Why Your Reps Won't Fill In MEDDIC Fields - And How to Auto-Score Them From Calls | CRM Agent
Written by
Ishan Chhabra
Last Updated :
March 5, 2026
Skim in :
18
mins
In this article
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions
TL;DR
Your reps won't fill in MEDDIC fields because data entry gives them zero value. The fix is not more training or more nagging. It is AI auto-scoring that extracts qualification data directly from sales calls.
76% of CRM data is unreliable; 37% of CRM users report direct revenue loss from poor data quality
AI auto-scoring uses contextual understanding (not keyword matching) to evaluate each MEDDIC criterion with evidence-linked confidence scores
Stage exit enforcement works best with flags (not hard blocks) that create coaching conversations rather than bottlenecks
Implementation: 5 minutes baseline vs 3-6 months for legacy platforms
TCO: $29/user/month (Oliv) vs $160-250/user + $5K+ platform fee (Gong)
How Oliv turns real sales conversations into fully auto-scored MEDDIC deal scorecards without manual CRM data entry.
I was running a pipe review last quarter when I noticed something that should have been obvious months earlier. Out of 47 active deals in our pipeline, 38 had MEDDIC fields that were either completely empty, filled with "TBD," or copy-pasted verbatim from the previous quarter's notes. One rep had the same Champion name listed on three different accounts, an account executive who had left the prospect company eight months ago.
That moment shifted something for me. The problem was not that our reps were lazy. It was not that they did not understand MEDDIC. The problem was that we had built a system that asked salespeople to do work that gave them nothing in return. We were running a methodology that depended on manual data entry from people whose entire compensation structure rewarded them for doing anything but data entry.
So we stopped asking reps to fill in MEDDIC fields. We started scoring them automatically from calls instead. Here is what we learned.
Why Do Sales Reps Refuse to Fill In MEDDIC Fields — And What Does It Actually Cost You? [toc=The Rep Resistance Problem]
Reps refuse to fill in MEDDIC fields because data entry provides zero immediate value to the person entering it. The rep's compensation, workflow, and daily priorities are disconnected from CRM hygiene. When qualification scoring requires switching from selling mode to database admin mode, reps rationally skip it, costing organizations 37% revenue loss from poor data quality and leaving forecast accuracy stuck at 60-70%.
The Switching Cost Nobody Talks About
Situation: Your sales team understands MEDDIC. They have been trained on it. They passed the certification quiz. They can recite the acronym in their sleep. And yet, when you pull up your pipeline dashboard, qualification fields are a wasteland.
Complication: This is not a training problem. It is a cognitive switching cost problem. When a rep finishes a 45-minute discovery call where they uncovered the prospect's pain, identified the economic buyer, and mapped the decision process, the last thing their brain wants to do is switch from relationship-building mode to database-admin mode. These are fundamentally different cognitive tasks.
Salesforce's State of Sales report found that reps spend only 35% of their time actually selling. Another 17% goes to fixing CRM entries. That is nearly one full day per week spent on data maintenance rather than revenue-generating activity.
The incentive misalignment makes it worse. Reps get paid on closed deals, not on CRM hygiene scores. When a rep has 30 minutes between calls, the rational choice is to prep for the next meeting, not to update MEDDIC fields that their manager might glance at during a weekly review. The system rewards the behavior it claims to discourage.
Resolution: The answer is not more training, more reminders, or more fields. The answer is removing the dependency entirely. If qualification data can be extracted from conversations that reps are already having, the compliance problem disappears. Not because reps decided to care about data entry, but because data entry is no longer required.
What Empty Fields Actually Cost Your Pipeline
The consequences of empty MEDDIC fields compound faster than most sales leaders realize.
A Kixie analysis of CRM usage data found that 76% of CRM users report less than half of their data is accurate. When three-quarters of your database is unreliable, every downstream process built on that data is compromised.
Pipeline reviews become fiction workshops. Without reliable qualification data, managers cannot distinguish between a deal that genuinely has executive sponsorship and one where the rep is hoping the CFO will show up. The weekly pipe review degenerates into "tell me the story of this deal" rather than "show me the evidence."
Forecast accuracy suffers directly. Industry data shows that organizations without systematic qualification enforcement achieve 60-70% forecast accuracy at best. Only 7% of sales orgs reach 90%+ accuracy, and almost none of them are relying on manually entered CRM data to get there.
The MEDDIC vs MEDDPICC vs BANT debate misses the point entirely. Some teams agonize over which framework to adopt. Should we add the extra P for Paper Process? Should we switch to SPICED? But the framework choice is irrelevant if nobody is populating the fields. A perfectly designed qualification rubric that sits empty in Salesforce is no better than having no rubric at all.
The core insight is this: methodology compliance is a design problem, not a people problem. You do not solve it by lecturing reps harder. You solve it by designing systems where compliance is a byproduct of work reps are already doing.
"Understanding the pipeline management portion of it is almost impossible. Some people figure it out, but I think most just fumble through and tell tall tales about how easy it is for them to use." - John S., Senior Account Executive | Gong G2 Review
From partial, inconsistent MEDDIC scorecards to 90%+ completion when scoring is automated from calls.”
How Does AI Auto-Score MEDDIC Criteria From Sales Calls Without Rep Input? [toc=How Auto-Scoring Works]
AI auto-scoring analyzes call transcripts to evaluate each MEDDIC criterion using contextual understanding rather than keyword matching. The system extracts evidence moments, assigns confidence scores per criterion, and writes results back to CRM fields automatically, eliminating manual data entry while producing more accurate qualification data than reps typically provide.
Keyword Matching vs Contextual Scoring
There is a fundamental difference between detecting that someone mentioned the words "Chief Financial Officer" on a call and understanding whether the Economic Buyer was actually validated.
First-generation tools like Gong's Smart Trackers operate on keyword and phrase pattern matching. You configure a tracker for "Economic Buyer" by specifying terms like "CFO," "budget holder," "final approver." When those terms appear in a transcript, the tracker fires. This is useful for basic visibility but creates two problems.
False positives flood the system. A rep saying "we need to figure out who the CFO is" triggers the same tracker as "the CFO confirmed she has budget authority for this quarter." Both register as "Economic Buyer discussed." Neither tells you whether the criterion was actually satisfied.
Setting up these trackers is itself a burden.
"It can be overwhelming to set up trackers. AI training is a bit laborious to get it to do what you want." - Trafford J., Senior Director of Revenue Enablement | Gong G2 Review
You are trading one manual process (reps filling in fields) for another (RevOps configuring and maintaining trackers).
Native AI scoring takes a different approach. Instead of matching keywords, it analyzes the conversational context to determine whether qualification criteria were genuinely addressed. The AI understands that "our VP of Finance mentioned she would need to sign off" is a Champion validation signal, while "I wonder who handles the budget over there" is not.
What a MEDDIC Scoring Rubric Actually Looks Like
A practical auto-scoring rubric evaluates each MEDDIC criterion on a multi-level scale. Here is what that looks like in practice:
MEDDIC Auto-Scoring Rubric: Scoring Levels Per Criterion
Criterion
Score 0
Score 1
Score 2
Score 3
M - Metrics
No business impact discussed
General pain mentioned
Specific metrics identified
Metrics tied to executive-validated outcome
E - Economic Buyer
Unknown or not discussed
Name mentioned, role unconfirmed
Identified with budget authority
Engaged in sales process
D - Decision Criteria
Not discussed
General requirements mentioned
Specific criteria documented
Criteria mapped with solution alignment
D - Decision Process
Unknown
Vague timeline only
Steps and stakeholders identified
Full process mapped with dates
I - Identify Pain
No pain articulated
Surface-level pain
Specific pain with business impact
Pain acknowledged at executive level
C - Champion
No advocate identified
Friendly contact, no influence
Champion with access to power
Actively selling internally
At Oliv AI, the CRM Manager Agent applies this rubric automatically across every recorded interaction. The scoring is not based on a single call but accumulated across the full deal lifecycle. A deal might score a 1 on Economic Buyer after the first discovery call, then upgrade to a 3 after the champion confirms executive engagement in a follow-up. Each score change links to the specific conversation moment that triggered it.
The Evidence Trail That Changes Everything
The most undervalued aspect of auto-scoring is the evidence trail. Every score is linked to a timestamped moment in the call recording where the relevant criterion was discussed.
When a manager sees that Deal XYZ has a Champion score of 2, they can click through to the exact 37-second clip where the prospect said "I will present this to our leadership team next Thursday." This transforms pipeline reviews from opinion debates into evidence-based discussions.
This matters because it changes the coaching conversation. Instead of "do you have a champion?" the manager asks "your champion score dropped from 2 to 1 this week, what happened in Wednesday's call?" The AI provides the context. The manager provides the strategy. The rep stops feeling interrogated and starts feeling supported.
The scoring also works across multiple frameworks simultaneously. The same conversation engine that evaluates MEDDIC criteria can score MEDDPICC (adding Paper Process and Competition), BANT (Budget, Authority, Need, Timeline), SPICED, or a fully custom framework. We built the engine to support 100+ sales methodologies natively because most teams use hybrid approaches rather than textbook implementations.
How Do You Enforce Stage Exit Criteria Without Creating a Bottleneck for Your Sales Team? [toc=Stage Exit Enforcement]
Stage exit criteria enforcement works by setting minimum qualification thresholds that must be met before a deal advances in your pipeline. When powered by auto-scoring, this happens invisibly. Deals are flagged rather than blocked, and managers receive alerts with specific evidence gaps to address in their next 1:1. The result is methodology compliance without manual gates or bureaucratic bottlenecks.
Flags, Not Blocks
The instinct when implementing stage exit criteria is to build hard gates. Deal cannot move from Stage 2 to Stage 3 unless MEDDIC score exceeds 12. This feels satisfying from a process design perspective but creates immediate problems in practice.
Hard blocks frustrate reps who have legitimate reasons for advancing deals. Not every deal follows a textbook qualification sequence. A prospect might skip straight to a technical evaluation before the rep has confirmed the Economic Buyer. Blocking that deal from advancing punishes the rep for the prospect's buying behavior.
The better approach is soft enforcement through flagging. When a deal advances without meeting minimum qualification thresholds, it gets flagged, not blocked. The manager receives an alert: "Deal XYZ moved to Stage 3 with Economic Buyer score of 0. Evidence gap: no executive contact identified in 4 recorded interactions."
This creates accountability without friction. The rep can advance the deal, but the flag becomes a coaching item in the next 1:1. The manager now has a specific, evidence-backed question to ask rather than a general "how's this deal going?"
"I have to maintain my own separate spreadsheet to track deals because I can only capture what my leaders want to see about a deal (revenue, close date, etc.) and as a rep, I need to have fields like product interest, last activity notes, key contacts, deal challenges or blockers." - Verified User, Enterprise | G2 Review of Clari
The Pipeline Accuracy Loop
Auto-scoring and stage exit enforcement create a reinforcing loop that improves pipeline accuracy over time.
When qualification criteria are scored automatically, managers can trust the pipeline data without manually verifying each deal. This means forecast calls shift from "let me hear the story of each deal" to "let me look at the exceptions." Instead of reviewing 50 deals in a pipeline review, the manager focuses on the 8 deals that have qualification gaps or score anomalies.
This is where the downstream effects compound. Better qualification data produces more accurate forecasts. More accurate forecasts produce better resource allocation decisions. Better resource allocation means reps spend time on deals that are actually qualified rather than chasing prospects who were never going to close.
The manager time savings are substantial. When deal qualification is pre-triaged by AI, managers report spending 50% less time on routine deal reviews. That time gets reinvested into strategic coaching, helping reps navigate complex deals rather than auditing whether they filled in a form.
At Oliv, the Deal Driver Agent feeds auto-scored data into daily deal intelligence summaries that go directly to manager inboxes. The agent identifies which deals need attention today based on qualification gaps, stalled progression, and competitive risk signals. Managers open their morning coffee email and immediately know which three deals to focus on, without clicking through a single dashboard.
The CRM hygiene improvement is a bonus effect. When qualification data flows automatically from conversations to CRM fields, the data quality problem that plagues most organizations solves itself. You do not need a quarterly "CRM cleanup sprint" when the data is continuously updated from the source of truth, actual sales conversations.
This creates a fundamentally different relationship between reps and their CRM. Instead of the CRM being a tax they pay for the privilege of selling, it becomes a living record that works for them. When a rep opens a deal record and sees accurate, auto-populated qualification data with evidence links, the CRM transforms from a management surveillance tool into a personal deal intelligence dashboard.
