value isn't owning one row of that table, it's that the same context feeds all of them, so a clean record improves the forecast and the renewal score at the same time.
Q4. How accurate are AI forecasting agents, and what time do they actually save? [toc=4. Forecasting Agents & ROI]
Every Thursday and Friday across thousands of B2B SaaS teams, the same ritual plays out. Managers sit with each rep for one to two hours to understand what moved in the pipeline, then manually key that into a forecast and build the report they'll show on Monday. By Monday, the numbers are already a few days stale. That scrub is the single most expensive recurring meeting in revenue, and it's the first thing a forecasting agent kills.
AI forecasting agents cut forecast variance from a typical 30 to 40 percent down to under 10 percent, against Gartner's "healthy" benchmark of 85 percent or higher accuracy. The bigger win is time. Managers reclaim that weekly scrub because the agent pulls live pipeline movement instead of waiting for the slide deck. The rule of thumb: if a rep can't articulate deal status, push it off the forecast.
📈 What the numbers actually say
Let me ground the claim in primary data, because operators rightly screenshot weak stats and roast them.
Variance: integrated AI forecasting moves variance from the common 30 to 40 percent range to under 10 percent.
Baseline: Gartner treats 85 percent or higher as a healthy forecast-accuracy mark, with 90 percent plus for highly disciplined orgs.
Cycle time and quota: LinkedIn's research found 69 percent of sellers using AI cut their sales cycle by about a week, and daily AI users are twice as likely to exceed targets.
I'll add one honest hedge. These lifts assume clean inputs. Forecasting is a RevOps problem before it's a sales-discipline problem, because no agent rescues a forecast built on stale stages and ghost deals.
⏰ The "push it off the forecast" discipline
Here's the Monday-morning move worth stealing. If you've exhausted your qualifying questions and a rep still can't articulate exactly where a deal stands, tell them to remove it from the forecast. An agent makes this enforceable, flagging any commit-stage deal with no logged activity, so the discipline runs automatically instead of depending on a manager's memory.
The friction with legacy tools is usually delay and trust, not raw capability, a theme that runs through honest accounts of Gong forecasting in the wild:
"Gong's deal forecasting we don't use... there's so much in Gong, that we don't use everything." Karel Bos, Head of Sales Gong TrustRadius Verified Review
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit." Dexter L., Customer Success Executive Clari G2 Verified Review
When forecasting features go unused or still need a manual calculator, the time-saving promise quietly evaporates.
This is where speed matters more than people expect. Our deal-level forecasting agent updates within about five minutes of a call and tracks pipeline movement continuously, versus the 20 to 30 minute delay common in legacy tools, so Monday's forecast is built from live reality, not a Thursday memory. From what surfaces when you actually run a forecast call this way, the debate stops being "is the number right" and starts being "what do we do about it."
Q5. Do CRM hygiene and lead routing agents really save 15 to 20 hours a week? [toc=5. Hygiene & Routing Agents]
Walk into any mid-market RevOps team on a quarter-end Friday and you'll find someone hand-merging duplicate Salesforce accounts at 7 PM. That person isn't strategic. They're a data janitor. And the worst part is that next quarter the same duplicates come back, because the cleanup was manual.
Yes, CRM hygiene agents save RevOps teams a documented 15 to 20 hours a week by auto-deduping, enriching, and flagging stale records, while routing agents cut hours of manual assignment and SLA-chasing. They're the safest first pilots because errors are low-stakes and reversible. The catch: agents amplify bad data, so hygiene must come before scoring or forecasting.
⚠️ Why rule-based capture keeps breaking
Old automation follows rigid rules, and revenue data is anything but rigid. Two patterns break it every time.
The first is over-redaction. Einstein activity capture, for example, can flag a normal email as "sensitive" and hide it, even when it isn't, so you never build a complete customer picture. The second is duplicate accounts. Simple rule-based logic has no clean way to decide what happens when it sees two records for the same company.
"It can be complex to set up and often requires skilled administrators or developers to customize and integrate properly, which adds time and cost." Verified User in Marketing Salesforce Agentforce G2 Verified Review
Here's the sequence I'd run, and I'll hedge it: order matters more than speed.
