AI for Revenue Operations: How Scaling SaaS Teams Use Forecast Scrubs, Deal Inspection, and CRM Hygiene Agents to Tighten Pipeline Without Adding Headcount
Written by
Ishan Chhabra
Last Updated :
June 20, 2026
Skim in :
8
mins
In this article
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions
TL;DR
AI for revenue operations means agentic AI that acts, not just predicts or drafts, autonomously scrubbing forecasts, inspecting deals, and cleaning CRM data under human oversight.
Five workflows carry most of the ROI: forecast scrub, deal inspection, CRM hygiene, lead enrichment, and renewal-risk detection, each tied to one measurable KPI.
Forecast inaccuracy is costly. Only 7% of teams hit 90%+ accuracy, and a 5-point lift on a $50M pipeline protects roughly $2.5M.
Data quality is the make-or-break prerequisite, but hygiene agents clean as they work, so you bootstrap clean data instead of gating AI behind a multi-year cleanup.
Roll out safely with a suggest, approve, automate trust ladder, and govern with monthly acceptance reviews plus quarterly accuracy audits.
Lean, scaling SaaS teams win most, gaining agentic coverage without the stacked $500-per-user tool bill or a large RevOps hire.
Q1. What Is Agentic AI for Sales, and How Does It Differ From Predictive and Generative AI? [toc=1. Agentic AI Defined]
A RevOps lead at a 60-rep SaaS company once showed me her Monday ritual: three dashboards open, a forecast spreadsheet she didn't trust, and a coffee going cold. The tools could tell her things. None of them could do anything. That gap, between knowing and acting, is exactly what agentic AI for sales closes. Agentic AI is software that doesn't just predict or draft, it acts. The capability model has three tiers: predictive AI scores deals and forecasts outcomes, generative AI writes the email or summary, and agentic AI autonomously inspects a deal, updates the CRM, and triggers next steps under human oversight. It is the shift from a dashboard you read to a teammate that executes.
The three-tier capability model
Most "AI for sales" pitches blur three very different things. Pulling them apart is the fastest way to cut through vendor noise.
Predictive AI scores and forecasts. It looks at historical patterns and says "this deal has a 40% chance to close." It informs. It does not move.
Generative AI creates. It drafts the follow-up email, the call summary, the account brief. It produces output, but a human still has to act on it.
Agentic AI executes. It chains steps together: read the call, update the MEDDPICC fields, draft the follow-up, flag the slipping deal, and route it to the right rep, with you approving where it matters.
Here is the simplest way I explain it to operators. Predictive AI is a weather report. Generative AI writes you a packing list. Agentic AI actually packs the bag and books the cab.
The capability ladder from predictive to agentic AI, the shift from reading a dashboard to a teammate that executes.
⚙️ One sales example across all three
Take a single discovery call. Predictive AI scores the resulting opportunity. Generative AI writes the recap and a draft follow-up. Agentic AI does the whole loop: it transcribes the call, populates the qualification scorecard, enriches the contact, drafts the email, and updates the forecast category, then waits for a human nod on anything revenue-impacting.
This is the layer where Oliv AI operates. Oliv is built as an AI-native data platform on fine-tuned LLMs, with a suite of named agents (Forecaster, Deal Driver, CRM Manager) that perform the work rather than just surface it. When we rebuilt the idea of the CRM internally, the goal was simple: make the system act, not just store. As our CEO Ishan Chhabra puts it, the aim is to make "your CRM fully autonomous."
🔭 Why 2026 is the agentic inflection
I could be slightly early on the timing, but where my head is right now: 2026 is when "agentic" stops being a slide and starts being a buying criterion. Predictive and generative AI were the previous two waves. Both still left a human doing the last mile of clicking, typing, and updating. The agentic wave automates that last mile.
The honest caveat is that autonomy without guardrails scares buyers, and it should. The pattern that actually works is human-in-the-loop: agents handle high-volume, low-risk work like CRM hygiene on their own, while a person stays on the calls that move money. That balance, not the autonomy itself, is what separates a useful agent from a liability. If you are mapping the broader category, our guide to revenue operations to intelligence to orchestration traces how these waves stack.
Q2. What Does Forecast Inaccuracy Actually Cost, and How Do You Calculate the ROI? [toc=2. Cost of Inaccuracy]
Here is the number that should bother every revenue leader: only 7% of sales teams hit forecast accuracy of 90% or more, and the median team lands somewhere between 70% and 79%, according to Gartner. Inaccuracy quietly drains revenue through missed quota and misallocated headcount. The fix is a simple equation: forecast-accuracy lift multiplied by pipeline value equals recovered revenue. On a $50M pipeline, even a 5-point accuracy gain protects $2.5M in better-allocated effort. That is the credibility math agentic forecasting is built to deliver, and it is the case Oliv AI makes to RevOps teams tired of guessing.
Only 7 percent of teams hit 90 percent accuracy, the gap a 5-point lift closes is worth $2.5M on a $50M pipeline.
The hidden cost of a wrong number
A bad forecast is not just an embarrassing board slide. It misroutes everything downstream.
Headcount gets misallocated. You hire against pipeline that was never real.
Deals get under-resourced. The genuinely winnable ones don't get exec air cover because the forecast buried them.
Trust erodes. Once leadership stops believing the number, every review becomes a negotiation instead of a decision.
The root cause is usually data, not effort. Salesforce has reported that the vast majority of CRM data is incomplete or out of date, and forecasts built on that foundation inherit the rot. Garbage in, confident-looking garbage out.
🧮 The accuracy-to-revenue equation
I want to give you something you can actually take to a CFO, not a vibe. Here is the equation, worked. Recovered Revenue equals Pipeline Value multiplied by Forecast-Accuracy Lift.
Say you run a $50M annual pipeline and you move forecast accuracy up 5 points. That is $2.5M of effort, attention, and capital that now lands on the right deals instead of the wrong ones. Industry analysis suggests AI-driven forecasting typically closes the accuracy gap by 10 to 20 percentage points in the first year, with best-in-class teams landing within 5% of actual revenue. Run the same math at a 10-point lift and the number doubles.
📈 The upside is bigger than the savings
The defensive case (stop wasting effort) is only half of it. McKinsey estimates generative AI could add the equivalent of $0.8 trillion to $1.2 trillion in productivity across sales and marketing functions, with sales productivity uplift in the range of 3% to 5% of global sales spend.
I might be wrong on exactly how fast that lands for any single team. But from what surfaces when you actually run agentic forecasting, the productivity gain is real in a boring, specific way: managers stop spending Thursday and Friday on roll-ups. Oliv's Forecaster Agent, for example, inspects every deal line-by-line and delivers a one-page roll-up with risk commentary to manager inboxes every Monday, which is exactly the manual labor the McKinsey numbers assume you'll reclaim. For a head-to-head on legacy roll-ups, see our breakdown of Gong forecasting.
Q3. How Accurate Is Agentic Forecasting? The Method-Tier Benchmark [toc=3. Method-Tier Benchmark]
Forecast accuracy rises with method maturity, not brand name. Gut-feel and manual rep rollups swing wildly; CRM-stage forecasting adds discipline; predictive AI tightens the variance; and agentic forecasting, which continuously scrubs every signal, delivers the tightest, least-biased numbers. The table below lets you locate your team today and see the accuracy lift each upgrade unlocks. This is the benchmark Oliv AI uses to show RevOps leaders where their current method actually sits, and it pairs well with our roundup of the best revenue intelligence software platforms.
The method-tier accuracy benchmark
The single most useful thing I can hand a skeptical VP of Sales is this: forecast accuracy is a function of how you forecast, not which logo you bought. Here is the ladder, with the approximate accuracy band each tier tends to produce.