How Does Gong Score MEDDIC Compared to Native AI Scoring Platforms Like Oliv? [toc=Gong vs Native Scoring]
Gong uses Smart Trackers, keyword-based pattern matching that detects when MEDDIC-related terms are mentioned in calls. Native AI scoring goes deeper, analyzing conversational context to determine whether qualification criteria were actually validated, not just mentioned. The difference is detecting "CFO was discussed" versus confirming "the CFO has budget authority and has agreed to sponsor the deal."
What Smart Trackers Actually Detect
Gong's Smart Trackers work by scanning call transcripts for predefined keywords and phrases. You set up a tracker for each MEDDIC criterion, for example, mapping terms like "budget," "funding," "financial approval" to the Economic Buyer category. When those terms appear in a call, the tracker flags it.
This approach has clear strengths. It gives managers basic visibility into whether reps are covering qualification topics at all. For teams moving from zero methodology tracking to some visibility, Smart Trackers are a meaningful step up.
But the limitations are structural, not bugs to be fixed.
First, keyword matching cannot distinguish between mentioning a concept and validating it. "We need to find out who owns the budget" and "the VP of Finance confirmed a $200K allocation for Q3" both trigger an Economic Buyer tracker. The nuance, one is an open question, the other is a validated criterion, is invisible to pattern matching.
Second, the setup burden is real. Every tracker needs to be configured, tested, and maintained. When your sales methodology evolves or your market language shifts, trackers need manual updates.
"AI is not great (yet) - the product still feels like its at its infancy and needs to be developed further." - Annabelle H., Voluntary Director | G2 Review of Gong
Third, Gong's scoring operates at the meeting level, not the deal level. Each call gets evaluated independently. But MEDDIC qualification is a cumulative process. You might identify the pain in call one, validate the champion in call two, and confirm the decision process in call three. Meeting-level scoring misses this progression.
"The platform lacks task APIs, does not integrate with other vendors or parallel dialers, and isn't built to function as a proper sequencing tool. Gong is strong at conversation intelligence, but that's where its usefulness ends." - Sigma | G2 Review of Gong
The Comparison Table You Need
MEDDIC Scoring Tool Comparison: Gong vs Clari vs Oliv AI
"Not great for small/startup teams - way too expensive when there are more affordable tools that work. We're stuck with a tool that works technically but isn't the right business decision." - Iris P., Head of Marketing, Sales & Partnerships | G2 Review of Gong
Clari occupies a different space entirely. It is a forecasting and pipeline management tool, not a methodology scoring engine.
"It is really just a glorified SFDC overlay. Salesforce has built most of the forecasting functionality by now anyway so I'm not sure where they fit." - conaldinho11, Former Employee | Reddit r/SalesOperations
That assessment may be blunt, but it reflects the reality that Clari does not solve the MEDDIC compliance problem. If your qualification data is empty in Salesforce, it will be equally empty in Clari.
Other tools in this space, Avoma, Demodesk, and Pepsales, offer various levels of MEDDIC scoring. Avoma provides scorecard features within its conversation intelligence platform. Demodesk focuses on real-time coaching with methodology tracking. Pepsales positions as an AI-powered qualification tool. Each addresses a piece of the puzzle, but none provide the full deal-level, multi-source, autonomous scoring that an agentic architecture delivers.
What ROI Can You Expect From Automated MEDDIC Scoring in the First 90 Days? [toc=Auto-Scoring ROI]
Teams implementing MEDDIC auto-scoring report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. Implementation typically takes 5 minutes for baseline setup with full value realized in 1-2 weeks, compared to 3-6 month deployments for legacy platforms.
The Three ROI Levers
Auto-scoring generates return through three distinct mechanisms that compound over time.
Lever 1: Forecast accuracy improvement. When qualification data is objective, continuous, and evidence-based rather than subjective, sporadic, and self-reported, the forecast inputs improve. Better inputs produce better outputs. Organizations that implement systematic qualification scoring report moving from the industry-average 60-70% forecast accuracy toward the 80-90% range. Given that only 7% of sales orgs reach 90%+ accuracy, the improvement opportunity is massive for most teams.
This translates directly to revenue confidence. A VP of Sales presenting a forecast to the board with auto-scored qualification data is presenting verified intelligence, not compiled opinions. That changes the board conversation from "why did you miss?" to "here is what the data shows and here is how we are responding."
Lever 2: Manager time recovery. The average sales manager spends 6-8 hours per week on deal reviews and pipeline auditing. Much of this time is spent gathering basic qualification information that should already be in the system. When auto-scoring pre-triages deals and flags qualification gaps automatically, managers recover 50% or more of that time.
Recovered time goes to high-value activities. Instead of asking "do you have a champion?" a manager with auto-scored data asks "your champion engagement dropped this week, let us strategize about re-engagement." That is the difference between auditing and coaching. The coaching conversation drives better deal outcomes. The auditing conversation drives resentment.
Lever 3: Deal velocity through early disqualification. The most expensive deals in your pipeline are the ones that should have been disqualified three months ago. When qualification scoring happens automatically and continuously, deals with fundamental gaps get surfaced early. A deal with no identified Economic Buyer after four meetings is not a pipeline opportunity. It is a time sink.
Teams with auto-scoring report 15-30% shorter average sales cycles. Not because deals close faster in absolute terms, but because unqualified deals get removed from the pipeline sooner, reducing the average. The remaining pipeline is healthier, more predictable, and more deserving of the resources invested in it.
What Implementation Actually Looks Like
Legacy platforms come with implementation timelines measured in months. Gong implementations typically involve 4-6 weeks of configuration, data migration, tracker setup, and training. Clari deployments require mapping forecast hierarchies and Salesforce field configurations that can stretch to 3-6 months for complex organizations.
At Oliv, baseline setup takes 5 minutes. Connect your calendar, authorize CRM access, and the system starts recording and scoring from day one. The CRM Manager Agent begins populating MEDDIC fields from the first call it processes. Custom scoring rubrics and stage exit thresholds take an additional 2-4 weeks to calibrate, but value delivery starts immediately.
The TCO comparison makes the ROI case even stronger. A 100-rep organization running Gong plus Clari pays $500+ per user per month, roughly $600,000 annually. The same organization on Oliv's platform pays $29-39 per user per month for the full agent suite, totaling $35,000-47,000 annually. The delta exceeds half a million dollars per year before accounting for the productivity gains.
"The pricing is probably the biggest obstacle and hence we are looking to change." - Miodrag, Enterprise Account Executive | Gong Review
When the CFO reviews the line item and sees 91% potential cost reduction with equal or superior functionality, the business case writes itself.
How Do You Implement MEDDIC Auto-Scoring in Your Sales Org Without Disrupting Live Deals? [toc=Implementation Playbook]
Implementing MEDDIC auto-scoring requires four steps: define your scoring rubric per MEDDIC criterion, configure stage exit thresholds, run a 2-week parallel scoring test against manual reviews, and roll out with manager coaching playbooks that use auto-scores as 1:1 conversation starters. The key is framing auto-scoring as rep enablement, not surveillance.
Oliv enforces MEDDIC across four touchpoints, turning the framework from a one‑time training into a continuous operating system.
The Four-Step Rollout
Step 1: Define your scoring rubric. Before you turn on any tool, align your leadership team on what "good" looks like for each MEDDIC criterion. The rubric earlier in this article is a starting template, but your organization's specific deal dynamics should shape the definitions.
Key question to answer: at what score level does each criterion count as "satisfied" for pipeline progression? Most teams set the threshold at score 2 (validated) rather than score 3 (fully confirmed with executive engagement). Setting the bar too high creates false negatives. Setting it too low defeats the purpose.
Step 2: Configure stage exit thresholds. Map minimum qualification scores to each pipeline stage. A common structure:
These thresholds are flags, not blocks. Deals that advance without meeting thresholds get flagged for manager review rather than prevented from moving.
Step 3: Run a 2-week parallel scoring test. Before full rollout, run the auto-scoring system alongside your existing process. Have managers manually score 10-15 deals using the same rubric. Compare auto-scores against manager judgment.
This step serves two purposes. First, it calibrates the AI. If auto-scores consistently differ from manager judgment on specific criteria, you may need to adjust rubric definitions or scoring sensitivity. Second, it builds manager trust. Managers who see the AI accurately reflecting their own assessment become advocates rather than skeptics.
Enablement, Not Surveillance
Step 4: Roll out with coaching playbooks. The rollout message matters. If you announce "we are implementing AI scoring to monitor qualification compliance," you will face resistance. If you announce "we are giving managers better data so your 1:1s focus on strategy instead of CRM auditing," you get adoption.
Create a coaching playbook that shows managers exactly how to use auto-scores in their weekly 1:1s:
The single biggest predictor of auto-scoring adoption is framing. Reps who perceive scoring as surveillance resist it. Reps who perceive scoring as removing busywork embrace it.
Make the value exchange explicit. Auto-scoring eliminates the MEDDIC form. That Salesforce lightning component with six mandatory fields that reps hate filling out? Gone. The qualification data is populated automatically from conversations they are already having. The AI does the data entry. The rep does the selling.
When reps see their own deal scorecards updating without any action on their part, the response shifts from "Big Brother is watching" to "finally, a tool that does something useful." The deal scorecard becomes a personal dashboard, a way for the rep to see their own qualification gaps before the manager does, and to proactively address them.
"I would like easier access to training to enable me to better Forecast, pull data and access dashboards. As it stands I have had no training." - Edwin M., Senior Director | G2 Review of Clari
The common pitfalls are predictable and avoidable. Do not over-automate by removing all manual override capability. Do not ignore rep feedback about scoring accuracy in the first 30 days. Do not launch without calibrating scores against manager judgment first. And do not use auto-scores as punitive metrics. They are coaching inputs, not performance grades.
Frequently Asked Questions [toc=FAQs]
What is MEDDIC auto-scoring?
MEDDIC auto-scoring uses AI to analyze sales call transcripts and automatically evaluate each qualification criterion, Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion, without requiring manual input from sales reps.
Can AI accurately score MEDDIC from call recordings?
Yes. Modern AI analyzes conversational context rather than just keywords. It achieves higher accuracy than manual scoring because it evaluates every interaction consistently, without human bias, fatigue, or the tendency to skip fields under time pressure.
Which is better for MEDDIC scoring, Gong or Oliv AI?
Gong uses keyword-based Smart Trackers that detect when MEDDIC-related terms are mentioned. Oliv AI uses contextual AI that evaluates whether criteria were actually validated, provides evidence links and confidence scores, and operates at 91% lower cost per user.
How long does it take to implement MEDDIC auto-scoring?
With AI-native platforms like Oliv, baseline setup takes 5 minutes. Core value is realized in 1-2 days. Full customization including stage exit criteria and coaching workflows takes 2-4 weeks. Legacy platforms typically require 3-6 months.
Does MEDDIC auto-scoring work with MEDDPICC and BANT?
Yes. Leading auto-scoring platforms support multiple methodologies simultaneously. Oliv AI is trained on 100+ sales methodologies, scoring whichever framework your team uses, including custom hybrid approaches.
Will auto-scoring replace manual deal reviews?
Auto-scoring augments deal reviews rather than replacing them. It pre-triages deals so managers spend their review time on strategic coaching rather than basic qualification verification. Managers report 50%+ time savings on routine pipeline audits.
What ROI can I expect from MEDDIC auto-scoring?
Teams report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. TCO savings of up to 91% compared to Gong-plus-Clari stacks.
How do I get reps to adopt MEDDIC auto-scoring?
Frame it as removing work, not adding surveillance. Auto-scoring eliminates the manual MEDDIC form that reps resent filling out. When reps see accurate qualification data appearing without any effort on their part, adoption follows naturally.
The gap between scoring and coaching is closing faster than most people realize. Auto-scoring today is retrospective, but the next wave will be predictive and prescriptive. The endgame is not "did you fill in the field?" It is "did the conversation advance qualification, and here is what to do next."
How Oliv turns real sales conversations into fully auto-scored MEDDIC deal scorecards without manual CRM data entry.
I was running a pipe review last quarter when I noticed something that should have been obvious months earlier. Out of 47 active deals in our pipeline, 38 had MEDDIC fields that were either completely empty, filled with "TBD," or copy-pasted verbatim from the previous quarter's notes. One rep had the same Champion name listed on three different accounts, an account executive who had left the prospect company eight months ago.
That moment shifted something for me. The problem was not that our reps were lazy. It was not that they did not understand MEDDIC. The problem was that we had built a system that asked salespeople to do work that gave them nothing in return. We were running a methodology that depended on manual data entry from people whose entire compensation structure rewarded them for doing anything but data entry.
So we stopped asking reps to fill in MEDDIC fields. We started scoring them automatically from calls instead. Here is what we learned.