Dedupe and flag stale records first. Clean the foundation so every later agent inherits good data. ✅
Turn on routing and SLA enforcement next. Auto-assign leads and ping when an SLA, your agreed response-time rule, slips. ⏰
Only then add scoring or forecasting. These depend on clean inputs, so they go last. 💰
One warning from the field. If your systems are messy, automation amplifies the mess. A bad "Hello {First_Name}" merge field doesn't save time, it broadcasts the problem to every prospect.
Because our deal-level platform builds a complete, deal-level customer picture, hygiene agents work from clean context instead of redacted or duplicated records, which is exactly the failure mode rule-based capture hits. From what surfaces when you actually run this, the hours saved are real, but the bigger win is that the cleanup finally stops coming back.
Q6. How do deal scoring and renewal/churn agents protect pipeline and revenue? [toc=6. Deal Scoring & Renewal Agents]
A CS lead once told me she found out about a churn three days before the renewal date. The usage had been dropping for two months. The signal was sitting in the product analytics the whole time. Nobody was watching, because watching by hand across 200 accounts is impossible.
Deal scoring agents grade pipeline health continuously, flagging stalled or low-activity deals before they skew the forecast, while renewal agents score churn risk early, giving CS a 90-day window instead of a two-week scramble. A working churn model is simple: a query-volume drop greater than 50 percent adds 25 risk points, and zero queries for seven straight days adds 30 plus. Both turn signals into action, not dashboards.
🔍 How deal scoring reads pipeline health
Deal scoring means grading each open deal on how likely it is to close, using activity, not gut feel. The agent watches the boring signals a human forgets to check.
No logged activity in 14 days? Flagged. Single-threaded with one contact? Flagged. Pushed close date twice? Flagged. Automated hygiene like this catches stale deals before they quietly inflate your forecast.
🧮 A churn model you can copy
Here's the worked example, kept transparent on purpose. A black-box "risk score" is useless if CS can't see why an account is red.
Query volume drops more than 50 percent: +25 points ⚠️
Zero queries for 7 consecutive days: +30 points ❌
Add your own signals (no QBR booked, champion left): +X points
Cross a threshold, and the account surfaces as an action, not a chart. This is the difference between a vending machine and a coach. The agent re-prioritizes the at-risk account on its own and tells CS where to spend the week.
"Not great at forcasting, We just keep playing hot potato with vendors and it can be frustrating." Justin S., Senior Marketing Operations Specialist Chorus by ZoomInfo G2 Verified Review
"I find the AI call scoring to be gimicky and provides little value." Miles W., Senior Manager Customer Success Avoma G2 Verified Review
That second quote is the honest risk. Scoring is only useful when it's tied to live deal context, not bolted onto a transcript.
Our deal-level model scores both pipeline health and renewal risk from the same context, so a stalled deal and an at-risk account surface as actions, not just red cells on a dashboard. In our work across B2B sales cycles, the accounts you save are almost always the ones a 90-day signal caught early.
Q7. Agentforce vs Gong vs deal-level agents: which RevOps tools are actually agentic? [toc=7. Vendor Reality Check]
"Has anyone actually tried Agentforce? Is it even working for you? Are you seeing any ROI?" I see some version of that question in RevOps communities every week. It's the right question, because the word "agent" is doing a lot of marketing work right now that the products don't always back up.
Agentforce is strong at the data-fabric layer but largely chat-driven. A rep still has to go talk to the agent and move the output elsewhere. Gong understands conversations at the meeting level, while deal-level agents like Oliv.ai understand the entire cycle, including pipeline movement and forecasting. Since recording is now commoditized by Zoom and Teams, the value has moved up to the agent layer.
🤔 Chat-driven is not the same as agentic
Here's the contrarian read, said plainly. Many "agents" today are still chat-focused, not deeply woven into your workflows. You ask, it answers, you copy-paste. That's a smarter chatbot, not an autonomous teammate.
"Lots of clicking to get select the right options. UX needs improvement. Everything opens in a new browser tab." Verified User in Consulting Salesforce Agentforce G2 Verified Review
"Gong's lack of open task APIs limits system integration, making it difficult to connect with other essential tools." Verified User Gong G2 Verified Review
⭐ Which to choose, honestly
To be fair to the incumbents: Agentforce genuinely owns the Salesforce data fabric, and Gong's call-coaching depth is still excellent. Choose Gong if conversation intelligence is your core need. Choose Agentforce if you're deeply committed to Salesforce and have admin muscle.