Forecast method
Typical accuracy band
Main bias source
Effort to run
Data it needs
Gut-feel / rep commit
50 to 65%
Rep optimism, sandbagging
Low (but unreliable)
None structured
Manual rep rollup
60 to 75%
Aggregated rep bias
High (manager hours)
CRM stage fields
CRM-stage weighted
70 to 79% (median)
Stale stage data
Medium
Disciplined stage hygiene
Predictive AI
80 to 88%
Historical-pattern drift
Low after setup
Clean historical data
Agentic (signal-scrubbed)
90%+ (top tier)
Minimal, continuously corrected
Very low (autonomous)
Multi-source live signals
The jump from CRM-stage to predictive is where most teams get their first big lift, and analysis shows AI-driven forecasting typically adds 10 to 20 points of accuracy in year one. The jump from predictive to agentic is subtler but compounding: instead of scoring a snapshot, the system keeps correcting the number as new signals land.
🧭 Why method, not tool, drives the result
The standard read gets this backwards. People shop for a forecasting tool when they should be upgrading their forecasting method. A pretty Clari dashboard fed by stale, rep-entered stage data is still a tier-three forecast wearing a tier-five outfit. Our look at Clari features digs into exactly where that gap shows up.
This shows up plainly in real user reviews. Clari is genuinely strong at presenting a forecast, but operators repeatedly note it inherits whatever the CRM feeds it.
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit, so that is entirely handheld by using the built-in notes field as a calculator." Dexter L., Customer Success Executive Clari G2 Verified Review
"I find the setup process challenging, especially when migrating fields from Salesforce. This requires creating and maintaining duplicate fields, which adds complexity and workload." Josiah R., Head of Sales Operations Clari G2 Verified Review
The pattern is consistent: the visualization is fine, but a human is still hand-feeding the accuracy. Agentic forecasting attacks that root cause. Oliv's Forecaster Agent inspects each deal against signals stitched from calls, emails, and Slack rather than waiting for a rep to update a stage, which is how it pushes toward that top-tier band instead of just charting a mid-tier one.
Q4. Which Agentic Sales Workflows Deliver Value, and What KPI Does Each Move? [toc=4. Agent Workflows & KPIs]
Five agentic workflows carry most of the ROI, and each ties to exactly one KPI: forecast scrub (forecast accuracy %), deal inspection (slipped-deal rate), CRM hygiene (field-completeness %), lead enrichment (qualified-lead conversion %), and renewal-risk detection (gross revenue retention). Instead of dashboards you dig through, named agents run these continuously, scrubbing data, flagging at-risk deals, and updating records autonomously under human review. This is the core of how Oliv AI converts "AI for sales" from a slogan into measurable movement, and it sits at the center of the best AI sales tools conversation.
The trap most teams fall into is buying capability without a target. An agent that "helps with forecasting" is unaccountable. An agent that moves forecast accuracy from 72% to 90% is a budget line you can defend. Here are the five, each pinned to one number.
Five agentic workflows, each pinned to one KPI, the difference between vague capability and defensible budget.
1.1 ⚖️ Forecast scrub → forecast accuracy %
The agent continuously inspects every open deal, line by line, and reconciles the rep's commit against actual signals: email cadence, stakeholder engagement, and call sentiment. It catches the deal a rep "commits" while ignoring that the economic buyer went dark 14 days ago.
Before: a manager spends Thursday and Friday on manual roll-ups, then submits a number nobody fully trusts.
After: an autonomous roll-up lands Monday morning with risk commentary attached.
Oliv's Forecaster Agent does exactly this and, per internal benchmarks, targets roughly 98% forecast accuracy versus the 67% typical of purely rep-driven forecasting. That maps directly to the top accuracy tier from the benchmark above.
1.2 🔍 Deal inspection → slipped-deal rate
Deals rarely die loudly. They go quiet. A deal-inspection agent flags the ones drifting out of motion before they slip a quarter, so intervention happens while it still matters.
"Before Gong we had a lack of visibility across our deals because information was siloed in several places like CRM, Email, Zoom, phone. Now we can measure forecasting accuracy and have confidence in what is going to close and when." Scott T., Director of Sales Gong G2 Verified Review
That visibility is real, but note the limit operators hit with note-taker-first tools.
"For me, the only business problem gong solves is the call recordings. Understanding the pipeline management portion of it is almost impossible." John S., Senior Account Executive Gong G2 Verified Review
Oliv's Deal Driver Agent flags deals needing daily attention and reports that, for example, 68% of stalled Proposal deals had no economic-buyer touch in the last 14 days, turning inspection into a specific, fixable action rather than a screen to scroll. If you are weighing options here, our Gong vs Oliv comparison lays out the difference.
1.3 🧹 CRM hygiene → field-completeness %
This is the unglamorous one that quietly powers everything else. Dirty data sinks forecasts, scoring, and routing alike. A hygiene agent creates contacts, enriches accounts, merges duplicates, and populates methodology fields (MEDDPICC, BANT) straight from conversation context, with no rep typing required. The theory behind those fields is worth a refresher in our MEDDIC sales methodology guide.
"I love I can send off hundreds of emails in bulk. My frustration is with the UI. It feels very clonky and a lot of times groove is frequently saying an issue has occured." Bethany C., Customer Success Manager Clari G2 Verified Review
Manual upkeep is where reps tap out. Oliv's CRM Manager Agent, trained on 100+ sales methodologies, populates up to 100 custom fields from call context, which is how it lifts field-completeness without the late-night data-entry slog.
1.4 🔎 Lead enrichment → qualified-lead conversion %
Cold outreach fails when reps skip prep. An enrichment agent builds the account dossier (buyer pains, decision map, recent triggers) before the first touch, so outreach lands as context-rich instead of generic.
Before: an SDR burns 15 to 20 minutes per account mining LinkedIn and Crunchbase, then sends a templated note.
After: the dossier is ready, the angle is tailored, and reply rates climb.
Oliv's Researcher/Prospector Agent generates these dossiers in minutes by pulling from the web, LinkedIn, and Crunchbase, which moves the needle on qualified-lead conversion rather than raw volume.
This is the workflow most forecast-centric competitors under-serve, and it is pure margin. A renewal-risk agent watches engagement signals across the customer book and surfaces accounts drifting toward churn well before the renewal call.
The signal that matters is silence at the top: a key sponsor who hasn't engaged in 60 days is a leading churn indicator, not a lagging one. Oliv's Retention Forecaster surfaces exactly this, for instance flagging that renewal rates can drop from 94% to 71% when an executive sponsor goes untouched for 60 days, then triggering the play to re-engage. Pairing forecast scrub with renewal-risk is the "lean revenue team" angle: you cover both new-business accuracy and retention without standing up a separate RevOps function for each.
A fair caveat: Oliv's Voice Agent, which calls reps nightly to capture off-the-record renewal and deal updates, is still in alpha, and full custom workflow configuration typically takes two to four weeks. The baseline agents, though, deploy in about 15 minutes, which is why I'd start a lean team on hygiene and forecast scrub first and expand into renewal-risk as trust builds. For the wider category map, our guide to the best revenue orchestration platform tools shows where these workflows fit.
Q5. Why Is Data Quality the Make-or-Break Prerequisite for Agentic AI? [toc=5. Data-Quality Prerequisite]
A RevOps lead at a mid-market SaaS shop told me she turned on a shiny new AI scoring tool and watched it confidently rank a dead account as her hottest deal. The reason was boring: the contact had left the company eight months earlier, and nobody updated the record. That is the whole problem in one scene.
The situation: autonomy amplifies dirty data
Agentic AI is only as good as the data it acts on. Salesforce has reported that the overwhelming majority of CRM records are incomplete or inaccurate, with some studies putting the figure near 90%. With a dashboard, bad data just misleads a human. With an agent, bad data gets acted on automatically.