Why Do Sales Reps Refuse to Fill In MEDDIC Fields — And What Does It Actually Cost You? [toc=The Rep Resistance Problem]
Reps refuse to fill in MEDDIC fields because data entry provides zero immediate value to the person entering it. The rep's compensation, workflow, and daily priorities are disconnected from CRM hygiene. When qualification scoring requires switching from selling mode to database admin mode, reps rationally skip it, costing organizations 37% revenue loss from poor data quality and leaving forecast accuracy stuck at 60-70%.
The Switching Cost Nobody Talks About
Situation: Your sales team understands MEDDIC. They have been trained on it. They passed the certification quiz. They can recite the acronym in their sleep. And yet, when you pull up your pipeline dashboard, qualification fields are a wasteland.
Complication: This is not a training problem. It is a cognitive switching cost problem. When a rep finishes a 45-minute discovery call where they uncovered the prospect's pain, identified the economic buyer, and mapped the decision process, the last thing their brain wants to do is switch from relationship-building mode to database-admin mode. These are fundamentally different cognitive tasks.
Salesforce's State of Sales report found that reps spend only 35% of their time actually selling. Another 17% goes to fixing CRM entries. That is nearly one full day per week spent on data maintenance rather than revenue-generating activity.
The incentive misalignment makes it worse. Reps get paid on closed deals, not on CRM hygiene scores. When a rep has 30 minutes between calls, the rational choice is to prep for the next meeting, not to update MEDDIC fields that their manager might glance at during a weekly review. The system rewards the behavior it claims to discourage.
Resolution: The answer is not more training, more reminders, or more fields. The answer is removing the dependency entirely. If qualification data can be extracted from conversations that reps are already having, the compliance problem disappears. Not because reps decided to care about data entry, but because data entry is no longer required.
What Empty Fields Actually Cost Your Pipeline
The consequences of empty MEDDIC fields compound faster than most sales leaders realize.
A Kixie analysis of CRM usage data found that 76% of CRM users report less than half of their data is accurate. When three-quarters of your database is unreliable, every downstream process built on that data is compromised.
Pipeline reviews become fiction workshops. Without reliable qualification data, managers cannot distinguish between a deal that genuinely has executive sponsorship and one where the rep is hoping the CFO will show up. The weekly pipe review degenerates into "tell me the story of this deal" rather than "show me the evidence."
Forecast accuracy suffers directly. Industry data shows that organizations without systematic qualification enforcement achieve 60-70% forecast accuracy at best. Only 7% of sales orgs reach 90%+ accuracy, and almost none of them are relying on manually entered CRM data to get there.
The MEDDIC vs MEDDPICC vs BANT debate misses the point entirely. Some teams agonize over which framework to adopt. Should we add the extra P for Paper Process? Should we switch to SPICED? But the framework choice is irrelevant if nobody is populating the fields. A perfectly designed qualification rubric that sits empty in Salesforce is no better than having no rubric at all.
The core insight is this: methodology compliance is a design problem, not a people problem. You do not solve it by lecturing reps harder. You solve it by designing systems where compliance is a byproduct of work reps are already doing.
"Understanding the pipeline management portion of it is almost impossible. Some people figure it out, but I think most just fumble through and tell tall tales about how easy it is for them to use." - John S., Senior Account Executive | Gong G2 Review
From partial, inconsistent MEDDIC scorecards to 90%+ completion when scoring is automated from calls.”
How Does AI Auto-Score MEDDIC Criteria From Sales Calls Without Rep Input? [toc=How Auto-Scoring Works]
AI auto-scoring analyzes call transcripts to evaluate each MEDDIC criterion using contextual understanding rather than keyword matching. The system extracts evidence moments, assigns confidence scores per criterion, and writes results back to CRM fields automatically, eliminating manual data entry while producing more accurate qualification data than reps typically provide.
Keyword Matching vs Contextual Scoring
There is a fundamental difference between detecting that someone mentioned the words "Chief Financial Officer" on a call and understanding whether the Economic Buyer was actually validated.
First-generation tools like Gong's Smart Trackers operate on keyword and phrase pattern matching. You configure a tracker for "Economic Buyer" by specifying terms like "CFO," "budget holder," "final approver." When those terms appear in a transcript, the tracker fires. This is useful for basic visibility but creates two problems.
False positives flood the system. A rep saying "we need to figure out who the CFO is" triggers the same tracker as "the CFO confirmed she has budget authority for this quarter." Both register as "Economic Buyer discussed." Neither tells you whether the criterion was actually satisfied.
Setting up these trackers is itself a burden.
"It can be overwhelming to set up trackers. AI training is a bit laborious to get it to do what you want." - Trafford J., Senior Director of Revenue Enablement | Gong G2 Review
You are trading one manual process (reps filling in fields) for another (RevOps configuring and maintaining trackers).
Native AI scoring takes a different approach. Instead of matching keywords, it analyzes the conversational context to determine whether qualification criteria were genuinely addressed. The AI understands that "our VP of Finance mentioned she would need to sign off" is a Champion validation signal, while "I wonder who handles the budget over there" is not.
What a MEDDIC Scoring Rubric Actually Looks Like
A practical auto-scoring rubric evaluates each MEDDIC criterion on a multi-level scale. Here is what that looks like in practice:
MEDDIC Auto-Scoring Rubric: Scoring Levels Per Criterion
Criterion
Score 0
Score 1
Score 2
Score 3
M - Metrics
No business impact discussed
General pain mentioned
Specific metrics identified
Metrics tied to executive-validated outcome
E - Economic Buyer
Unknown or not discussed
Name mentioned, role unconfirmed
Identified with budget authority
Engaged in sales process
D - Decision Criteria
Not discussed
General requirements mentioned
Specific criteria documented
Criteria mapped with solution alignment
D - Decision Process
Unknown
Vague timeline only
Steps and stakeholders identified
Full process mapped with dates
I - Identify Pain
No pain articulated
Surface-level pain
Specific pain with business impact
Pain acknowledged at executive level
C - Champion
No advocate identified
Friendly contact, no influence
Champion with access to power
Actively selling internally
At Oliv AI, the CRM Manager Agent applies this rubric automatically across every recorded interaction. The scoring is not based on a single call but accumulated across the full deal lifecycle. A deal might score a 1 on Economic Buyer after the first discovery call, then upgrade to a 3 after the champion confirms executive engagement in a follow-up. Each score change links to the specific conversation moment that triggered it.
The Evidence Trail That Changes Everything
The most undervalued aspect of auto-scoring is the evidence trail. Every score is linked to a timestamped moment in the call recording where the relevant criterion was discussed.
When a manager sees that Deal XYZ has a Champion score of 2, they can click through to the exact 37-second clip where the prospect said "I will present this to our leadership team next Thursday." This transforms pipeline reviews from opinion debates into evidence-based discussions.
This matters because it changes the coaching conversation. Instead of "do you have a champion?" the manager asks "your champion score dropped from 2 to 1 this week, what happened in Wednesday's call?" The AI provides the context. The manager provides the strategy. The rep stops feeling interrogated and starts feeling supported.
The scoring also works across multiple frameworks simultaneously. The same conversation engine that evaluates MEDDIC criteria can score MEDDPICC (adding Paper Process and Competition), BANT (Budget, Authority, Need, Timeline), SPICED, or a fully custom framework. We built the engine to support 100+ sales methodologies natively because most teams use hybrid approaches rather than textbook implementations.
How Do You Enforce Stage Exit Criteria Without Creating a Bottleneck for Your Sales Team? [toc=Stage Exit Enforcement]
Stage exit criteria enforcement works by setting minimum qualification thresholds that must be met before a deal advances in your pipeline. When powered by auto-scoring, this happens invisibly. Deals are flagged rather than blocked, and managers receive alerts with specific evidence gaps to address in their next 1:1. The result is methodology compliance without manual gates or bureaucratic bottlenecks.
Flags, Not Blocks
The instinct when implementing stage exit criteria is to build hard gates. Deal cannot move from Stage 2 to Stage 3 unless MEDDIC score exceeds 12. This feels satisfying from a process design perspective but creates immediate problems in practice.
Hard blocks frustrate reps who have legitimate reasons for advancing deals. Not every deal follows a textbook qualification sequence. A prospect might skip straight to a technical evaluation before the rep has confirmed the Economic Buyer. Blocking that deal from advancing punishes the rep for the prospect's buying behavior.
The better approach is soft enforcement through flagging. When a deal advances without meeting minimum qualification thresholds, it gets flagged, not blocked. The manager receives an alert: "Deal XYZ moved to Stage 3 with Economic Buyer score of 0. Evidence gap: no executive contact identified in 4 recorded interactions."
This creates accountability without friction. The rep can advance the deal, but the flag becomes a coaching item in the next 1:1. The manager now has a specific, evidence-backed question to ask rather than a general "how's this deal going?"
"I have to maintain my own separate spreadsheet to track deals because I can only capture what my leaders want to see about a deal (revenue, close date, etc.) and as a rep, I need to have fields like product interest, last activity notes, key contacts, deal challenges or blockers." - Verified User, Enterprise | G2 Review of Clari
The Pipeline Accuracy Loop
Auto-scoring and stage exit enforcement create a reinforcing loop that improves pipeline accuracy over time.
When qualification criteria are scored automatically, managers can trust the pipeline data without manually verifying each deal. This means forecast calls shift from "let me hear the story of each deal" to "let me look at the exceptions." Instead of reviewing 50 deals in a pipeline review, the manager focuses on the 8 deals that have qualification gaps or score anomalies.
This is where the downstream effects compound. Better qualification data produces more accurate forecasts. More accurate forecasts produce better resource allocation decisions. Better resource allocation means reps spend time on deals that are actually qualified rather than chasing prospects who were never going to close.
The manager time savings are substantial. When deal qualification is pre-triaged by AI, managers report spending 50% less time on routine deal reviews. That time gets reinvested into strategic coaching, helping reps navigate complex deals rather than auditing whether they filled in a form.
At Oliv, the Deal Driver Agent feeds auto-scored data into daily deal intelligence summaries that go directly to manager inboxes. The agent identifies which deals need attention today based on qualification gaps, stalled progression, and competitive risk signals. Managers open their morning coffee email and immediately know which three deals to focus on, without clicking through a single dashboard.
The CRM hygiene improvement is a bonus effect. When qualification data flows automatically from conversations to CRM fields, the data quality problem that plagues most organizations solves itself. You do not need a quarterly "CRM cleanup sprint" when the data is continuously updated from the source of truth, actual sales conversations.
This creates a fundamentally different relationship between reps and their CRM. Instead of the CRM being a tax they pay for the privilege of selling, it becomes a living record that works for them. When a rep opens a deal record and sees accurate, auto-populated qualification data with evidence links, the CRM transforms from a management surveillance tool into a personal deal intelligence dashboard.
How Does Gong Score MEDDIC Compared to Native AI Scoring Platforms Like Oliv? [toc=Gong vs Native Scoring]
Gong uses Smart Trackers, keyword-based pattern matching that detects when MEDDIC-related terms are mentioned in calls. Native AI scoring goes deeper, analyzing conversational context to determine whether qualification criteria were actually validated, not just mentioned. The difference is detecting "CFO was discussed" versus confirming "the CFO has budget authority and has agreed to sponsor the deal."
What Smart Trackers Actually Detect
Gong's Smart Trackers work by scanning call transcripts for predefined keywords and phrases. You set up a tracker for each MEDDIC criterion, for example, mapping terms like "budget," "funding," "financial approval" to the Economic Buyer category. When those terms appear in a call, the tracker flags it.
This approach has clear strengths. It gives managers basic visibility into whether reps are covering qualification topics at all. For teams moving from zero methodology tracking to some visibility, Smart Trackers are a meaningful step up.
But the limitations are structural, not bugs to be fixed.
First, keyword matching cannot distinguish between mentioning a concept and validating it. "We need to find out who owns the budget" and "the VP of Finance confirmed a $200K allocation for Q3" both trigger an Economic Buyer tracker. The nuance, one is an open question, the other is a validated criterion, is invisible to pattern matching.
Second, the setup burden is real. Every tracker needs to be configured, tested, and maintained. When your sales methodology evolves or your market language shifts, trackers need manual updates.
"AI is not great (yet) - the product still feels like its at its infancy and needs to be developed further." - Annabelle H., Voluntary Director | G2 Review of Gong
Third, Gong's scoring operates at the meeting level, not the deal level. Each call gets evaluated independently. But MEDDIC qualification is a cumulative process. You might identify the pain in call one, validate the champion in call two, and confirm the decision process in call three. Meeting-level scoring misses this progression.