Choose a deal-level agent like our deal-level revenue platform if your pain is the whole cycle, forecasting, pipeline movement, and follow-up, not just the call. The pilot trap is real: many deployments start full of promise and fade before production, so test in your own workflow before you commit budget.
Q8. What governance guardrails and autonomy levels keep agentic revenue work trustworthy? [toc=8. Governance & Autonomy Tiers]
The first time we let agents run loose on outbound, we learned something uncomfortable. One teammate had to spend 10 to 15 hours a week reviewing the outputs, because the agents work all night, every night. Autonomy without guardrails doesn't remove work. It just moves it.
Trustworthy agentic RevOps runs on bounded autonomy. Agents auto-execute low-risk work like dedupe, enrich, and route, draft medium-risk work for one-click approval like emails and forecast updates, and stay blocked from pricing, legal terms, and customer commitments. Around 73 percent of orgs already run AI in core GTM workflows, and the ones succeeding govern it with clear approval tiers, not blind trust.
⚖️ Pillar one: match autonomy to revenue risk
The governing idea is simple. The more a task touches money you'll report, the more a human stays in the loop.
Bounded autonomy keeps agentic RevOps trustworthy by matching how much freedom an agent gets to how much revenue risk a task carries.
Auto-run (low risk): data hygiene, enrichment, and lead routing. ✅
Draft for approval (medium risk): follow-up emails, and forecast updates. ⏰
Blocked (high risk): pricing, contract terms, and customer commitments. ❌
🧑💻 Pillar two: someone still reviews
Here's the honest "what we got wrong" moment. Agents that never sleep create a new review burden, and it's not a job for lazy people. The fix is a rhythm, not blind faith.
I lean on the 10/80/10 rule. Humans own the first 10 percent (the idea and the taste) and the last 10 percent (the quality check). The agent owns the 80 percent of heavy lifting in between. Pair that with a 30-day correction habit, where you spend an hour or two fixing the agent's mistakes daily, and by day 30 the output is genuinely good.
"Effectively crafting prompts and configuring the underlying actions demands a specific skill set often called prompt engineering." Alessandro N., Salesforce Administrator Salesforce Agentforce G2 Verified Review
"It still needs some serious debugging... could not get past an error when I clicked Create." Jessica C., Senior Business Analyst Salesforce Agentforce G2 Verified Review
🛡️ Pillar three: governance is now a buying criterion
Buyers increasingly screen for SOC 2 (a security audit standard), GDPR and CCPA (data-privacy laws), two-party consent for recording, and the EU AI Act's rules on autonomous agents. These aren't legal footnotes anymore. They decide which vendor clears procurement.
Our agentic revenue approach ships agent outputs as reviewable, deal-level one-pagers, so the human review tier the 10/80/10 rule requires is built in rather than bolted on. I could be early on this, but where my head is right now is that governance, not raw capability, becomes the real moat in the next two years.
Q9. Should mid-market B2B SaaS teams build their own RevOps agents or buy them? [toc=9. Build vs Buy]
A founder I respect once bragged to me that he was a top 1 percent Replit user, having shipped 12 internal apps in 150 days. Then he dropped the line that stuck with me. None of the go-to-market stuff, he said, did they build themselves. The guy who could build anything chose not to build this.
For most mid-market B2B SaaS teams, buy, don't build. Even top builders warn against building GTM agents in-house, because without dedicated go-to-market engineers they go obsolete in months. Build only where you have a true "zone of genius" edge. Buy the forecasting, routing, scoring, and hygiene agents that vendors already maintain and govern.
⚠️ The build scar tissue
Here's the contrarian truth the "just build it with AI" crowd skips. You're not Vercel. An internal agent build that isn't carefully maintained becomes obsolete in a couple of months as models move.
I've watched this in the wild, and it's almost funny. We did a call with a public B2B company worth over 10 billion dollars, the kind you'd assume is an AI leader. When we asked how much of their agent stack they'd built themselves, it was crickets on a call of 20 people. Nobody had done it.
💰 Build vs buy, decided on criteria
The decision isn't ideology. It's whether you have the engineering muscle and a real edge. Here's the rule of thumb I use.
Build vs Buy: Factor-by-Factor Signals
Decision factor
Build if...
Buy if...