That is the complication nobody warns you about. An agent updating fields, drafting outreach, and shifting forecast categories on rotten inputs produces autonomous garbage, at scale, faster than any human could. Garbage in, garbage out, but now with a turbo button.
✅ The resolution: a quick data-readiness check
Before you let agents touch anything, run a simple baseline. You do not need a six-month cleanup project first, you need to know where you stand.
Field completeness: What share of open deals have the basics filled, like amount, close date, and next step?
Source coverage: Are calls, emails, and Slack actually connected, or is the CRM your only (thin) signal?
De-duplication: How many duplicate accounts and contacts are quietly splitting your data?
Recency: When was each open opportunity last genuinely touched, not just auto-stamped?
Here is the contrarian part. The standard read says "clean your data, then deploy AI." I think that gets the sequencing backwards for one specific category: hygiene agents. A full manual data clean can be a two-to-three-year slog, while a CRM-hygiene agent cleans as it works. This is the same logic behind our broader take on revenue intelligence platforms.
This is exactly the wedge Oliv AI uses. Our CRM Manager Agent creates contacts, merges duplicates, and populates methodology fields like MEDDPICC straight from conversation context, so the data gets cleaner with every call instead of waiting on a cleanup project. I might be slightly biased here, but from what surfaces when you actually run this, bootstrapping clean data through the agent beats gating the agent behind clean data. If you are weighing alternatives, our roundup of the best AI sales tools shows where hygiene-first agents fit.
Q6. How Do You Roll Out Agentic AI Safely With a Human-in-the-Loop Framework? [toc=6. Human-in-the-Loop Rollout]
By the end of this section, you will have a simple, defensible way to deploy agents without a board member asking why a bot emailed your biggest customer. Safe agentic adoption follows three escalating trust tiers: suggest, approve, and automate. Start agents on high-volume, low-risk work, keep humans on revenue-impacting moves, and widen autonomy as accuracy proves out. That is the framework Oliv AI uses to de-risk rollout, and it complements our guide to Agentforce implementation.
The suggest, approve, automate ladder
Think of agent autonomy like onboarding a new hire. You do not hand a week-one rep the biggest renewal. You earn trust in stages.
Suggest: The agent recommends, a human acts. It flags "this deal looks at risk," and the rep decides. Lowest risk, fastest to trust.
Approve: The agent drafts the action, a human one-clicks. It writes the follow-up or fills the CRM field, you confirm before it commits.
Automate: The agent executes low-risk tasks alone. Things like merging obvious duplicates or logging call notes run without a babysitter.
The point is that autonomy is a dial, not a switch. You move each workflow up the ladder as its accuracy earns the next rung.
The suggest, approve, automate ladder, each workflow climbs a rung only after its accuracy earns the next level of autonomy.
🎯 Sequencing what to automate first
The order matters more than the tooling. Get this wrong and adoption stalls, because one bad autonomous action poisons trust for everything else.
Automate early: CRM hygiene, call logging, and contact enrichment. High volume, low blast radius if wrong.
Keep at approve: Outbound emails, forecast category changes, and stakeholder messaging. Reversible, but customer-facing.
Keep human: The actual sales conversation, pricing calls, and exec relationships. The work only a person should own.
A governance checkpoint helps at each promotion: track the agent's acceptance rate (how often humans accept its suggestions) before moving it up a tier. I could be wrong on the exact thresholds for your team, but the principle holds. Earn the rung, then climb. The MEDDPICC fields these agents populate are worth understanding deeply, which our MEDDIC sales methodology guide covers.
This maps cleanly to how Oliv's agents work in practice. The CRM Manager nudges reps to validate data before pushing updates autonomously, which is "approve" graduating to "automate" as confidence builds. The honest caveat: our Voice Agent, which calls reps nightly for deal updates, is still in alpha, so I would keep that one firmly in the suggest tier for now. For teams comparing setup paths, our Gong implementation timeline breakdown is a useful reference point.
Q7. How Do You Evaluate Vendors? The Agentic Sales AI Buying-Criteria Matrix [toc=7. Buying-Criteria Matrix]
The best way to choose an agentic sales platform is to score every vendor on four axes: forecast-accuracy lift, conversation-intelligence depth, agentic execution, and CRM-native fit. The matrix below turns a noisy, overcrowded market into a like-for-like comparison. It is also the lens Oliv AI is happy to be measured against, because it rewards action over dashboards. For a deeper field scan, see our list of the best revenue intelligence software platforms.
The four axes that actually matter
Most "best AI sales tool" lists compare feature counts. That is noise. These four criteria predict whether the thing will move revenue.
Forecast-accuracy lift: Does it measurably tighten your forecast, or just visualize the same shaky number prettier?
Conversation-intelligence depth: Does it read calls, emails, and tickets, or only record calls?
Agentic execution: Does it take action, or does it stop at "here's a report, good luck"?
CRM-native fit: Does it sync both ways without locking your data in?
The trap is buying a strong tool on the wrong axis. A team needing forecast accuracy should not over-index on a category leader that is, at its core, a call recorder. Our Gong vs Clari comparison shows how easily teams pick the wrong axis.
📊 Scoring the field
Here is a vendor-neutral read, grounded in what operators actually report. Weight the axes by your own constraint: forecast-led teams weight the first column, prospecting-led teams the second.
Platform
Forecast-accuracy lift
Conversation depth
Agentic execution
CRM-native fit
Clari
Strong (forecast-first)
Moderate (Copilot)
Low (reports, not actions)
Good, but a "glorified SFDC overlay" per users
Gong
Moderate (add-on)
Strong (calls)
Low (note-taker core)
Limited bulk export
Outreach
Low
Low (sequencing)
Low
Sync breaks reported
Salesforce Agentforce
Moderate
Moderate
Emerging (config-heavy)
Native, but setup-heavy
Oliv AI
Strong (98% target)
Strong (calls, email, Slack)
High (named agents act)
Bi-directional, full open export
The red flags worth screening for show up loudly in reviews.
"It is really just a glorified SFDC overlay. Definitely overkill for most companies." conaldinho11, r/SalesOperations Reddit Thread
"The price of Agentforce is not clear and hard to find. Adoption is low. Customers are finding issues in deploying and using agents in Salesforce." Anusha T., Web Developer Salesforce Agentforce G2 Verified Review
"The engage product is stagnant. Looks to have the same features, UX, integrations and issues as it had 5 years ago." Matthew T., Head of Revenue Operations Outreach G2 Verified Review
Where Oliv scores well is the agentic-execution column most others leave empty: named agents that act, plus a full open export policy so your data is never hostage. Score honestly, and the gaps pick the winner for you. For a direct head-to-head, our Gong vs Oliv breakdown applies this same matrix.
Q8. Which Teams Benefit Most, and Why Lean SaaS Teams Win With Agentic AI? [toc=8. Best-Fit Teams]
The short answer: lean SaaS teams gain the most, because they have no large RevOps function to manually scrub forecasts or chase CRM hygiene. Agents replace headcount they cannot justify hiring. High-velocity B2B teams, fast-scaling startups, and renewal-heavy subscription businesses all see outsized returns. Oliv AI is built squarely for that lean, fast-moving profile, which we explore further in our guide to the best AI sales forecasting software.
Why lean teams get the biggest lift
A 200-person enterprise can throw five RevOps analysts at dirty data. A 30-rep scale-up cannot. For the lean team, an agent is not a nice-to-have, it is the RevOps hire they will not make.
The math is simple. When one ops person supports 25 reps, every hour the agent saves on hygiene, roll-ups, and prep is an hour that does not need a new salary behind it. Automation becomes a force-multiplier exactly where the budget is tightest.
🎯 If you are X, here is the fit
Match your situation to the call, including the honest "not for you" cases.