"The platform lacks task APIs, does not integrate with other vendors or parallel dialers, and isn't built to function as a proper sequencing tool. Gong is strong at conversation intelligence, but that's where its usefulness ends." - Sigma | G2 Review of Gong
The Comparison Table You Need
MEDDIC Scoring Tool Comparison: Gong vs Clari vs Oliv AI
"Not great for small/startup teams - way too expensive when there are more affordable tools that work. We're stuck with a tool that works technically but isn't the right business decision." - Iris P., Head of Marketing, Sales & Partnerships | G2 Review of Gong
Clari occupies a different space entirely. It is a forecasting and pipeline management tool, not a methodology scoring engine.
"It is really just a glorified SFDC overlay. Salesforce has built most of the forecasting functionality by now anyway so I'm not sure where they fit." - conaldinho11, Former Employee | Reddit r/SalesOperations
That assessment may be blunt, but it reflects the reality that Clari does not solve the MEDDIC compliance problem. If your qualification data is empty in Salesforce, it will be equally empty in Clari.
Other tools in this space, Avoma, Demodesk, and Pepsales, offer various levels of MEDDIC scoring. Avoma provides scorecard features within its conversation intelligence platform. Demodesk focuses on real-time coaching with methodology tracking. Pepsales positions as an AI-powered qualification tool. Each addresses a piece of the puzzle, but none provide the full deal-level, multi-source, autonomous scoring that an agentic architecture delivers.
What ROI Can You Expect From Automated MEDDIC Scoring in the First 90 Days? [toc=Auto-Scoring ROI]
Teams implementing MEDDIC auto-scoring report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. Implementation typically takes 5 minutes for baseline setup with full value realized in 1-2 weeks, compared to 3-6 month deployments for legacy platforms.
The Three ROI Levers
Auto-scoring generates return through three distinct mechanisms that compound over time.
Lever 1: Forecast accuracy improvement. When qualification data is objective, continuous, and evidence-based rather than subjective, sporadic, and self-reported, the forecast inputs improve. Better inputs produce better outputs. Organizations that implement systematic qualification scoring report moving from the industry-average 60-70% forecast accuracy toward the 80-90% range. Given that only 7% of sales orgs reach 90%+ accuracy, the improvement opportunity is massive for most teams.
This translates directly to revenue confidence. A VP of Sales presenting a forecast to the board with auto-scored qualification data is presenting verified intelligence, not compiled opinions. That changes the board conversation from "why did you miss?" to "here is what the data shows and here is how we are responding."
Lever 2: Manager time recovery. The average sales manager spends 6-8 hours per week on deal reviews and pipeline auditing. Much of this time is spent gathering basic qualification information that should already be in the system. When auto-scoring pre-triages deals and flags qualification gaps automatically, managers recover 50% or more of that time.
Recovered time goes to high-value activities. Instead of asking "do you have a champion?" a manager with auto-scored data asks "your champion engagement dropped this week, let us strategize about re-engagement." That is the difference between auditing and coaching. The coaching conversation drives better deal outcomes. The auditing conversation drives resentment.
Lever 3: Deal velocity through early disqualification. The most expensive deals in your pipeline are the ones that should have been disqualified three months ago. When qualification scoring happens automatically and continuously, deals with fundamental gaps get surfaced early. A deal with no identified Economic Buyer after four meetings is not a pipeline opportunity. It is a time sink.
Teams with auto-scoring report 15-30% shorter average sales cycles. Not because deals close faster in absolute terms, but because unqualified deals get removed from the pipeline sooner, reducing the average. The remaining pipeline is healthier, more predictable, and more deserving of the resources invested in it.
What Implementation Actually Looks Like
Legacy platforms come with implementation timelines measured in months. Gong implementations typically involve 4-6 weeks of configuration, data migration, tracker setup, and training. Clari deployments require mapping forecast hierarchies and Salesforce field configurations that can stretch to 3-6 months for complex organizations.
At Oliv, baseline setup takes 5 minutes. Connect your calendar, authorize CRM access, and the system starts recording and scoring from day one. The CRM Manager Agent begins populating MEDDIC fields from the first call it processes. Custom scoring rubrics and stage exit thresholds take an additional 2-4 weeks to calibrate, but value delivery starts immediately.
The TCO comparison makes the ROI case even stronger. A 100-rep organization running Gong plus Clari pays $500+ per user per month, roughly $600,000 annually. The same organization on Oliv's platform pays $29-39 per user per month for the full agent suite, totaling $35,000-47,000 annually. The delta exceeds half a million dollars per year before accounting for the productivity gains.
"The pricing is probably the biggest obstacle and hence we are looking to change." - Miodrag, Enterprise Account Executive | Gong Review
When the CFO reviews the line item and sees 91% potential cost reduction with equal or superior functionality, the business case writes itself.
How Do You Implement MEDDIC Auto-Scoring in Your Sales Org Without Disrupting Live Deals? [toc=Implementation Playbook]
Implementing MEDDIC auto-scoring requires four steps: define your scoring rubric per MEDDIC criterion, configure stage exit thresholds, run a 2-week parallel scoring test against manual reviews, and roll out with manager coaching playbooks that use auto-scores as 1:1 conversation starters. The key is framing auto-scoring as rep enablement, not surveillance.
Oliv enforces MEDDIC across four touchpoints, turning the framework from a one‑time training into a continuous operating system.
The Four-Step Rollout
Step 1: Define your scoring rubric. Before you turn on any tool, align your leadership team on what "good" looks like for each MEDDIC criterion. The rubric earlier in this article is a starting template, but your organization's specific deal dynamics should shape the definitions.
Key question to answer: at what score level does each criterion count as "satisfied" for pipeline progression? Most teams set the threshold at score 2 (validated) rather than score 3 (fully confirmed with executive engagement). Setting the bar too high creates false negatives. Setting it too low defeats the purpose.
Step 2: Configure stage exit thresholds. Map minimum qualification scores to each pipeline stage. A common structure:
These thresholds are flags, not blocks. Deals that advance without meeting thresholds get flagged for manager review rather than prevented from moving.
Step 3: Run a 2-week parallel scoring test. Before full rollout, run the auto-scoring system alongside your existing process. Have managers manually score 10-15 deals using the same rubric. Compare auto-scores against manager judgment.
This step serves two purposes. First, it calibrates the AI. If auto-scores consistently differ from manager judgment on specific criteria, you may need to adjust rubric definitions or scoring sensitivity. Second, it builds manager trust. Managers who see the AI accurately reflecting their own assessment become advocates rather than skeptics.
Enablement, Not Surveillance
Step 4: Roll out with coaching playbooks. The rollout message matters. If you announce "we are implementing AI scoring to monitor qualification compliance," you will face resistance. If you announce "we are giving managers better data so your 1:1s focus on strategy instead of CRM auditing," you get adoption.
Create a coaching playbook that shows managers exactly how to use auto-scores in their weekly 1:1s:
The single biggest predictor of auto-scoring adoption is framing. Reps who perceive scoring as surveillance resist it. Reps who perceive scoring as removing busywork embrace it.
Make the value exchange explicit. Auto-scoring eliminates the MEDDIC form. That Salesforce lightning component with six mandatory fields that reps hate filling out? Gone. The qualification data is populated automatically from conversations they are already having. The AI does the data entry. The rep does the selling.
When reps see their own deal scorecards updating without any action on their part, the response shifts from "Big Brother is watching" to "finally, a tool that does something useful." The deal scorecard becomes a personal dashboard, a way for the rep to see their own qualification gaps before the manager does, and to proactively address them.
"I would like easier access to training to enable me to better Forecast, pull data and access dashboards. As it stands I have had no training." - Edwin M., Senior Director | G2 Review of Clari
The common pitfalls are predictable and avoidable. Do not over-automate by removing all manual override capability. Do not ignore rep feedback about scoring accuracy in the first 30 days. Do not launch without calibrating scores against manager judgment first. And do not use auto-scores as punitive metrics. They are coaching inputs, not performance grades.
Frequently Asked Questions [toc=FAQs]
What is MEDDIC auto-scoring?
MEDDIC auto-scoring uses AI to analyze sales call transcripts and automatically evaluate each qualification criterion, Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion, without requiring manual input from sales reps.
Can AI accurately score MEDDIC from call recordings?
Yes. Modern AI analyzes conversational context rather than just keywords. It achieves higher accuracy than manual scoring because it evaluates every interaction consistently, without human bias, fatigue, or the tendency to skip fields under time pressure.
Which is better for MEDDIC scoring, Gong or Oliv AI?
Gong uses keyword-based Smart Trackers that detect when MEDDIC-related terms are mentioned. Oliv AI uses contextual AI that evaluates whether criteria were actually validated, provides evidence links and confidence scores, and operates at 91% lower cost per user.
How long does it take to implement MEDDIC auto-scoring?
With AI-native platforms like Oliv, baseline setup takes 5 minutes. Core value is realized in 1-2 days. Full customization including stage exit criteria and coaching workflows takes 2-4 weeks. Legacy platforms typically require 3-6 months.
Does MEDDIC auto-scoring work with MEDDPICC and BANT?
Yes. Leading auto-scoring platforms support multiple methodologies simultaneously. Oliv AI is trained on 100+ sales methodologies, scoring whichever framework your team uses, including custom hybrid approaches.
Will auto-scoring replace manual deal reviews?
Auto-scoring augments deal reviews rather than replacing them. It pre-triages deals so managers spend their review time on strategic coaching rather than basic qualification verification. Managers report 50%+ time savings on routine pipeline audits.
What ROI can I expect from MEDDIC auto-scoring?
Teams report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. TCO savings of up to 91% compared to Gong-plus-Clari stacks.
How do I get reps to adopt MEDDIC auto-scoring?
Frame it as removing work, not adding surveillance. Auto-scoring eliminates the manual MEDDIC form that reps resent filling out. When reps see accurate qualification data appearing without any effort on their part, adoption follows naturally.
The gap between scoring and coaching is closing faster than most people realize. Auto-scoring today is retrospective, but the next wave will be predictive and prescriptive. The endgame is not "did you fill in the field?" It is "did the conversation advance qualification, and here is what to do next."
How Oliv turns real sales conversations into fully auto-scored MEDDIC deal scorecards without manual CRM data entry.
I was running a pipe review last quarter when I noticed something that should have been obvious months earlier. Out of 47 active deals in our pipeline, 38 had MEDDIC fields that were either completely empty, filled with "TBD," or copy-pasted verbatim from the previous quarter's notes. One rep had the same Champion name listed on three different accounts, an account executive who had left the prospect company eight months ago.
That moment shifted something for me. The problem was not that our reps were lazy. It was not that they did not understand MEDDIC. The problem was that we had built a system that asked salespeople to do work that gave them nothing in return. We were running a methodology that depended on manual data entry from people whose entire compensation structure rewarded them for doing anything but data entry.
So we stopped asking reps to fill in MEDDIC fields. We started scoring them automatically from calls instead. Here is what we learned.
Why Do Sales Reps Refuse to Fill In MEDDIC Fields — And What Does It Actually Cost You? [toc=The Rep Resistance Problem]
Reps refuse to fill in MEDDIC fields because data entry provides zero immediate value to the person entering it. The rep's compensation, workflow, and daily priorities are disconnected from CRM hygiene. When qualification scoring requires switching from selling mode to database admin mode, reps rationally skip it, costing organizations 37% revenue loss from poor data quality and leaving forecast accuracy stuck at 60-70%.
The Switching Cost Nobody Talks About
Situation: Your sales team understands MEDDIC. They have been trained on it. They passed the certification quiz. They can recite the acronym in their sleep. And yet, when you pull up your pipeline dashboard, qualification fields are a wasteland.
Complication: This is not a training problem. It is a cognitive switching cost problem. When a rep finishes a 45-minute discovery call where they uncovered the prospect's pain, identified the economic buyer, and mapped the decision process, the last thing their brain wants to do is switch from relationship-building mode to database-admin mode. These are fundamentally different cognitive tasks.
Salesforce's State of Sales report found that reps spend only 35% of their time actually selling. Another 17% goes to fixing CRM entries. That is nearly one full day per week spent on data maintenance rather than revenue-generating activity.
The incentive misalignment makes it worse. Reps get paid on closed deals, not on CRM hygiene scores. When a rep has 30 minutes between calls, the rational choice is to prep for the next meeting, not to update MEDDIC fields that their manager might glance at during a weekly review. The system rewards the behavior it claims to discourage.
Resolution: The answer is not more training, more reminders, or more fields. The answer is removing the dependency entirely. If qualification data can be extracted from conversations that reps are already having, the compliance problem disappears. Not because reps decided to care about data entry, but because data entry is no longer required.