GTM engineers
You have dedicated ones
You don't ✅
The workflow
It's your "zone of genius"
It's standard RevOps work
Maintenance
You can fund it forever
You want it to stay current ✅
Time to value
You can wait quarters
You need it this quarter
Model upgrades
You'll re-architect
Vendor handles it ✅
Operators feel the maintenance tax of even bought tools when setup runs deep, a friction that surfaces across comparisons of forecasting platforms:
"I find the setup process challenging, especially when migrating fields from Salesforce, as it can't handle formula fields directly." Josiah R., Head of Sales Operations Clari G2 Verified Review
The economics also reset the goalposts. The old target of 300,000 to 500,000 dollars of revenue per rep is giving way to 3 to 5 million per AI-leveraged rep. You don't hit that by paying engineers to maintain a forecasting bot.
A maintained, deal-level platform like our revenue intelligence platform is the buy-side answer for teams without GTM engineers, because the agents stay current as models change instead of decaying in your codebase. From what surfaces when you actually run this, the build-it dream usually ends as a maintenance bill nobody budgeted for.
Q10. Which RevOps agent should you pilot first, and how do you prove ROI in 90 days? [toc=10. 90-Day Pilot Playbook]
Here's the cheapest experiment in revenue, and almost nobody runs it. Open an incognito browser, go to your own product or process, and do everything a customer or rep does, start to finish. If you do this honestly, you're going to cry at some of what you find. Then pick the thing that made you cry the most, and go buy the agent that fixes it.
Pilot CRM hygiene first. It's low-risk, reversible, and unlocks every other agent by cleaning the data they depend on. Then layer routing, deal scoring, forecasting, and renewal. Prove ROI in 90 days by measuring hours reclaimed (15 to 20 a week on hygiene), forecast-variance drop, and cycle-time reduction.
⏰ The 90-day sequence
By the end of this, you'll have one agent in production and a number to show your board. Run it in order.
A low-risk-first 90-day pilot sequence takes teams from CRM hygiene to forecasting while building a board-ready ROI case.
Days 1 to 30, hygiene. Turn on dedupe and stale-record flagging. Expected outcome: hours reclaimed, and clean data for everything next. ✅
Days 30 to 60, routing and scoring. Auto-assign leads, and flag stalled deals. Expected outcome: faster SLA response, and fewer ghost deals. ⏰
Days 60 to 90, forecasting. Run the forecast call on live pipeline. Expected outcome: tighter variance, and a shorter Monday meeting. 💰
📊 The metrics that prove it worked
Don't measure vanity. A rep doing 300 calls to people who could never buy is a vanity metric, not progress. Track the numbers a CFO respects.
Hours reclaimed per week (target 15 to 20 on hygiene). ⭐
Forecast variance before and after the pilot.
Sales-cycle days saved (often around a week with AI).
Stalled deals caught before quarter-end.
A word on the skill that makes all this stick. The durable advantage isn't clever prompts, it's context engineering, loading the agent with everything about your business so your instructions can stay simple. Pair that with a 30-day correction habit, and the agent gets genuinely good by week four.
"Once set up and installed, Clari is very intuitive to use... it does a great job pulling in data from various sources." Rob W., Sr. Director of Revenue Operations Clari G2 Verified Review
That contrast is the whole game. Time-to-value, not feature count, decides whether a pilot reaches production. If the workflow that made you cry was forecast scrubs or follow-up stitching, that's the deal-level work our AI forecasting agents were built to run. So here's the question I'm sitting with, and I'd genuinely like your take: in two years, does the SaaS you log into quietly become the agents that work for you, turning revenue orchestration into revenue engineering? Tell me what's breaking in your pipeline right now, and I'll show you where an agent actually fits.
FAQ's
What are AI agents for RevOps and how are they different from copilots and note-takers?
AI agents for RevOps are autonomous software systems that execute multi-step revenue work, not just suggest it. They clean CRM records, score deals, route leads, and draft forecasts, then learn from your corrections.
The difference comes down to who does the work:
Note-takers only transcribe a call. They capture, they do not act.
Copilots answer when prompted. You still ship the work yourself.
Agents own a goal end to end, pull context across systems, and act overnight.
We like the vending machine analogy. Traditional automation is fixed input, fixed output. An agent behaves more like a smart employee that re-plans when blocked. When we rebuilt our own pipeline reviews on agentic workflows, the work shifted from gathering context to checking judgment. You can see how this plays out across full sales cycles in our breakdown of deal-level revenue intelligence platforms, which track the entire cycle rather than a single meeting.
Which RevOps AI agent should we pilot first to see ROI fastest?