High-velocity B2B SaaS, 15 to 20 day cycles, drowning in dirty data: strong fit. Pipeline moves too fast for manual roll-ups.
Seed or Series A startup with 5 to 25 reps, no RevOps team: strong fit. Build the motion right from day one.
Renewal-heavy subscription business: strong fit. Renewal-risk detection protects retention without a dedicated CS-ops team.
❌ Pure B2C support automation: not the best fit. Look at a service-first agent platform instead.
❌ Teams wanting only basic call recording: overkill. A simple recorder is cheaper.
The operator pain that makes the case is everywhere in reviews of legacy stacks.
"It was a big mistake on our part to commit to a two year term. We are stuck with a tool that works technically but isnt the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"Once we started scaling to more users and use cases, the cost ramped up pretty quickly. We had to rethink a few workflows just to stay within budget." Reviewer, Salesforce Agentforce Salesforce Agentforce G2 Verified Review
That is the lean-team trap: paying enterprise prices for adoption you cannot fund. Oliv's modular, pay-for-what-you-use pricing (agents like the CRM Manager available individually, with no mandatory platform fee on many tiers) is designed so a 25-rep team gets agentic coverage without the $500-per-user stacked bill. If you are that team, this is the angle the bigger vendors quietly under-serve, as our roundup of the best Agentforce alternatives and competitors details.
Q9. How Do You Measure Success and Govern Agentic AI Over Time? [toc=9. Measurement & Governance]
A VP of Sales once asked me, "We turned the agents on. Now how do I know they're still working in six months?" That question is the whole game. Most teams measure agentic AI once, at the ROI pitch, then never check the dials again. Post-launch, you track the same KPIs each workflow targets, like forecast accuracy, gross revenue retention (GRR), and field completeness, plus agent-specific health metrics like action-acceptance rate and override frequency. Then you govern with periodic accuracy audits, drift monitoring, and clear ownership so autonomy stays accountable. Measurement is not a one-time ROI check, it is the control loop that lets you safely expand what the agents do. This is the discipline Oliv AI builds into its deployments rather than bolting on later, and it underpins our view of the best revenue intelligence software platforms.
The two layers of metrics you actually need
Here is the mistake I see constantly: teams track outcome KPIs and ignore agent-health KPIs. You need both, because one tells you if it's working and the other tells you why.
Outcome KPIs (the result): forecast accuracy %, gross revenue retention (the share of recurring revenue you keep), field-completeness %, and slipped-deal rate. These prove revenue impact.
Agent-health KPIs (the engine): action-acceptance rate (how often humans accept the agent's suggestions), override frequency (how often they reject it), and time-to-action. These predict trust.
The signal I watch most is override frequency. If reps suddenly start rejecting an agent's CRM updates, something drifted, and the outcome KPI hasn't caught up yet. Acceptance rate is your early-warning system, not a vanity stat. For teams refining the forecast number specifically, our guide to the best AI sales forecasting software goes deeper.
⏰ Governance is a cadence, not a launch event
Drift is the quiet killer. Your data changes, your sales motion changes, and an agent tuned for last quarter slowly gets things wrong. "Drift" just means the model's accuracy decaying as reality shifts underneath it.
A simple governance cadence keeps autonomy honest.
Monthly: review acceptance and override rates per agent. Flag any agent trending down.
Quarterly: run an accuracy audit. Sample agent actions and grade them against ground truth.
Always: assign one named owner per agent. Unowned automation is how you get a bot emailing a churned customer.
The contrarian point here: the standard read treats governance as a brake on autonomy. I think it is the opposite. Tight measurement is what earns you the right to expand autonomy, because each clean audit lets you promote another workflow from "approve" to "automate" with evidence, not hope. The same accountability logic shapes our take on revenue operations to intelligence to orchestration.
This is exactly why our agents are built to nudge reps to validate data before pushing updates, which generates the acceptance-rate signal automatically. When we run our own forecast reviews on Oliv agents, that override data is the dashboard we watch, not a buried log. I could be wrong on the perfect audit frequency for every team, but from what surfaces when you actually run this, the teams that audit quarterly expand autonomy roughly twice as fast as the ones that "set and forget." If you are benchmarking against legacy roll-ups, our breakdown of Gong forecasting is a useful comparison.
🔭 Where I think this goes next
Where my head is right now: the next two years quietly flip the model. The SaaS you log into becomes agents that work for you, and revenue orchestration gives way to revenue engineering. The open question I keep sitting with is governance itself. When agents start auditing other agents, who owns the override?
I don't have a clean answer yet, and I'd genuinely rather trade notes than pretend I do. If you're running agents in production and watching your own acceptance rates move, I want to hear what your dials are telling you. For the wider category shift, our guide to the best revenue orchestration platform tools maps where this is heading.
Q1. What Is Agentic AI for Sales, and How Does It Differ From Predictive and Generative AI? [toc=1. Agentic AI Defined]
A RevOps lead at a 60-rep SaaS company once showed me her Monday ritual: three dashboards open, a forecast spreadsheet she didn't trust, and a coffee going cold. The tools could tell her things. None of them could do anything. That gap, between knowing and acting, is exactly what agentic AI for sales closes. Agentic AI is software that doesn't just predict or draft, it acts. The capability model has three tiers: predictive AI scores deals and forecasts outcomes, generative AI writes the email or summary, and agentic AI autonomously inspects a deal, updates the CRM, and triggers next steps under human oversight. It is the shift from a dashboard you read to a teammate that executes.
The three-tier capability model
Most "AI for sales" pitches blur three very different things. Pulling them apart is the fastest way to cut through vendor noise.
Predictive AI scores and forecasts. It looks at historical patterns and says "this deal has a 40% chance to close." It informs. It does not move.
Generative AI creates. It drafts the follow-up email, the call summary, the account brief. It produces output, but a human still has to act on it.
Agentic AI executes. It chains steps together: read the call, update the MEDDPICC fields, draft the follow-up, flag the slipping deal, and route it to the right rep, with you approving where it matters.
Here is the simplest way I explain it to operators. Predictive AI is a weather report. Generative AI writes you a packing list. Agentic AI actually packs the bag and books the cab.
The capability ladder from predictive to agentic AI, the shift from reading a dashboard to a teammate that executes.
⚙️ One sales example across all three
Take a single discovery call. Predictive AI scores the resulting opportunity. Generative AI writes the recap and a draft follow-up. Agentic AI does the whole loop: it transcribes the call, populates the qualification scorecard, enriches the contact, drafts the email, and updates the forecast category, then waits for a human nod on anything revenue-impacting.
This is the layer where Oliv AI operates. Oliv is built as an AI-native data platform on fine-tuned LLMs, with a suite of named agents (Forecaster, Deal Driver, CRM Manager) that perform the work rather than just surface it. When we rebuilt the idea of the CRM internally, the goal was simple: make the system act, not just store. As our CEO Ishan Chhabra puts it, the aim is to make "your CRM fully autonomous."
🔭 Why 2026 is the agentic inflection
I could be slightly early on the timing, but where my head is right now: 2026 is when "agentic" stops being a slide and starts being a buying criterion. Predictive and generative AI were the previous two waves. Both still left a human doing the last mile of clicking, typing, and updating. The agentic wave automates that last mile.
The honest caveat is that autonomy without guardrails scares buyers, and it should. The pattern that actually works is human-in-the-loop: agents handle high-volume, low-risk work like CRM hygiene on their own, while a person stays on the calls that move money. That balance, not the autonomy itself, is what separates a useful agent from a liability. If you are mapping the broader category, our guide to revenue operations to intelligence to orchestration traces how these waves stack.