What Empty Fields Actually Cost Your Pipeline
The consequences of empty MEDDIC fields compound faster than most sales leaders realize.
A Kixie analysis of CRM usage data found that 76% of CRM users report less than half of their data is accurate. When three-quarters of your database is unreliable, every downstream process built on that data is compromised.
Pipeline reviews become fiction workshops. Without reliable qualification data, managers cannot distinguish between a deal that genuinely has executive sponsorship and one where the rep is hoping the CFO will show up. The weekly pipe review degenerates into "tell me the story of this deal" rather than "show me the evidence."
Forecast accuracy suffers directly. Industry data shows that organizations without systematic qualification enforcement achieve 60-70% forecast accuracy at best. Only 7% of sales orgs reach 90%+ accuracy, and almost none of them are relying on manually entered CRM data to get there.
The MEDDIC vs MEDDPICC vs BANT debate misses the point entirely. Some teams agonize over which framework to adopt. Should we add the extra P for Paper Process? Should we switch to SPICED? But the framework choice is irrelevant if nobody is populating the fields. A perfectly designed qualification rubric that sits empty in Salesforce is no better than having no rubric at all.
The core insight is this: methodology compliance is a design problem, not a people problem. You do not solve it by lecturing reps harder. You solve it by designing systems where compliance is a byproduct of work reps are already doing.
"Understanding the pipeline management portion of it is almost impossible. Some people figure it out, but I think most just fumble through and tell tall tales about how easy it is for them to use." - John S., Senior Account Executive | Gong G2 Review
From partial, inconsistent MEDDIC scorecards to 90%+ completion when scoring is automated from calls.”
How Does AI Auto-Score MEDDIC Criteria From Sales Calls Without Rep Input? [toc=How Auto-Scoring Works]
AI auto-scoring analyzes call transcripts to evaluate each MEDDIC criterion using contextual understanding rather than keyword matching. The system extracts evidence moments, assigns confidence scores per criterion, and writes results back to CRM fields automatically, eliminating manual data entry while producing more accurate qualification data than reps typically provide.
Keyword Matching vs Contextual Scoring
There is a fundamental difference between detecting that someone mentioned the words "Chief Financial Officer" on a call and understanding whether the Economic Buyer was actually validated.
First-generation tools like Gong's Smart Trackers operate on keyword and phrase pattern matching. You configure a tracker for "Economic Buyer" by specifying terms like "CFO," "budget holder," "final approver." When those terms appear in a transcript, the tracker fires. This is useful for basic visibility but creates two problems.
False positives flood the system. A rep saying "we need to figure out who the CFO is" triggers the same tracker as "the CFO confirmed she has budget authority for this quarter." Both register as "Economic Buyer discussed." Neither tells you whether the criterion was actually satisfied.
Setting up these trackers is itself a burden.
"It can be overwhelming to set up trackers. AI training is a bit laborious to get it to do what you want." - Trafford J., Senior Director of Revenue Enablement | Gong G2 Review
You are trading one manual process (reps filling in fields) for another (RevOps configuring and maintaining trackers).
Native AI scoring takes a different approach. Instead of matching keywords, it analyzes the conversational context to determine whether qualification criteria were genuinely addressed. The AI understands that "our VP of Finance mentioned she would need to sign off" is a Champion validation signal, while "I wonder who handles the budget over there" is not.
What a MEDDIC Scoring Rubric Actually Looks Like
A practical auto-scoring rubric evaluates each MEDDIC criterion on a multi-level scale. Here is what that looks like in practice:
MEDDIC Auto-Scoring Rubric: Scoring Levels Per Criterion
Criterion
Score 0
Score 1
Score 2
Score 3
M - Metrics
No business impact discussed
General pain mentioned
Specific metrics identified
Metrics tied to executive-validated outcome
E - Economic Buyer
Unknown or not discussed
Name mentioned, role unconfirmed
Identified with budget authority
Engaged in sales process
D - Decision Criteria
Not discussed
General requirements mentioned
Specific criteria documented
Criteria mapped with solution alignment
D - Decision Process
Unknown
Vague timeline only
Steps and stakeholders identified
Full process mapped with dates
I - Identify Pain
No pain articulated
Surface-level pain
Specific pain with business impact
Pain acknowledged at executive level
C - Champion
No advocate identified
Friendly contact, no influence
Champion with access to power
Actively selling internally
At Oliv AI, the CRM Manager Agent applies this rubric automatically across every recorded interaction. The scoring is not based on a single call but accumulated across the full deal lifecycle. A deal might score a 1 on Economic Buyer after the first discovery call, then upgrade to a 3 after the champion confirms executive engagement in a follow-up. Each score change links to the specific conversation moment that triggered it.
The Evidence Trail That Changes Everything
The most undervalued aspect of auto-scoring is the evidence trail. Every score is linked to a timestamped moment in the call recording where the relevant criterion was discussed.
When a manager sees that Deal XYZ has a Champion score of 2, they can click through to the exact 37-second clip where the prospect said "I will present this to our leadership team next Thursday." This transforms pipeline reviews from opinion debates into evidence-based discussions.
This matters because it changes the coaching conversation. Instead of "do you have a champion?" the manager asks "your champion score dropped from 2 to 1 this week, what happened in Wednesday's call?" The AI provides the context. The manager provides the strategy. The rep stops feeling interrogated and starts feeling supported.
The scoring also works across multiple frameworks simultaneously. The same conversation engine that evaluates MEDDIC criteria can score MEDDPICC (adding Paper Process and Competition), BANT (Budget, Authority, Need, Timeline), SPICED, or a fully custom framework. We built the engine to support 100+ sales methodologies natively because most teams use hybrid approaches rather than textbook implementations.
How Do You Enforce Stage Exit Criteria Without Creating a Bottleneck for Your Sales Team? [toc=Stage Exit Enforcement]
Stage exit criteria enforcement works by setting minimum qualification thresholds that must be met before a deal advances in your pipeline. When powered by auto-scoring, this happens invisibly. Deals are flagged rather than blocked, and managers receive alerts with specific evidence gaps to address in their next 1:1. The result is methodology compliance without manual gates or bureaucratic bottlenecks.
Flags, Not Blocks
The instinct when implementing stage exit criteria is to build hard gates. Deal cannot move from Stage 2 to Stage 3 unless MEDDIC score exceeds 12. This feels satisfying from a process design perspective but creates immediate problems in practice.
Hard blocks frustrate reps who have legitimate reasons for advancing deals. Not every deal follows a textbook qualification sequence. A prospect might skip straight to a technical evaluation before the rep has confirmed the Economic Buyer. Blocking that deal from advancing punishes the rep for the prospect's buying behavior.
The better approach is soft enforcement through flagging. When a deal advances without meeting minimum qualification thresholds, it gets flagged, not blocked. The manager receives an alert: "Deal XYZ moved to Stage 3 with Economic Buyer score of 0. Evidence gap: no executive contact identified in 4 recorded interactions."
This creates accountability without friction. The rep can advance the deal, but the flag becomes a coaching item in the next 1:1. The manager now has a specific, evidence-backed question to ask rather than a general "how's this deal going?"
"I have to maintain my own separate spreadsheet to track deals because I can only capture what my leaders want to see about a deal (revenue, close date, etc.) and as a rep, I need to have fields like product interest, last activity notes, key contacts, deal challenges or blockers." - Verified User, Enterprise | G2 Review of Clari
The Pipeline Accuracy Loop
Auto-scoring and stage exit enforcement create a reinforcing loop that improves pipeline accuracy over time.
When qualification criteria are scored automatically, managers can trust the pipeline data without manually verifying each deal. This means forecast calls shift from "let me hear the story of each deal" to "let me look at the exceptions." Instead of reviewing 50 deals in a pipeline review, the manager focuses on the 8 deals that have qualification gaps or score anomalies.
This is where the downstream effects compound. Better qualification data produces more accurate forecasts. More accurate forecasts produce better resource allocation decisions. Better resource allocation means reps spend time on deals that are actually qualified rather than chasing prospects who were never going to close.
The manager time savings are substantial. When deal qualification is pre-triaged by AI, managers report spending 50% less time on routine deal reviews. That time gets reinvested into strategic coaching, helping reps navigate complex deals rather than auditing whether they filled in a form.
At Oliv, the Deal Driver Agent feeds auto-scored data into daily deal intelligence summaries that go directly to manager inboxes. The agent identifies which deals need attention today based on qualification gaps, stalled progression, and competitive risk signals. Managers open their morning coffee email and immediately know which three deals to focus on, without clicking through a single dashboard.
The CRM hygiene improvement is a bonus effect. When qualification data flows automatically from conversations to CRM fields, the data quality problem that plagues most organizations solves itself. You do not need a quarterly "CRM cleanup sprint" when the data is continuously updated from the source of truth, actual sales conversations.
This creates a fundamentally different relationship between reps and their CRM. Instead of the CRM being a tax they pay for the privilege of selling, it becomes a living record that works for them. When a rep opens a deal record and sees accurate, auto-populated qualification data with evidence links, the CRM transforms from a management surveillance tool into a personal deal intelligence dashboard.
How Does Gong Score MEDDIC Compared to Native AI Scoring Platforms Like Oliv? [toc=Gong vs Native Scoring]
Gong uses Smart Trackers, keyword-based pattern matching that detects when MEDDIC-related terms are mentioned in calls. Native AI scoring goes deeper, analyzing conversational context to determine whether qualification criteria were actually validated, not just mentioned. The difference is detecting "CFO was discussed" versus confirming "the CFO has budget authority and has agreed to sponsor the deal."
What Smart Trackers Actually Detect
Gong's Smart Trackers work by scanning call transcripts for predefined keywords and phrases. You set up a tracker for each MEDDIC criterion, for example, mapping terms like "budget," "funding," "financial approval" to the Economic Buyer category. When those terms appear in a call, the tracker flags it.
This approach has clear strengths. It gives managers basic visibility into whether reps are covering qualification topics at all. For teams moving from zero methodology tracking to some visibility, Smart Trackers are a meaningful step up.
But the limitations are structural, not bugs to be fixed.
First, keyword matching cannot distinguish between mentioning a concept and validating it. "We need to find out who owns the budget" and "the VP of Finance confirmed a $200K allocation for Q3" both trigger an Economic Buyer tracker. The nuance, one is an open question, the other is a validated criterion, is invisible to pattern matching.
Second, the setup burden is real. Every tracker needs to be configured, tested, and maintained. When your sales methodology evolves or your market language shifts, trackers need manual updates.
"AI is not great (yet) - the product still feels like its at its infancy and needs to be developed further." - Annabelle H., Voluntary Director | G2 Review of Gong
Third, Gong's scoring operates at the meeting level, not the deal level. Each call gets evaluated independently. But MEDDIC qualification is a cumulative process. You might identify the pain in call one, validate the champion in call two, and confirm the decision process in call three. Meeting-level scoring misses this progression.
"The platform lacks task APIs, does not integrate with other vendors or parallel dialers, and isn't built to function as a proper sequencing tool. Gong is strong at conversation intelligence, but that's where its usefulness ends." - Sigma | G2 Review of Gong
The Comparison Table You Need
MEDDIC Scoring Tool Comparison: Gong vs Clari vs Oliv AI
"Not great for small/startup teams - way too expensive when there are more affordable tools that work. We're stuck with a tool that works technically but isn't the right business decision." - Iris P., Head of Marketing, Sales & Partnerships | G2 Review of Gong
Clari occupies a different space entirely. It is a forecasting and pipeline management tool, not a methodology scoring engine.
"It is really just a glorified SFDC overlay. Salesforce has built most of the forecasting functionality by now anyway so I'm not sure where they fit." - conaldinho11, Former Employee | Reddit r/SalesOperations
That assessment may be blunt, but it reflects the reality that Clari does not solve the MEDDIC compliance problem. If your qualification data is empty in Salesforce, it will be equally empty in Clari.
Other tools in this space, Avoma, Demodesk, and Pepsales, offer various levels of MEDDIC scoring. Avoma provides scorecard features within its conversation intelligence platform. Demodesk focuses on real-time coaching with methodology tracking. Pepsales positions as an AI-powered qualification tool. Each addresses a piece of the puzzle, but none provide the full deal-level, multi-source, autonomous scoring that an agentic architecture delivers.
What ROI Can You Expect From Automated MEDDIC Scoring in the First 90 Days? [toc=Auto-Scoring ROI]
Teams implementing MEDDIC auto-scoring report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. Implementation typically takes 5 minutes for baseline setup with full value realized in 1-2 weeks, compared to 3-6 month deployments for legacy platforms.