We recommend piloting a CRM hygiene agent first. It is low-risk, reversible, and it unlocks every other agent by cleaning the data they depend on.
Here is the sequence we would run over 90 days:
Days 1 to 30: dedupe and flag stale records, reclaiming 15 to 20 hours a week.
Days 30 to 60: turn on lead routing and deal scoring.
Days 60 to 90: run forecasting on live pipeline.
Hygiene goes first because agents amplify bad data. If your records are messy, a scoring or forecasting agent simply scales the mess. A quick way to find your most painful workflow is the incognito test: do your own process start to finish and fix the step that frustrates you most. To prove ROI, measure hours reclaimed, forecast-variance drop, and sales-cycle days saved. For teams starting with the number that matters most to leadership, our guide to AI sales forecasting software shows where deal-level agents fit.
How accurate are AI forecasting agents and how much time do they actually save?
AI forecasting agents cut forecast variance from a typical 30 to 40 percent down to under 10 percent. Gartner treats 85 percent or higher as a healthy forecast-accuracy benchmark, with 90 percent plus for highly disciplined orgs.
The bigger win is time. Most managers spend one to two hours per rep every Thursday and Friday on the forecast scrub, then present stale numbers on Monday. A forecasting agent kills that ritual by pulling live pipeline movement.
A few benchmarks worth knowing:
69 percent of sellers using AI cut their sales cycle by about a week.
Daily AI users are roughly twice as likely to exceed quota.
We will add one honest hedge: these lifts assume clean inputs. Forecasting is a RevOps problem before it is a sales-discipline problem, since no agent rescues a forecast built on ghost deals. Speed matters too. Our deal-level approach updates within about five minutes of a call, which you can compare against legacy delays in our analysis of Gong forecasting.
Is Agentforce actually agentic, or is it just a smarter chatbot?
Agentforce is strong at the Salesforce data-fabric layer, but it remains largely chat-driven. A rep still has to go talk to the agent and move the output elsewhere, which is closer to a smarter chatbot than an autonomous teammate.
Here is how we frame the three approaches:
Agentforce: chat or task level, strong data fabric, high setup burden needing admins.
Deal-level agents: understand the full cycle and act inside the workflow.
To be fair, Agentforce genuinely owns the Salesforce data fabric and Gong's coaching depth is excellent. The right pick depends on your pain. Since recording is now commoditized by Zoom and Teams, the value has moved up to the agent layer. We dig into real user sentiment and trade-offs in our review of Salesforce Agentforce and our comparison of Gong versus deal-level agents.
Should mid-market B2B SaaS teams build their own RevOps agents or buy them?
For most mid-market B2B SaaS teams, we recommend buying rather than building. Even top builders warn against building go-to-market agents in-house, because without dedicated GTM engineers they go obsolete in months as models change.
Build only when both of these are true:
The workflow is a genuine zone-of-genius edge for your business.
You can fund ongoing maintenance and model upgrades forever.
Otherwise, buy the forecasting, routing, scoring, and hygiene agents that vendors already maintain and govern. The economics reinforce this: the old target of 300,000 to 500,000 dollars of revenue per rep is shifting toward 3 to 5 million per AI-leveraged rep, and you do not reach that by paying engineers to babysit a forecasting bot. A maintained platform stays current as models evolve instead of decaying in your codebase. See where this fits in our overview of revenue intelligence platforms built for teams without GTM engineers.
What governance guardrails keep agentic revenue work trustworthy?
Trustworthy agentic RevOps runs on bounded autonomy, which means matching how much freedom an agent gets to how much revenue risk the task carries.
We use three tiers:
Auto-run (low risk): data hygiene, enrichment, and lead routing.
Draft for approval (medium risk): follow-up emails, and forecast updates.
Blocked (high risk): pricing, contract terms, and customer commitments.
Around 73 percent of orgs already run AI in core go-to-market workflows, and the ones succeeding govern it with clear approval tiers rather than blind trust. One honest lesson: agents that never sleep create a new review burden, sometimes 10 to 15 hours a week. We lean on a 10/80/10 rhythm, where humans own the idea and the final quality check while the agent handles the heavy lifting. Buyers increasingly screen for SOC 2, GDPR, CCPA, and EU AI Act readiness too. We explain how this maps to the shift from revenue ops to orchestration.
How do deal scoring and renewal agents protect pipeline and revenue?