Q2. What Does Forecast Inaccuracy Actually Cost, and How Do You Calculate the ROI? [toc=2. Cost of Inaccuracy]
Here is the number that should bother every revenue leader: only 7% of sales teams hit forecast accuracy of 90% or more, and the median team lands somewhere between 70% and 79%, according to Gartner. Inaccuracy quietly drains revenue through missed quota and misallocated headcount. The fix is a simple equation: forecast-accuracy lift multiplied by pipeline value equals recovered revenue. On a $50M pipeline, even a 5-point accuracy gain protects $2.5M in better-allocated effort. That is the credibility math agentic forecasting is built to deliver, and it is the case Oliv AI makes to RevOps teams tired of guessing.
Only 7 percent of teams hit 90 percent accuracy, the gap a 5-point lift closes is worth $2.5M on a $50M pipeline.
The hidden cost of a wrong number
A bad forecast is not just an embarrassing board slide. It misroutes everything downstream.
Headcount gets misallocated. You hire against pipeline that was never real.
Deals get under-resourced. The genuinely winnable ones don't get exec air cover because the forecast buried them.
Trust erodes. Once leadership stops believing the number, every review becomes a negotiation instead of a decision.
The root cause is usually data, not effort. Salesforce has reported that the vast majority of CRM data is incomplete or out of date, and forecasts built on that foundation inherit the rot. Garbage in, confident-looking garbage out.
🧮 The accuracy-to-revenue equation
I want to give you something you can actually take to a CFO, not a vibe. Here is the equation, worked. Recovered Revenue equals Pipeline Value multiplied by Forecast-Accuracy Lift.
Say you run a $50M annual pipeline and you move forecast accuracy up 5 points. That is $2.5M of effort, attention, and capital that now lands on the right deals instead of the wrong ones. Industry analysis suggests AI-driven forecasting typically closes the accuracy gap by 10 to 20 percentage points in the first year, with best-in-class teams landing within 5% of actual revenue. Run the same math at a 10-point lift and the number doubles.
📈 The upside is bigger than the savings
The defensive case (stop wasting effort) is only half of it. McKinsey estimates generative AI could add the equivalent of $0.8 trillion to $1.2 trillion in productivity across sales and marketing functions, with sales productivity uplift in the range of 3% to 5% of global sales spend.
I might be wrong on exactly how fast that lands for any single team. But from what surfaces when you actually run agentic forecasting, the productivity gain is real in a boring, specific way: managers stop spending Thursday and Friday on roll-ups. Oliv's Forecaster Agent, for example, inspects every deal line-by-line and delivers a one-page roll-up with risk commentary to manager inboxes every Monday, which is exactly the manual labor the McKinsey numbers assume you'll reclaim. For a head-to-head on legacy roll-ups, see our breakdown of Gong forecasting.
Q3. How Accurate Is Agentic Forecasting? The Method-Tier Benchmark [toc=3. Method-Tier Benchmark]
Forecast accuracy rises with method maturity, not brand name. Gut-feel and manual rep rollups swing wildly; CRM-stage forecasting adds discipline; predictive AI tightens the variance; and agentic forecasting, which continuously scrubs every signal, delivers the tightest, least-biased numbers. The table below lets you locate your team today and see the accuracy lift each upgrade unlocks. This is the benchmark Oliv AI uses to show RevOps leaders where their current method actually sits, and it pairs well with our roundup of the best revenue intelligence software platforms.
The method-tier accuracy benchmark
The single most useful thing I can hand a skeptical VP of Sales is this: forecast accuracy is a function of how you forecast, not which logo you bought. Here is the ladder, with the approximate accuracy band each tier tends to produce.
Forecast method
Typical accuracy band
Main bias source
Effort to run
Data it needs
Gut-feel / rep commit
50 to 65%
Rep optimism, sandbagging
Low (but unreliable)
None structured
Manual rep rollup
60 to 75%
Aggregated rep bias
High (manager hours)
CRM stage fields
CRM-stage weighted
70 to 79% (median)
Stale stage data
Medium
Disciplined stage hygiene
Predictive AI
80 to 88%
Historical-pattern drift
Low after setup
Clean historical data
Agentic (signal-scrubbed)
90%+ (top tier)
Minimal, continuously corrected
Very low (autonomous)
Multi-source live signals
The jump from CRM-stage to predictive is where most teams get their first big lift, and analysis shows AI-driven forecasting typically adds 10 to 20 points of accuracy in year one. The jump from predictive to agentic is subtler but compounding: instead of scoring a snapshot, the system keeps correcting the number as new signals land.
🧭 Why method, not tool, drives the result
The standard read gets this backwards. People shop for a forecasting tool when they should be upgrading their forecasting method. A pretty Clari dashboard fed by stale, rep-entered stage data is still a tier-three forecast wearing a tier-five outfit. Our look at Clari features digs into exactly where that gap shows up.
This shows up plainly in real user reviews. Clari is genuinely strong at presenting a forecast, but operators repeatedly note it inherits whatever the CRM feeds it.
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit, so that is entirely handheld by using the built-in notes field as a calculator." Dexter L., Customer Success Executive Clari G2 Verified Review
"I find the setup process challenging, especially when migrating fields from Salesforce. This requires creating and maintaining duplicate fields, which adds complexity and workload." Josiah R., Head of Sales Operations Clari G2 Verified Review
The pattern is consistent: the visualization is fine, but a human is still hand-feeding the accuracy. Agentic forecasting attacks that root cause. Oliv's Forecaster Agent inspects each deal against signals stitched from calls, emails, and Slack rather than waiting for a rep to update a stage, which is how it pushes toward that top-tier band instead of just charting a mid-tier one.
Q4. Which Agentic Sales Workflows Deliver Value, and What KPI Does Each Move? [toc=4. Agent Workflows & KPIs]
Five agentic workflows carry most of the ROI, and each ties to exactly one KPI: forecast scrub (forecast accuracy %), deal inspection (slipped-deal rate), CRM hygiene (field-completeness %), lead enrichment (qualified-lead conversion %), and renewal-risk detection (gross revenue retention). Instead of dashboards you dig through, named agents run these continuously, scrubbing data, flagging at-risk deals, and updating records autonomously under human review. This is the core of how Oliv AI converts "AI for sales" from a slogan into measurable movement, and it sits at the center of the best AI sales tools conversation.
The trap most teams fall into is buying capability without a target. An agent that "helps with forecasting" is unaccountable. An agent that moves forecast accuracy from 72% to 90% is a budget line you can defend. Here are the five, each pinned to one number.
Five agentic workflows, each pinned to one KPI, the difference between vague capability and defensible budget.
1.1 ⚖️ Forecast scrub → forecast accuracy %
The agent continuously inspects every open deal, line by line, and reconciles the rep's commit against actual signals: email cadence, stakeholder engagement, and call sentiment. It catches the deal a rep "commits" while ignoring that the economic buyer went dark 14 days ago.
Before: a manager spends Thursday and Friday on manual roll-ups, then submits a number nobody fully trusts.
After: an autonomous roll-up lands Monday morning with risk commentary attached.
Oliv's Forecaster Agent does exactly this and, per internal benchmarks, targets roughly 98% forecast accuracy versus the 67% typical of purely rep-driven forecasting. That maps directly to the top accuracy tier from the benchmark above.
1.2 🔍 Deal inspection → slipped-deal rate
Deals rarely die loudly. They go quiet. A deal-inspection agent flags the ones drifting out of motion before they slip a quarter, so intervention happens while it still matters.
"Before Gong we had a lack of visibility across our deals because information was siloed in several places like CRM, Email, Zoom, phone. Now we can measure forecasting accuracy and have confidence in what is going to close and when." Scott T., Director of Sales Gong G2 Verified Review
That visibility is real, but note the limit operators hit with note-taker-first tools.