The Three ROI Levers
Auto-scoring generates return through three distinct mechanisms that compound over time.
Lever 1: Forecast accuracy improvement. When qualification data is objective, continuous, and evidence-based rather than subjective, sporadic, and self-reported, the forecast inputs improve. Better inputs produce better outputs. Organizations that implement systematic qualification scoring report moving from the industry-average 60-70% forecast accuracy toward the 80-90% range. Given that only 7% of sales orgs reach 90%+ accuracy, the improvement opportunity is massive for most teams.
This translates directly to revenue confidence. A VP of Sales presenting a forecast to the board with auto-scored qualification data is presenting verified intelligence, not compiled opinions. That changes the board conversation from "why did you miss?" to "here is what the data shows and here is how we are responding."
Lever 2: Manager time recovery. The average sales manager spends 6-8 hours per week on deal reviews and pipeline auditing. Much of this time is spent gathering basic qualification information that should already be in the system. When auto-scoring pre-triages deals and flags qualification gaps automatically, managers recover 50% or more of that time.
Recovered time goes to high-value activities. Instead of asking "do you have a champion?" a manager with auto-scored data asks "your champion engagement dropped this week, let us strategize about re-engagement." That is the difference between auditing and coaching. The coaching conversation drives better deal outcomes. The auditing conversation drives resentment.
Lever 3: Deal velocity through early disqualification. The most expensive deals in your pipeline are the ones that should have been disqualified three months ago. When qualification scoring happens automatically and continuously, deals with fundamental gaps get surfaced early. A deal with no identified Economic Buyer after four meetings is not a pipeline opportunity. It is a time sink.
Teams with auto-scoring report 15-30% shorter average sales cycles. Not because deals close faster in absolute terms, but because unqualified deals get removed from the pipeline sooner, reducing the average. The remaining pipeline is healthier, more predictable, and more deserving of the resources invested in it.
What Implementation Actually Looks Like
Legacy platforms come with implementation timelines measured in months. Gong implementations typically involve 4-6 weeks of configuration, data migration, tracker setup, and training. Clari deployments require mapping forecast hierarchies and Salesforce field configurations that can stretch to 3-6 months for complex organizations.
At Oliv, baseline setup takes 5 minutes. Connect your calendar, authorize CRM access, and the system starts recording and scoring from day one. The CRM Manager Agent begins populating MEDDIC fields from the first call it processes. Custom scoring rubrics and stage exit thresholds take an additional 2-4 weeks to calibrate, but value delivery starts immediately.
The TCO comparison makes the ROI case even stronger. A 100-rep organization running Gong plus Clari pays $500+ per user per month, roughly $600,000 annually. The same organization on Oliv's platform pays $29-39 per user per month for the full agent suite, totaling $35,000-47,000 annually. The delta exceeds half a million dollars per year before accounting for the productivity gains.
"The pricing is probably the biggest obstacle and hence we are looking to change." - Miodrag, Enterprise Account Executive | Gong Review
When the CFO reviews the line item and sees 91% potential cost reduction with equal or superior functionality, the business case writes itself.
How Do You Implement MEDDIC Auto-Scoring in Your Sales Org Without Disrupting Live Deals? [toc=Implementation Playbook]
Implementing MEDDIC auto-scoring requires four steps: define your scoring rubric per MEDDIC criterion, configure stage exit thresholds, run a 2-week parallel scoring test against manual reviews, and roll out with manager coaching playbooks that use auto-scores as 1:1 conversation starters. The key is framing auto-scoring as rep enablement, not surveillance.
Oliv enforces MEDDIC across four touchpoints, turning the framework from a one‑time training into a continuous operating system.
The Four-Step Rollout
Step 1: Define your scoring rubric. Before you turn on any tool, align your leadership team on what "good" looks like for each MEDDIC criterion. The rubric earlier in this article is a starting template, but your organization's specific deal dynamics should shape the definitions.
Key question to answer: at what score level does each criterion count as "satisfied" for pipeline progression? Most teams set the threshold at score 2 (validated) rather than score 3 (fully confirmed with executive engagement). Setting the bar too high creates false negatives. Setting it too low defeats the purpose.
Step 2: Configure stage exit thresholds. Map minimum qualification scores to each pipeline stage. A common structure:
These thresholds are flags, not blocks. Deals that advance without meeting thresholds get flagged for manager review rather than prevented from moving.
Step 3: Run a 2-week parallel scoring test. Before full rollout, run the auto-scoring system alongside your existing process. Have managers manually score 10-15 deals using the same rubric. Compare auto-scores against manager judgment.
This step serves two purposes. First, it calibrates the AI. If auto-scores consistently differ from manager judgment on specific criteria, you may need to adjust rubric definitions or scoring sensitivity. Second, it builds manager trust. Managers who see the AI accurately reflecting their own assessment become advocates rather than skeptics.
Enablement, Not Surveillance
Step 4: Roll out with coaching playbooks. The rollout message matters. If you announce "we are implementing AI scoring to monitor qualification compliance," you will face resistance. If you announce "we are giving managers better data so your 1:1s focus on strategy instead of CRM auditing," you get adoption.
Create a coaching playbook that shows managers exactly how to use auto-scores in their weekly 1:1s:
The single biggest predictor of auto-scoring adoption is framing. Reps who perceive scoring as surveillance resist it. Reps who perceive scoring as removing busywork embrace it.
Make the value exchange explicit. Auto-scoring eliminates the MEDDIC form. That Salesforce lightning component with six mandatory fields that reps hate filling out? Gone. The qualification data is populated automatically from conversations they are already having. The AI does the data entry. The rep does the selling.
When reps see their own deal scorecards updating without any action on their part, the response shifts from "Big Brother is watching" to "finally, a tool that does something useful." The deal scorecard becomes a personal dashboard, a way for the rep to see their own qualification gaps before the manager does, and to proactively address them.
"I would like easier access to training to enable me to better Forecast, pull data and access dashboards. As it stands I have had no training." - Edwin M., Senior Director | G2 Review of Clari
The common pitfalls are predictable and avoidable. Do not over-automate by removing all manual override capability. Do not ignore rep feedback about scoring accuracy in the first 30 days. Do not launch without calibrating scores against manager judgment first. And do not use auto-scores as punitive metrics. They are coaching inputs, not performance grades.
Frequently Asked Questions [toc=FAQs]
What is MEDDIC auto-scoring?
MEDDIC auto-scoring uses AI to analyze sales call transcripts and automatically evaluate each qualification criterion, Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion, without requiring manual input from sales reps.
Can AI accurately score MEDDIC from call recordings?
Yes. Modern AI analyzes conversational context rather than just keywords. It achieves higher accuracy than manual scoring because it evaluates every interaction consistently, without human bias, fatigue, or the tendency to skip fields under time pressure.
Which is better for MEDDIC scoring, Gong or Oliv AI?
Gong uses keyword-based Smart Trackers that detect when MEDDIC-related terms are mentioned. Oliv AI uses contextual AI that evaluates whether criteria were actually validated, provides evidence links and confidence scores, and operates at 91% lower cost per user.
How long does it take to implement MEDDIC auto-scoring?
With AI-native platforms like Oliv, baseline setup takes 5 minutes. Core value is realized in 1-2 days. Full customization including stage exit criteria and coaching workflows takes 2-4 weeks. Legacy platforms typically require 3-6 months.
Does MEDDIC auto-scoring work with MEDDPICC and BANT?
Yes. Leading auto-scoring platforms support multiple methodologies simultaneously. Oliv AI is trained on 100+ sales methodologies, scoring whichever framework your team uses, including custom hybrid approaches.
Will auto-scoring replace manual deal reviews?
Auto-scoring augments deal reviews rather than replacing them. It pre-triages deals so managers spend their review time on strategic coaching rather than basic qualification verification. Managers report 50%+ time savings on routine pipeline audits.
What ROI can I expect from MEDDIC auto-scoring?
Teams report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. TCO savings of up to 91% compared to Gong-plus-Clari stacks.
How do I get reps to adopt MEDDIC auto-scoring?
Frame it as removing work, not adding surveillance. Auto-scoring eliminates the manual MEDDIC form that reps resent filling out. When reps see accurate qualification data appearing without any effort on their part, adoption follows naturally.
The gap between scoring and coaching is closing faster than most people realize. Auto-scoring today is retrospective, but the next wave will be predictive and prescriptive. The endgame is not "did you fill in the field?" It is "did the conversation advance qualification, and here is what to do next."
How Oliv turns real sales conversations into fully auto-scored MEDDIC deal scorecards without manual CRM data entry.
I was running a pipe review last quarter when I noticed something that should have been obvious months earlier. Out of 47 active deals in our pipeline, 38 had MEDDIC fields that were either completely empty, filled with "TBD," or copy-pasted verbatim from the previous quarter's notes. One rep had the same Champion name listed on three different accounts, an account executive who had left the prospect company eight months ago.
That moment shifted something for me. The problem was not that our reps were lazy. It was not that they did not understand MEDDIC. The problem was that we had built a system that asked salespeople to do work that gave them nothing in return. We were running a methodology that depended on manual data entry from people whose entire compensation structure rewarded them for doing anything but data entry.
So we stopped asking reps to fill in MEDDIC fields. We started scoring them automatically from calls instead. Here is what we learned.
Why Do Sales Reps Refuse to Fill In MEDDIC Fields — And What Does It Actually Cost You? [toc=The Rep Resistance Problem]
Reps refuse to fill in MEDDIC fields because data entry provides zero immediate value to the person entering it. The rep's compensation, workflow, and daily priorities are disconnected from CRM hygiene. When qualification scoring requires switching from selling mode to database admin mode, reps rationally skip it, costing organizations 37% revenue loss from poor data quality and leaving forecast accuracy stuck at 60-70%.
The Switching Cost Nobody Talks About
Situation: Your sales team understands MEDDIC. They have been trained on it. They passed the certification quiz. They can recite the acronym in their sleep. And yet, when you pull up your pipeline dashboard, qualification fields are a wasteland.
Complication: This is not a training problem. It is a cognitive switching cost problem. When a rep finishes a 45-minute discovery call where they uncovered the prospect's pain, identified the economic buyer, and mapped the decision process, the last thing their brain wants to do is switch from relationship-building mode to database-admin mode. These are fundamentally different cognitive tasks.
Salesforce's State of Sales report found that reps spend only 35% of their time actually selling. Another 17% goes to fixing CRM entries. That is nearly one full day per week spent on data maintenance rather than revenue-generating activity.
The incentive misalignment makes it worse. Reps get paid on closed deals, not on CRM hygiene scores. When a rep has 30 minutes between calls, the rational choice is to prep for the next meeting, not to update MEDDIC fields that their manager might glance at during a weekly review. The system rewards the behavior it claims to discourage.
Resolution: The answer is not more training, more reminders, or more fields. The answer is removing the dependency entirely. If qualification data can be extracted from conversations that reps are already having, the compliance problem disappears. Not because reps decided to care about data entry, but because data entry is no longer required.
What Empty Fields Actually Cost Your Pipeline
The consequences of empty MEDDIC fields compound faster than most sales leaders realize.
A Kixie analysis of CRM usage data found that 76% of CRM users report less than half of their data is accurate. When three-quarters of your database is unreliable, every downstream process built on that data is compromised.
Pipeline reviews become fiction workshops. Without reliable qualification data, managers cannot distinguish between a deal that genuinely has executive sponsorship and one where the rep is hoping the CFO will show up. The weekly pipe review degenerates into "tell me the story of this deal" rather than "show me the evidence."
Forecast accuracy suffers directly. Industry data shows that organizations without systematic qualification enforcement achieve 60-70% forecast accuracy at best. Only 7% of sales orgs reach 90%+ accuracy, and almost none of them are relying on manually entered CRM data to get there.
The MEDDIC vs MEDDPICC vs BANT debate misses the point entirely. Some teams agonize over which framework to adopt. Should we add the extra P for Paper Process? Should we switch to SPICED? But the framework choice is irrelevant if nobody is populating the fields. A perfectly designed qualification rubric that sits empty in Salesforce is no better than having no rubric at all.
The core insight is this: methodology compliance is a design problem, not a people problem. You do not solve it by lecturing reps harder. You solve it by designing systems where compliance is a byproduct of work reps are already doing.
"Understanding the pipeline management portion of it is almost impossible. Some people figure it out, but I think most just fumble through and tell tall tales about how easy it is for them to use." - John S., Senior Account Executive | Gong G2 Review
From partial, inconsistent MEDDIC scorecards to 90%+ completion when scoring is automated from calls.”