Deal scoring agents grade pipeline health continuously, flagging stalled or low-activity deals before they skew the forecast. Renewal agents score churn risk early, giving customer success a 90-day window instead of a two-week scramble.
Deal scoring watches the boring signals a human forgets:
No logged activity in 14 days.
Single-threaded with only one contact.
A close date pushed twice.
A simple, transparent churn model works better than a black box. For example, a query-volume drop greater than 50 percent adds 25 risk points, and zero queries for seven straight days adds 30 plus. Once an account crosses a threshold, it surfaces as an action, not just a red cell on a dashboard. That difference between alerting and acting is the whole point of agentic work. When both pipeline health and renewal risk run off the same deal-level context, a clean record improves the forecast and the churn score at once. See how this compares with point tools in our guide to the best AI sales tools.
Enjoyed the read? Join our founder for a quick 7-minute chat — no pitch, just a real conversation on how we’re rethinking RevOps with AI.
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields, all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions

.avif)
.png)








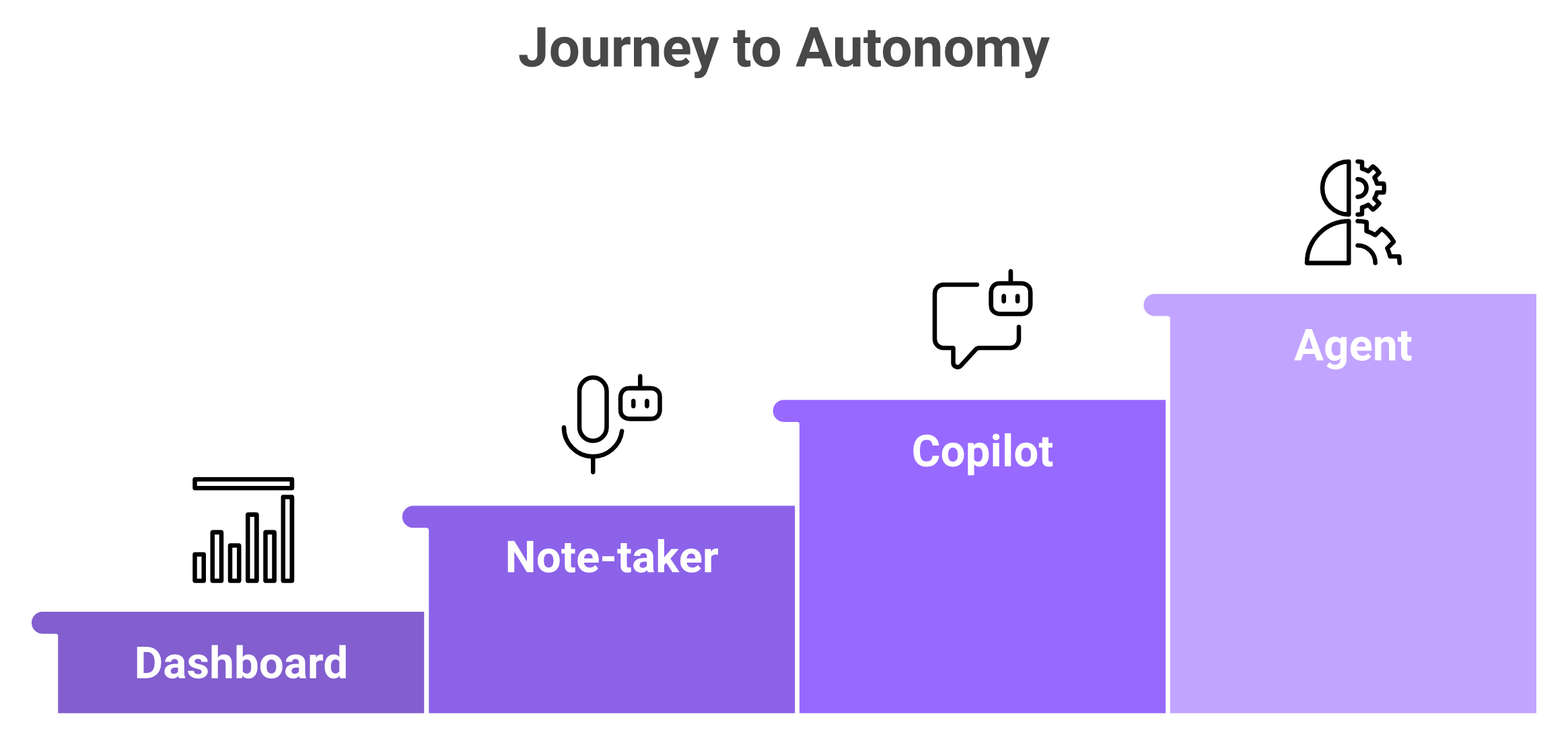

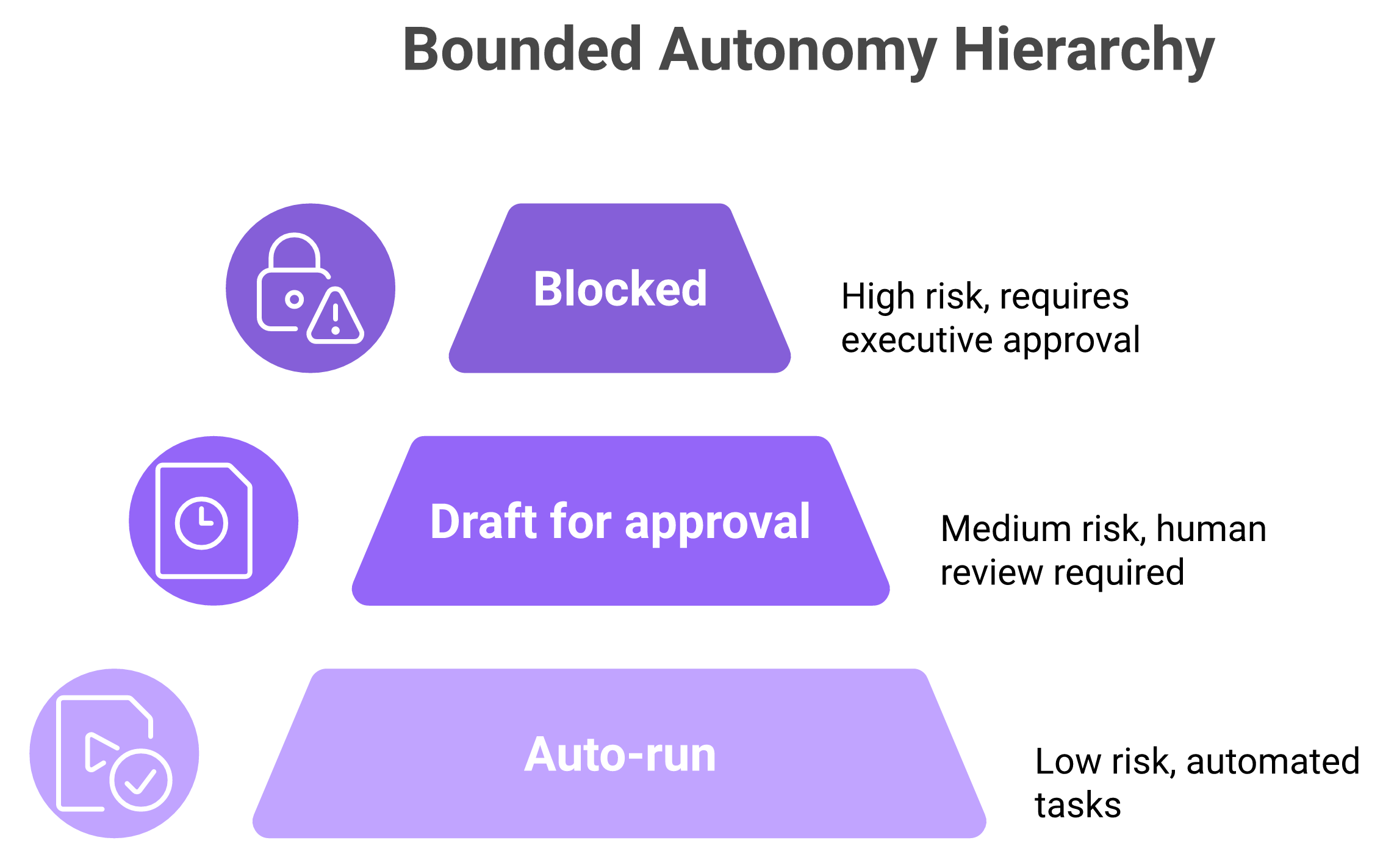


.png)
.png)
.png)
.png)