"For me, the only business problem gong solves is the call recordings. Understanding the pipeline management portion of it is almost impossible." John S., Senior Account Executive Gong G2 Verified Review
Oliv's Deal Driver Agent flags deals needing daily attention and reports that, for example, 68% of stalled Proposal deals had no economic-buyer touch in the last 14 days, turning inspection into a specific, fixable action rather than a screen to scroll. If you are weighing options here, our Gong vs Oliv comparison lays out the difference.
1.3 🧹 CRM hygiene → field-completeness %
This is the unglamorous one that quietly powers everything else. Dirty data sinks forecasts, scoring, and routing alike. A hygiene agent creates contacts, enriches accounts, merges duplicates, and populates methodology fields (MEDDPICC, BANT) straight from conversation context, with no rep typing required. The theory behind those fields is worth a refresher in our MEDDIC sales methodology guide.
"I love I can send off hundreds of emails in bulk. My frustration is with the UI. It feels very clonky and a lot of times groove is frequently saying an issue has occured." Bethany C., Customer Success Manager Clari G2 Verified Review
Manual upkeep is where reps tap out. Oliv's CRM Manager Agent, trained on 100+ sales methodologies, populates up to 100 custom fields from call context, which is how it lifts field-completeness without the late-night data-entry slog.
1.4 🔎 Lead enrichment → qualified-lead conversion %
Cold outreach fails when reps skip prep. An enrichment agent builds the account dossier (buyer pains, decision map, recent triggers) before the first touch, so outreach lands as context-rich instead of generic.
Before: an SDR burns 15 to 20 minutes per account mining LinkedIn and Crunchbase, then sends a templated note.
After: the dossier is ready, the angle is tailored, and reply rates climb.
Oliv's Researcher/Prospector Agent generates these dossiers in minutes by pulling from the web, LinkedIn, and Crunchbase, which moves the needle on qualified-lead conversion rather than raw volume.
This is the workflow most forecast-centric competitors under-serve, and it is pure margin. A renewal-risk agent watches engagement signals across the customer book and surfaces accounts drifting toward churn well before the renewal call.
The signal that matters is silence at the top: a key sponsor who hasn't engaged in 60 days is a leading churn indicator, not a lagging one. Oliv's Retention Forecaster surfaces exactly this, for instance flagging that renewal rates can drop from 94% to 71% when an executive sponsor goes untouched for 60 days, then triggering the play to re-engage. Pairing forecast scrub with renewal-risk is the "lean revenue team" angle: you cover both new-business accuracy and retention without standing up a separate RevOps function for each.
A fair caveat: Oliv's Voice Agent, which calls reps nightly to capture off-the-record renewal and deal updates, is still in alpha, and full custom workflow configuration typically takes two to four weeks. The baseline agents, though, deploy in about 15 minutes, which is why I'd start a lean team on hygiene and forecast scrub first and expand into renewal-risk as trust builds. For the wider category map, our guide to the best revenue orchestration platform tools shows where these workflows fit.
Q5. Why Is Data Quality the Make-or-Break Prerequisite for Agentic AI? [toc=5. Data-Quality Prerequisite]
A RevOps lead at a mid-market SaaS shop told me she turned on a shiny new AI scoring tool and watched it confidently rank a dead account as her hottest deal. The reason was boring: the contact had left the company eight months earlier, and nobody updated the record. That is the whole problem in one scene.
The situation: autonomy amplifies dirty data
Agentic AI is only as good as the data it acts on. Salesforce has reported that the overwhelming majority of CRM records are incomplete or inaccurate, with some studies putting the figure near 90%. With a dashboard, bad data just misleads a human. With an agent, bad data gets acted on automatically.
That is the complication nobody warns you about. An agent updating fields, drafting outreach, and shifting forecast categories on rotten inputs produces autonomous garbage, at scale, faster than any human could. Garbage in, garbage out, but now with a turbo button.
✅ The resolution: a quick data-readiness check
Before you let agents touch anything, run a simple baseline. You do not need a six-month cleanup project first, you need to know where you stand.
Field completeness: What share of open deals have the basics filled, like amount, close date, and next step?
Source coverage: Are calls, emails, and Slack actually connected, or is the CRM your only (thin) signal?
De-duplication: How many duplicate accounts and contacts are quietly splitting your data?
Recency: When was each open opportunity last genuinely touched, not just auto-stamped?
Here is the contrarian part. The standard read says "clean your data, then deploy AI." I think that gets the sequencing backwards for one specific category: hygiene agents. A full manual data clean can be a two-to-three-year slog, while a CRM-hygiene agent cleans as it works. This is the same logic behind our broader take on revenue intelligence platforms.
This is exactly the wedge Oliv AI uses. Our CRM Manager Agent creates contacts, merges duplicates, and populates methodology fields like MEDDPICC straight from conversation context, so the data gets cleaner with every call instead of waiting on a cleanup project. I might be slightly biased here, but from what surfaces when you actually run this, bootstrapping clean data through the agent beats gating the agent behind clean data. If you are weighing alternatives, our roundup of the best AI sales tools shows where hygiene-first agents fit.
Q6. How Do You Roll Out Agentic AI Safely With a Human-in-the-Loop Framework? [toc=6. Human-in-the-Loop Rollout]
By the end of this section, you will have a simple, defensible way to deploy agents without a board member asking why a bot emailed your biggest customer. Safe agentic adoption follows three escalating trust tiers: suggest, approve, and automate. Start agents on high-volume, low-risk work, keep humans on revenue-impacting moves, and widen autonomy as accuracy proves out. That is the framework Oliv AI uses to de-risk rollout, and it complements our guide to Agentforce implementation.
The suggest, approve, automate ladder
Think of agent autonomy like onboarding a new hire. You do not hand a week-one rep the biggest renewal. You earn trust in stages.
Suggest: The agent recommends, a human acts. It flags "this deal looks at risk," and the rep decides. Lowest risk, fastest to trust.
Approve: The agent drafts the action, a human one-clicks. It writes the follow-up or fills the CRM field, you confirm before it commits.
Automate: The agent executes low-risk tasks alone. Things like merging obvious duplicates or logging call notes run without a babysitter.
The point is that autonomy is a dial, not a switch. You move each workflow up the ladder as its accuracy earns the next rung.
The suggest, approve, automate ladder, each workflow climbs a rung only after its accuracy earns the next level of autonomy.
🎯 Sequencing what to automate first
The order matters more than the tooling. Get this wrong and adoption stalls, because one bad autonomous action poisons trust for everything else.
Automate early: CRM hygiene, call logging, and contact enrichment. High volume, low blast radius if wrong.
Keep at approve: Outbound emails, forecast category changes, and stakeholder messaging. Reversible, but customer-facing.
Keep human: The actual sales conversation, pricing calls, and exec relationships. The work only a person should own.
A governance checkpoint helps at each promotion: track the agent's acceptance rate (how often humans accept its suggestions) before moving it up a tier. I could be wrong on the exact thresholds for your team, but the principle holds. Earn the rung, then climb. The MEDDPICC fields these agents populate are worth understanding deeply, which our MEDDIC sales methodology guide covers.
This maps cleanly to how Oliv's agents work in practice. The CRM Manager nudges reps to validate data before pushing updates autonomously, which is "approve" graduating to "automate" as confidence builds. The honest caveat: our Voice Agent, which calls reps nightly for deal updates, is still in alpha, so I would keep that one firmly in the suggest tier for now. For teams comparing setup paths, our Gong implementation timeline breakdown is a useful reference point.
Q7. How Do You Evaluate Vendors? The Agentic Sales AI Buying-Criteria Matrix [toc=7. Buying-Criteria Matrix]
The best way to choose an agentic sales platform is to score every vendor on four axes: forecast-accuracy lift, conversation-intelligence depth, agentic execution, and CRM-native fit. The matrix below turns a noisy, overcrowded market into a like-for-like comparison. It is also the lens Oliv AI is happy to be measured against, because it rewards action over dashboards. For a deeper field scan, see our list of the best revenue intelligence software platforms.