How Does AI Auto-Score MEDDIC Criteria From Sales Calls Without Rep Input? [toc=How Auto-Scoring Works]
AI auto-scoring analyzes call transcripts to evaluate each MEDDIC criterion using contextual understanding rather than keyword matching. The system extracts evidence moments, assigns confidence scores per criterion, and writes results back to CRM fields automatically, eliminating manual data entry while producing more accurate qualification data than reps typically provide.
Keyword Matching vs Contextual Scoring
There is a fundamental difference between detecting that someone mentioned the words "Chief Financial Officer" on a call and understanding whether the Economic Buyer was actually validated.
First-generation tools like Gong's Smart Trackers operate on keyword and phrase pattern matching. You configure a tracker for "Economic Buyer" by specifying terms like "CFO," "budget holder," "final approver." When those terms appear in a transcript, the tracker fires. This is useful for basic visibility but creates two problems.
False positives flood the system. A rep saying "we need to figure out who the CFO is" triggers the same tracker as "the CFO confirmed she has budget authority for this quarter." Both register as "Economic Buyer discussed." Neither tells you whether the criterion was actually satisfied.
Setting up these trackers is itself a burden.
"It can be overwhelming to set up trackers. AI training is a bit laborious to get it to do what you want." - Trafford J., Senior Director of Revenue Enablement | Gong G2 Review
You are trading one manual process (reps filling in fields) for another (RevOps configuring and maintaining trackers).
Native AI scoring takes a different approach. Instead of matching keywords, it analyzes the conversational context to determine whether qualification criteria were genuinely addressed. The AI understands that "our VP of Finance mentioned she would need to sign off" is a Champion validation signal, while "I wonder who handles the budget over there" is not.
What a MEDDIC Scoring Rubric Actually Looks Like
A practical auto-scoring rubric evaluates each MEDDIC criterion on a multi-level scale. Here is what that looks like in practice:
MEDDIC Auto-Scoring Rubric: Scoring Levels Per Criterion
Criterion
Score 0
Score 1
Score 2
Score 3
M - Metrics
No business impact discussed
General pain mentioned
Specific metrics identified
Metrics tied to executive-validated outcome
E - Economic Buyer
Unknown or not discussed
Name mentioned, role unconfirmed
Identified with budget authority
Engaged in sales process
D - Decision Criteria
Not discussed
General requirements mentioned
Specific criteria documented
Criteria mapped with solution alignment
D - Decision Process
Unknown
Vague timeline only
Steps and stakeholders identified
Full process mapped with dates
I - Identify Pain
No pain articulated
Surface-level pain
Specific pain with business impact
Pain acknowledged at executive level
C - Champion
No advocate identified
Friendly contact, no influence
Champion with access to power
Actively selling internally
At Oliv AI, the CRM Manager Agent applies this rubric automatically across every recorded interaction. The scoring is not based on a single call but accumulated across the full deal lifecycle. A deal might score a 1 on Economic Buyer after the first discovery call, then upgrade to a 3 after the champion confirms executive engagement in a follow-up. Each score change links to the specific conversation moment that triggered it.
The Evidence Trail That Changes Everything
The most undervalued aspect of auto-scoring is the evidence trail. Every score is linked to a timestamped moment in the call recording where the relevant criterion was discussed.
When a manager sees that Deal XYZ has a Champion score of 2, they can click through to the exact 37-second clip where the prospect said "I will present this to our leadership team next Thursday." This transforms pipeline reviews from opinion debates into evidence-based discussions.
This matters because it changes the coaching conversation. Instead of "do you have a champion?" the manager asks "your champion score dropped from 2 to 1 this week, what happened in Wednesday's call?" The AI provides the context. The manager provides the strategy. The rep stops feeling interrogated and starts feeling supported.
The scoring also works across multiple frameworks simultaneously. The same conversation engine that evaluates MEDDIC criteria can score MEDDPICC (adding Paper Process and Competition), BANT (Budget, Authority, Need, Timeline), SPICED, or a fully custom framework. We built the engine to support 100+ sales methodologies natively because most teams use hybrid approaches rather than textbook implementations.
How Do You Enforce Stage Exit Criteria Without Creating a Bottleneck for Your Sales Team? [toc=Stage Exit Enforcement]
Stage exit criteria enforcement works by setting minimum qualification thresholds that must be met before a deal advances in your pipeline. When powered by auto-scoring, this happens invisibly. Deals are flagged rather than blocked, and managers receive alerts with specific evidence gaps to address in their next 1:1. The result is methodology compliance without manual gates or bureaucratic bottlenecks.
Flags, Not Blocks
The instinct when implementing stage exit criteria is to build hard gates. Deal cannot move from Stage 2 to Stage 3 unless MEDDIC score exceeds 12. This feels satisfying from a process design perspective but creates immediate problems in practice.
Hard blocks frustrate reps who have legitimate reasons for advancing deals. Not every deal follows a textbook qualification sequence. A prospect might skip straight to a technical evaluation before the rep has confirmed the Economic Buyer. Blocking that deal from advancing punishes the rep for the prospect's buying behavior.
The better approach is soft enforcement through flagging. When a deal advances without meeting minimum qualification thresholds, it gets flagged, not blocked. The manager receives an alert: "Deal XYZ moved to Stage 3 with Economic Buyer score of 0. Evidence gap: no executive contact identified in 4 recorded interactions."
This creates accountability without friction. The rep can advance the deal, but the flag becomes a coaching item in the next 1:1. The manager now has a specific, evidence-backed question to ask rather than a general "how's this deal going?"
"I have to maintain my own separate spreadsheet to track deals because I can only capture what my leaders want to see about a deal (revenue, close date, etc.) and as a rep, I need to have fields like product interest, last activity notes, key contacts, deal challenges or blockers." - Verified User, Enterprise | G2 Review of Clari
The Pipeline Accuracy Loop
Auto-scoring and stage exit enforcement create a reinforcing loop that improves pipeline accuracy over time.
When qualification criteria are scored automatically, managers can trust the pipeline data without manually verifying each deal. This means forecast calls shift from "let me hear the story of each deal" to "let me look at the exceptions." Instead of reviewing 50 deals in a pipeline review, the manager focuses on the 8 deals that have qualification gaps or score anomalies.
This is where the downstream effects compound. Better qualification data produces more accurate forecasts. More accurate forecasts produce better resource allocation decisions. Better resource allocation means reps spend time on deals that are actually qualified rather than chasing prospects who were never going to close.
The manager time savings are substantial. When deal qualification is pre-triaged by AI, managers report spending 50% less time on routine deal reviews. That time gets reinvested into strategic coaching, helping reps navigate complex deals rather than auditing whether they filled in a form.
At Oliv, the Deal Driver Agent feeds auto-scored data into daily deal intelligence summaries that go directly to manager inboxes. The agent identifies which deals need attention today based on qualification gaps, stalled progression, and competitive risk signals. Managers open their morning coffee email and immediately know which three deals to focus on, without clicking through a single dashboard.
The CRM hygiene improvement is a bonus effect. When qualification data flows automatically from conversations to CRM fields, the data quality problem that plagues most organizations solves itself. You do not need a quarterly "CRM cleanup sprint" when the data is continuously updated from the source of truth, actual sales conversations.
This creates a fundamentally different relationship between reps and their CRM. Instead of the CRM being a tax they pay for the privilege of selling, it becomes a living record that works for them. When a rep opens a deal record and sees accurate, auto-populated qualification data with evidence links, the CRM transforms from a management surveillance tool into a personal deal intelligence dashboard.
How Does Gong Score MEDDIC Compared to Native AI Scoring Platforms Like Oliv? [toc=Gong vs Native Scoring]
Gong uses Smart Trackers, keyword-based pattern matching that detects when MEDDIC-related terms are mentioned in calls. Native AI scoring goes deeper, analyzing conversational context to determine whether qualification criteria were actually validated, not just mentioned. The difference is detecting "CFO was discussed" versus confirming "the CFO has budget authority and has agreed to sponsor the deal."
What Smart Trackers Actually Detect
Gong's Smart Trackers work by scanning call transcripts for predefined keywords and phrases. You set up a tracker for each MEDDIC criterion, for example, mapping terms like "budget," "funding," "financial approval" to the Economic Buyer category. When those terms appear in a call, the tracker flags it.
This approach has clear strengths. It gives managers basic visibility into whether reps are covering qualification topics at all. For teams moving from zero methodology tracking to some visibility, Smart Trackers are a meaningful step up.
But the limitations are structural, not bugs to be fixed.
First, keyword matching cannot distinguish between mentioning a concept and validating it. "We need to find out who owns the budget" and "the VP of Finance confirmed a $200K allocation for Q3" both trigger an Economic Buyer tracker. The nuance, one is an open question, the other is a validated criterion, is invisible to pattern matching.
Second, the setup burden is real. Every tracker needs to be configured, tested, and maintained. When your sales methodology evolves or your market language shifts, trackers need manual updates.
"AI is not great (yet) - the product still feels like its at its infancy and needs to be developed further." - Annabelle H., Voluntary Director | G2 Review of Gong
Third, Gong's scoring operates at the meeting level, not the deal level. Each call gets evaluated independently. But MEDDIC qualification is a cumulative process. You might identify the pain in call one, validate the champion in call two, and confirm the decision process in call three. Meeting-level scoring misses this progression.
"The platform lacks task APIs, does not integrate with other vendors or parallel dialers, and isn't built to function as a proper sequencing tool. Gong is strong at conversation intelligence, but that's where its usefulness ends." - Sigma | G2 Review of Gong
The Comparison Table You Need
MEDDIC Scoring Tool Comparison: Gong vs Clari vs Oliv AI
"Not great for small/startup teams - way too expensive when there are more affordable tools that work. We're stuck with a tool that works technically but isn't the right business decision." - Iris P., Head of Marketing, Sales & Partnerships | G2 Review of Gong
Clari occupies a different space entirely. It is a forecasting and pipeline management tool, not a methodology scoring engine.
"It is really just a glorified SFDC overlay. Salesforce has built most of the forecasting functionality by now anyway so I'm not sure where they fit." - conaldinho11, Former Employee | Reddit r/SalesOperations
That assessment may be blunt, but it reflects the reality that Clari does not solve the MEDDIC compliance problem. If your qualification data is empty in Salesforce, it will be equally empty in Clari.
Other tools in this space, Avoma, Demodesk, and Pepsales, offer various levels of MEDDIC scoring. Avoma provides scorecard features within its conversation intelligence platform. Demodesk focuses on real-time coaching with methodology tracking. Pepsales positions as an AI-powered qualification tool. Each addresses a piece of the puzzle, but none provide the full deal-level, multi-source, autonomous scoring that an agentic architecture delivers.
What ROI Can You Expect From Automated MEDDIC Scoring in the First 90 Days? [toc=Auto-Scoring ROI]
Teams implementing MEDDIC auto-scoring report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. Implementation typically takes 5 minutes for baseline setup with full value realized in 1-2 weeks, compared to 3-6 month deployments for legacy platforms.
The Three ROI Levers
Auto-scoring generates return through three distinct mechanisms that compound over time.
Lever 1: Forecast accuracy improvement. When qualification data is objective, continuous, and evidence-based rather than subjective, sporadic, and self-reported, the forecast inputs improve. Better inputs produce better outputs. Organizations that implement systematic qualification scoring report moving from the industry-average 60-70% forecast accuracy toward the 80-90% range. Given that only 7% of sales orgs reach 90%+ accuracy, the improvement opportunity is massive for most teams.
This translates directly to revenue confidence. A VP of Sales presenting a forecast to the board with auto-scored qualification data is presenting verified intelligence, not compiled opinions. That changes the board conversation from "why did you miss?" to "here is what the data shows and here is how we are responding."
Lever 2: Manager time recovery. The average sales manager spends 6-8 hours per week on deal reviews and pipeline auditing. Much of this time is spent gathering basic qualification information that should already be in the system. When auto-scoring pre-triages deals and flags qualification gaps automatically, managers recover 50% or more of that time.
Recovered time goes to high-value activities. Instead of asking "do you have a champion?" a manager with auto-scored data asks "your champion engagement dropped this week, let us strategize about re-engagement." That is the difference between auditing and coaching. The coaching conversation drives better deal outcomes. The auditing conversation drives resentment.
Lever 3: Deal velocity through early disqualification. The most expensive deals in your pipeline are the ones that should have been disqualified three months ago. When qualification scoring happens automatically and continuously, deals with fundamental gaps get surfaced early. A deal with no identified Economic Buyer after four meetings is not a pipeline opportunity. It is a time sink.