The four axes that actually matter
Most "best AI sales tool" lists compare feature counts. That is noise. These four criteria predict whether the thing will move revenue.
Forecast-accuracy lift: Does it measurably tighten your forecast, or just visualize the same shaky number prettier?
Conversation-intelligence depth: Does it read calls, emails, and tickets, or only record calls?
Agentic execution: Does it take action, or does it stop at "here's a report, good luck"?
CRM-native fit: Does it sync both ways without locking your data in?
The trap is buying a strong tool on the wrong axis. A team needing forecast accuracy should not over-index on a category leader that is, at its core, a call recorder. Our Gong vs Clari comparison shows how easily teams pick the wrong axis.
📊 Scoring the field
Here is a vendor-neutral read, grounded in what operators actually report. Weight the axes by your own constraint: forecast-led teams weight the first column, prospecting-led teams the second.
Platform
Forecast-accuracy lift
Conversation depth
Agentic execution
CRM-native fit
Clari
Strong (forecast-first)
Moderate (Copilot)
Low (reports, not actions)
Good, but a "glorified SFDC overlay" per users
Gong
Moderate (add-on)
Strong (calls)
Low (note-taker core)
Limited bulk export
Outreach
Low
Low (sequencing)
Low
Sync breaks reported
Salesforce Agentforce
Moderate
Moderate
Emerging (config-heavy)
Native, but setup-heavy
Oliv AI
Strong (98% target)
Strong (calls, email, Slack)
High (named agents act)
Bi-directional, full open export
The red flags worth screening for show up loudly in reviews.
"It is really just a glorified SFDC overlay. Definitely overkill for most companies." conaldinho11, r/SalesOperations Reddit Thread
"The price of Agentforce is not clear and hard to find. Adoption is low. Customers are finding issues in deploying and using agents in Salesforce." Anusha T., Web Developer Salesforce Agentforce G2 Verified Review
"The engage product is stagnant. Looks to have the same features, UX, integrations and issues as it had 5 years ago." Matthew T., Head of Revenue Operations Outreach G2 Verified Review
Where Oliv scores well is the agentic-execution column most others leave empty: named agents that act, plus a full open export policy so your data is never hostage. Score honestly, and the gaps pick the winner for you. For a direct head-to-head, our Gong vs Oliv breakdown applies this same matrix.
Q8. Which Teams Benefit Most, and Why Lean SaaS Teams Win With Agentic AI? [toc=8. Best-Fit Teams]
The short answer: lean SaaS teams gain the most, because they have no large RevOps function to manually scrub forecasts or chase CRM hygiene. Agents replace headcount they cannot justify hiring. High-velocity B2B teams, fast-scaling startups, and renewal-heavy subscription businesses all see outsized returns. Oliv AI is built squarely for that lean, fast-moving profile, which we explore further in our guide to the best AI sales forecasting software.
Why lean teams get the biggest lift
A 200-person enterprise can throw five RevOps analysts at dirty data. A 30-rep scale-up cannot. For the lean team, an agent is not a nice-to-have, it is the RevOps hire they will not make.
The math is simple. When one ops person supports 25 reps, every hour the agent saves on hygiene, roll-ups, and prep is an hour that does not need a new salary behind it. Automation becomes a force-multiplier exactly where the budget is tightest.
🎯 If you are X, here is the fit
Match your situation to the call, including the honest "not for you" cases.
High-velocity B2B SaaS, 15 to 20 day cycles, drowning in dirty data: strong fit. Pipeline moves too fast for manual roll-ups.
Seed or Series A startup with 5 to 25 reps, no RevOps team: strong fit. Build the motion right from day one.
Renewal-heavy subscription business: strong fit. Renewal-risk detection protects retention without a dedicated CS-ops team.
❌ Pure B2C support automation: not the best fit. Look at a service-first agent platform instead.
❌ Teams wanting only basic call recording: overkill. A simple recorder is cheaper.
The operator pain that makes the case is everywhere in reviews of legacy stacks.
"It was a big mistake on our part to commit to a two year term. We are stuck with a tool that works technically but isnt the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"Once we started scaling to more users and use cases, the cost ramped up pretty quickly. We had to rethink a few workflows just to stay within budget." Reviewer, Salesforce Agentforce Salesforce Agentforce G2 Verified Review
That is the lean-team trap: paying enterprise prices for adoption you cannot fund. Oliv's modular, pay-for-what-you-use pricing (agents like the CRM Manager available individually, with no mandatory platform fee on many tiers) is designed so a 25-rep team gets agentic coverage without the $500-per-user stacked bill. If you are that team, this is the angle the bigger vendors quietly under-serve, as our roundup of the best Agentforce alternatives and competitors details.
Q9. How Do You Measure Success and Govern Agentic AI Over Time? [toc=9. Measurement & Governance]
A VP of Sales once asked me, "We turned the agents on. Now how do I know they're still working in six months?" That question is the whole game. Most teams measure agentic AI once, at the ROI pitch, then never check the dials again. Post-launch, you track the same KPIs each workflow targets, like forecast accuracy, gross revenue retention (GRR), and field completeness, plus agent-specific health metrics like action-acceptance rate and override frequency. Then you govern with periodic accuracy audits, drift monitoring, and clear ownership so autonomy stays accountable. Measurement is not a one-time ROI check, it is the control loop that lets you safely expand what the agents do. This is the discipline Oliv AI builds into its deployments rather than bolting on later, and it underpins our view of the best revenue intelligence software platforms.
The two layers of metrics you actually need
Here is the mistake I see constantly: teams track outcome KPIs and ignore agent-health KPIs. You need both, because one tells you if it's working and the other tells you why.
Outcome KPIs (the result): forecast accuracy %, gross revenue retention (the share of recurring revenue you keep), field-completeness %, and slipped-deal rate. These prove revenue impact.
Agent-health KPIs (the engine): action-acceptance rate (how often humans accept the agent's suggestions), override frequency (how often they reject it), and time-to-action. These predict trust.
The signal I watch most is override frequency. If reps suddenly start rejecting an agent's CRM updates, something drifted, and the outcome KPI hasn't caught up yet. Acceptance rate is your early-warning system, not a vanity stat. For teams refining the forecast number specifically, our guide to the best AI sales forecasting software goes deeper.
⏰ Governance is a cadence, not a launch event
Drift is the quiet killer. Your data changes, your sales motion changes, and an agent tuned for last quarter slowly gets things wrong. "Drift" just means the model's accuracy decaying as reality shifts underneath it.
A simple governance cadence keeps autonomy honest.
Monthly: review acceptance and override rates per agent. Flag any agent trending down.
Quarterly: run an accuracy audit. Sample agent actions and grade them against ground truth.
Always: assign one named owner per agent. Unowned automation is how you get a bot emailing a churned customer.
The contrarian point here: the standard read treats governance as a brake on autonomy. I think it is the opposite. Tight measurement is what earns you the right to expand autonomy, because each clean audit lets you promote another workflow from "approve" to "automate" with evidence, not hope. The same accountability logic shapes our take on revenue operations to intelligence to orchestration.
This is exactly why our agents are built to nudge reps to validate data before pushing updates, which generates the acceptance-rate signal automatically. When we run our own forecast reviews on Oliv agents, that override data is the dashboard we watch, not a buried log. I could be wrong on the perfect audit frequency for every team, but from what surfaces when you actually run this, the teams that audit quarterly expand autonomy roughly twice as fast as the ones that "set and forget." If you are benchmarking against legacy roll-ups, our breakdown of Gong forecasting is a useful comparison.
🔭 Where I think this goes next
Where my head is right now: the next two years quietly flip the model. The SaaS you log into becomes agents that work for you, and revenue orchestration gives way to revenue engineering. The open question I keep sitting with is governance itself. When agents start auditing other agents, who owns the override?