Teams with auto-scoring report 15-30% shorter average sales cycles. Not because deals close faster in absolute terms, but because unqualified deals get removed from the pipeline sooner, reducing the average. The remaining pipeline is healthier, more predictable, and more deserving of the resources invested in it.
What Implementation Actually Looks Like
Legacy platforms come with implementation timelines measured in months. Gong implementations typically involve 4-6 weeks of configuration, data migration, tracker setup, and training. Clari deployments require mapping forecast hierarchies and Salesforce field configurations that can stretch to 3-6 months for complex organizations.
At Oliv, baseline setup takes 5 minutes. Connect your calendar, authorize CRM access, and the system starts recording and scoring from day one. The CRM Manager Agent begins populating MEDDIC fields from the first call it processes. Custom scoring rubrics and stage exit thresholds take an additional 2-4 weeks to calibrate, but value delivery starts immediately.
The TCO comparison makes the ROI case even stronger. A 100-rep organization running Gong plus Clari pays $500+ per user per month, roughly $600,000 annually. The same organization on Oliv's platform pays $29-39 per user per month for the full agent suite, totaling $35,000-47,000 annually. The delta exceeds half a million dollars per year before accounting for the productivity gains.
"The pricing is probably the biggest obstacle and hence we are looking to change." - Miodrag, Enterprise Account Executive | Gong Review
When the CFO reviews the line item and sees 91% potential cost reduction with equal or superior functionality, the business case writes itself.
How Do You Implement MEDDIC Auto-Scoring in Your Sales Org Without Disrupting Live Deals? [toc=Implementation Playbook]
Implementing MEDDIC auto-scoring requires four steps: define your scoring rubric per MEDDIC criterion, configure stage exit thresholds, run a 2-week parallel scoring test against manual reviews, and roll out with manager coaching playbooks that use auto-scores as 1:1 conversation starters. The key is framing auto-scoring as rep enablement, not surveillance.
Oliv enforces MEDDIC across four touchpoints, turning the framework from a one‑time training into a continuous operating system.
The Four-Step Rollout
Step 1: Define your scoring rubric. Before you turn on any tool, align your leadership team on what "good" looks like for each MEDDIC criterion. The rubric earlier in this article is a starting template, but your organization's specific deal dynamics should shape the definitions.
Key question to answer: at what score level does each criterion count as "satisfied" for pipeline progression? Most teams set the threshold at score 2 (validated) rather than score 3 (fully confirmed with executive engagement). Setting the bar too high creates false negatives. Setting it too low defeats the purpose.
Step 2: Configure stage exit thresholds. Map minimum qualification scores to each pipeline stage. A common structure:
These thresholds are flags, not blocks. Deals that advance without meeting thresholds get flagged for manager review rather than prevented from moving.
Step 3: Run a 2-week parallel scoring test. Before full rollout, run the auto-scoring system alongside your existing process. Have managers manually score 10-15 deals using the same rubric. Compare auto-scores against manager judgment.
This step serves two purposes. First, it calibrates the AI. If auto-scores consistently differ from manager judgment on specific criteria, you may need to adjust rubric definitions or scoring sensitivity. Second, it builds manager trust. Managers who see the AI accurately reflecting their own assessment become advocates rather than skeptics.
Enablement, Not Surveillance
Step 4: Roll out with coaching playbooks. The rollout message matters. If you announce "we are implementing AI scoring to monitor qualification compliance," you will face resistance. If you announce "we are giving managers better data so your 1:1s focus on strategy instead of CRM auditing," you get adoption.
Create a coaching playbook that shows managers exactly how to use auto-scores in their weekly 1:1s:
The single biggest predictor of auto-scoring adoption is framing. Reps who perceive scoring as surveillance resist it. Reps who perceive scoring as removing busywork embrace it.
Make the value exchange explicit. Auto-scoring eliminates the MEDDIC form. That Salesforce lightning component with six mandatory fields that reps hate filling out? Gone. The qualification data is populated automatically from conversations they are already having. The AI does the data entry. The rep does the selling.
When reps see their own deal scorecards updating without any action on their part, the response shifts from "Big Brother is watching" to "finally, a tool that does something useful." The deal scorecard becomes a personal dashboard, a way for the rep to see their own qualification gaps before the manager does, and to proactively address them.
"I would like easier access to training to enable me to better Forecast, pull data and access dashboards. As it stands I have had no training." - Edwin M., Senior Director | G2 Review of Clari
The common pitfalls are predictable and avoidable. Do not over-automate by removing all manual override capability. Do not ignore rep feedback about scoring accuracy in the first 30 days. Do not launch without calibrating scores against manager judgment first. And do not use auto-scores as punitive metrics. They are coaching inputs, not performance grades.
Frequently Asked Questions [toc=FAQs]
What is MEDDIC auto-scoring?
MEDDIC auto-scoring uses AI to analyze sales call transcripts and automatically evaluate each qualification criterion, Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion, without requiring manual input from sales reps.
Can AI accurately score MEDDIC from call recordings?
Yes. Modern AI analyzes conversational context rather than just keywords. It achieves higher accuracy than manual scoring because it evaluates every interaction consistently, without human bias, fatigue, or the tendency to skip fields under time pressure.
Which is better for MEDDIC scoring, Gong or Oliv AI?
Gong uses keyword-based Smart Trackers that detect when MEDDIC-related terms are mentioned. Oliv AI uses contextual AI that evaluates whether criteria were actually validated, provides evidence links and confidence scores, and operates at 91% lower cost per user.
How long does it take to implement MEDDIC auto-scoring?
With AI-native platforms like Oliv, baseline setup takes 5 minutes. Core value is realized in 1-2 days. Full customization including stage exit criteria and coaching workflows takes 2-4 weeks. Legacy platforms typically require 3-6 months.
Does MEDDIC auto-scoring work with MEDDPICC and BANT?
Yes. Leading auto-scoring platforms support multiple methodologies simultaneously. Oliv AI is trained on 100+ sales methodologies, scoring whichever framework your team uses, including custom hybrid approaches.
Will auto-scoring replace manual deal reviews?
Auto-scoring augments deal reviews rather than replacing them. It pre-triages deals so managers spend their review time on strategic coaching rather than basic qualification verification. Managers report 50%+ time savings on routine pipeline audits.
What ROI can I expect from MEDDIC auto-scoring?
Teams report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. TCO savings of up to 91% compared to Gong-plus-Clari stacks.
How do I get reps to adopt MEDDIC auto-scoring?
Frame it as removing work, not adding surveillance. Auto-scoring eliminates the manual MEDDIC form that reps resent filling out. When reps see accurate qualification data appearing without any effort on their part, adoption follows naturally.
The gap between scoring and coaching is closing faster than most people realize. Auto-scoring today is retrospective, but the next wave will be predictive and prescriptive. The endgame is not "did you fill in the field?" It is "did the conversation advance qualification, and here is what to do next."
FAQ's
What is MEDDIC auto-scoring?
MEDDIC auto-scoring uses AI to analyze sales call transcripts and automatically evaluate each qualification criterion - Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion - without requiring manual input from sales reps.
Can AI accurately score MEDDIC from call recordings?
Yes. Modern AI analyzes conversational context rather than just keywords. It achieves higher accuracy than manual scoring because it evaluates every interaction consistently, without human bias, fatigue, or the tendency to skip fields under time pressure.
Which is better for MEDDIC scoring, Gong or Oliv AI?
Gong uses keyword-based Smart Trackers that detect when MEDDIC-related terms are mentioned. Oliv AI uses contextual AI that evaluates whether criteria were actually validated, provides evidence links and confidence scores, and operates at 91% lower cost per user.
How long does it take to implement MEDDIC auto-scoring?
With AI-native platforms like Oliv, baseline setup takes 5 minutes. Core value is realized in 1-2 days. Full customization including stage exit criteria and coaching workflows takes 2-4 weeks. Legacy platforms typically require 3-6 months.
Does MEDDIC auto-scoring work with MEDDPICC and BANT?
Yes. Leading auto-scoring platforms support multiple methodologies simultaneously. Oliv AI is trained on 100+ sales methodologies, scoring whichever framework your team uses, including custom hybrid approaches.
Will auto-scoring replace manual deal reviews?
Auto-scoring augments deal reviews rather than replacing them. It pre-triages deals so managers spend their review time on strategic coaching rather than basic qualification verification. Managers report 50%+ time savings on routine pipeline audits.
What ROI can I expect from MEDDIC auto-scoring?
Teams report 25-40% improvement in forecast accuracy, 50%+ reduction in manager deal review time, and 15-30% shorter sales cycles from better early-stage qualification. TCO savings of up to 91% compared to Gong-plus-Clari stacks.
Enjoyed the read? Join our founder for a quick 7-minute chat — no pitch, just a real conversation on how we’re rethinking RevOps with AI.
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields, all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions

.avif)
.png)








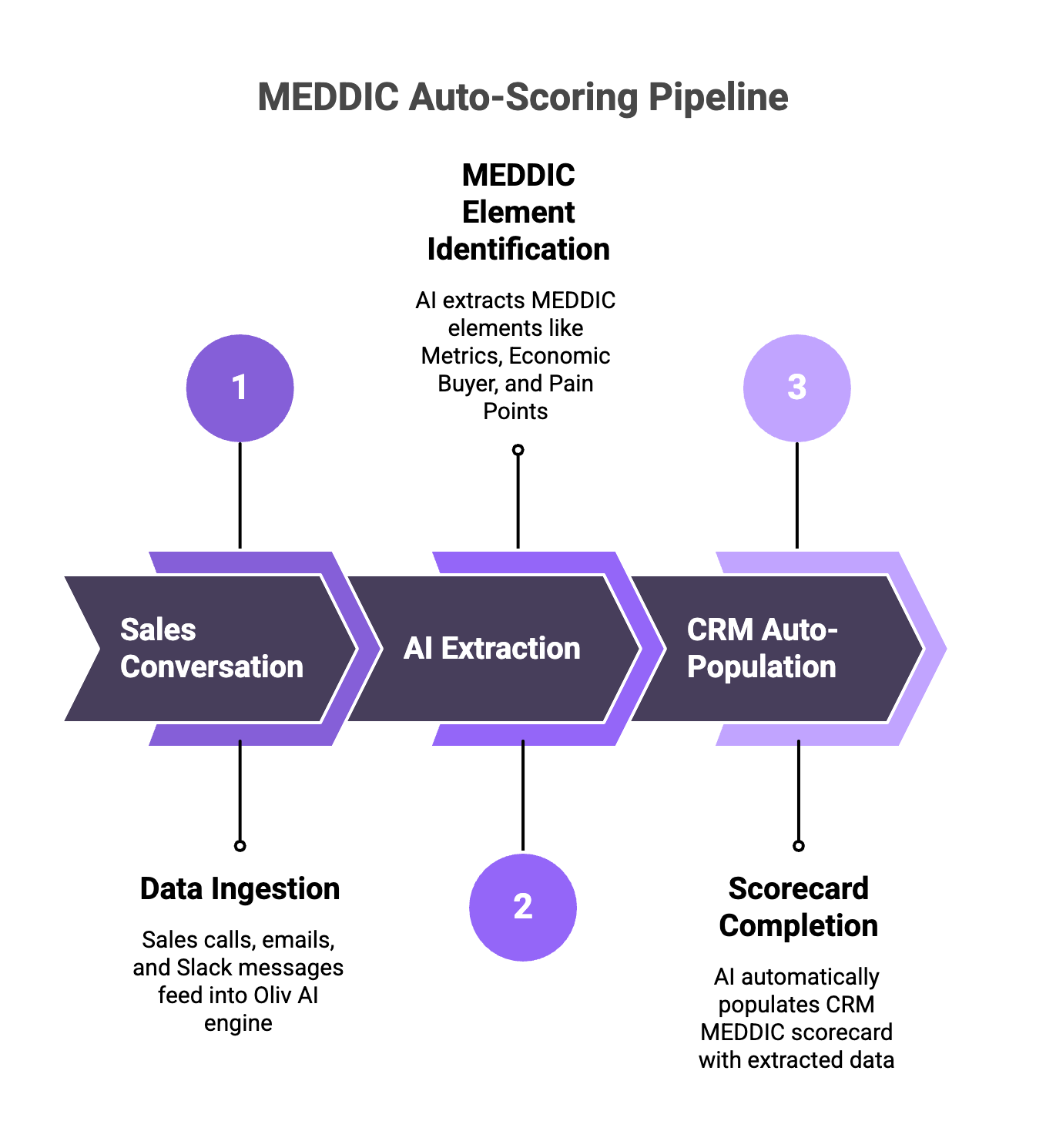
.png)
.png)