I don't have a clean answer yet, and I'd genuinely rather trade notes than pretend I do. If you're running agents in production and watching your own acceptance rates move, I want to hear what your dials are telling you. For the wider category shift, our guide to the best revenue orchestration platform tools maps where this is heading.
Q1. What Is Agentic AI for Sales, and How Does It Differ From Predictive and Generative AI? [toc=1. Agentic AI Defined]
A RevOps lead at a 60-rep SaaS company once showed me her Monday ritual: three dashboards open, a forecast spreadsheet she didn't trust, and a coffee going cold. The tools could tell her things. None of them could do anything. That gap, between knowing and acting, is exactly what agentic AI for sales closes. Agentic AI is software that doesn't just predict or draft, it acts. The capability model has three tiers: predictive AI scores deals and forecasts outcomes, generative AI writes the email or summary, and agentic AI autonomously inspects a deal, updates the CRM, and triggers next steps under human oversight. It is the shift from a dashboard you read to a teammate that executes.
The three-tier capability model
Most "AI for sales" pitches blur three very different things. Pulling them apart is the fastest way to cut through vendor noise.
Predictive AI scores and forecasts. It looks at historical patterns and says "this deal has a 40% chance to close." It informs. It does not move.
Generative AI creates. It drafts the follow-up email, the call summary, the account brief. It produces output, but a human still has to act on it.
Agentic AI executes. It chains steps together: read the call, update the MEDDPICC fields, draft the follow-up, flag the slipping deal, and route it to the right rep, with you approving where it matters.
Here is the simplest way I explain it to operators. Predictive AI is a weather report. Generative AI writes you a packing list. Agentic AI actually packs the bag and books the cab.
The capability ladder from predictive to agentic AI, the shift from reading a dashboard to a teammate that executes.
⚙️ One sales example across all three
Take a single discovery call. Predictive AI scores the resulting opportunity. Generative AI writes the recap and a draft follow-up. Agentic AI does the whole loop: it transcribes the call, populates the qualification scorecard, enriches the contact, drafts the email, and updates the forecast category, then waits for a human nod on anything revenue-impacting.
This is the layer where Oliv AI operates. Oliv is built as an AI-native data platform on fine-tuned LLMs, with a suite of named agents (Forecaster, Deal Driver, CRM Manager) that perform the work rather than just surface it. When we rebuilt the idea of the CRM internally, the goal was simple: make the system act, not just store. As our CEO Ishan Chhabra puts it, the aim is to make "your CRM fully autonomous."
🔭 Why 2026 is the agentic inflection
I could be slightly early on the timing, but where my head is right now: 2026 is when "agentic" stops being a slide and starts being a buying criterion. Predictive and generative AI were the previous two waves. Both still left a human doing the last mile of clicking, typing, and updating. The agentic wave automates that last mile.
The honest caveat is that autonomy without guardrails scares buyers, and it should. The pattern that actually works is human-in-the-loop: agents handle high-volume, low-risk work like CRM hygiene on their own, while a person stays on the calls that move money. That balance, not the autonomy itself, is what separates a useful agent from a liability. If you are mapping the broader category, our guide to revenue operations to intelligence to orchestration traces how these waves stack.
Q2. What Does Forecast Inaccuracy Actually Cost, and How Do You Calculate the ROI? [toc=2. Cost of Inaccuracy]
Here is the number that should bother every revenue leader: only 7% of sales teams hit forecast accuracy of 90% or more, and the median team lands somewhere between 70% and 79%, according to Gartner. Inaccuracy quietly drains revenue through missed quota and misallocated headcount. The fix is a simple equation: forecast-accuracy lift multiplied by pipeline value equals recovered revenue. On a $50M pipeline, even a 5-point accuracy gain protects $2.5M in better-allocated effort. That is the credibility math agentic forecasting is built to deliver, and it is the case Oliv AI makes to RevOps teams tired of guessing.
Only 7 percent of teams hit 90 percent accuracy, the gap a 5-point lift closes is worth $2.5M on a $50M pipeline.
The hidden cost of a wrong number
A bad forecast is not just an embarrassing board slide. It misroutes everything downstream.
Headcount gets misallocated. You hire against pipeline that was never real.
Deals get under-resourced. The genuinely winnable ones don't get exec air cover because the forecast buried them.
Trust erodes. Once leadership stops believing the number, every review becomes a negotiation instead of a decision.
The root cause is usually data, not effort. Salesforce has reported that the vast majority of CRM data is incomplete or out of date, and forecasts built on that foundation inherit the rot. Garbage in, confident-looking garbage out.
🧮 The accuracy-to-revenue equation
I want to give you something you can actually take to a CFO, not a vibe. Here is the equation, worked. Recovered Revenue equals Pipeline Value multiplied by Forecast-Accuracy Lift.
Say you run a $50M annual pipeline and you move forecast accuracy up 5 points. That is $2.5M of effort, attention, and capital that now lands on the right deals instead of the wrong ones. Industry analysis suggests AI-driven forecasting typically closes the accuracy gap by 10 to 20 percentage points in the first year, with best-in-class teams landing within 5% of actual revenue. Run the same math at a 10-point lift and the number doubles.
📈 The upside is bigger than the savings
The defensive case (stop wasting effort) is only half of it. McKinsey estimates generative AI could add the equivalent of $0.8 trillion to $1.2 trillion in productivity across sales and marketing functions, with sales productivity uplift in the range of 3% to 5% of global sales spend.
I might be wrong on exactly how fast that lands for any single team. But from what surfaces when you actually run agentic forecasting, the productivity gain is real in a boring, specific way: managers stop spending Thursday and Friday on roll-ups. Oliv's Forecaster Agent, for example, inspects every deal line-by-line and delivers a one-page roll-up with risk commentary to manager inboxes every Monday, which is exactly the manual labor the McKinsey numbers assume you'll reclaim. For a head-to-head on legacy roll-ups, see our breakdown of Gong forecasting.
Q3. How Accurate Is Agentic Forecasting? The Method-Tier Benchmark [toc=3. Method-Tier Benchmark]
Forecast accuracy rises with method maturity, not brand name. Gut-feel and manual rep rollups swing wildly; CRM-stage forecasting adds discipline; predictive AI tightens the variance; and agentic forecasting, which continuously scrubs every signal, delivers the tightest, least-biased numbers. The table below lets you locate your team today and see the accuracy lift each upgrade unlocks. This is the benchmark Oliv AI uses to show RevOps leaders where their current method actually sits, and it pairs well with our roundup of the best revenue intelligence software platforms.
The method-tier accuracy benchmark
The single most useful thing I can hand a skeptical VP of Sales is this: forecast accuracy is a function of how you forecast, not which logo you bought. Here is the ladder, with the approximate accuracy band each tier tends to produce.
Forecast method
Typical accuracy band
Main bias source
Effort to run
Data it needs
Gut-feel / rep commit
50 to 65%
Rep optimism, sandbagging
Low (but unreliable)
None structured
Manual rep rollup
60 to 75%
Aggregated rep bias
High (manager hours)
CRM stage fields
CRM-stage weighted
70 to 79% (median)
Stale stage data
Medium
Disciplined stage hygiene
Predictive AI
80 to 88%
Historical-pattern drift
Low after setup
Clean historical data
Agentic (signal-scrubbed)
90%+ (top tier)
Minimal, continuously corrected
Very low (autonomous)
Multi-source live signals
The jump from CRM-stage to predictive is where most teams get their first big lift, and analysis shows AI-driven forecasting typically adds 10 to 20 points of accuracy in year one. The jump from predictive to agentic is subtler but compounding: instead of scoring a snapshot, the system keeps correcting the number as new signals land.
🧭 Why method, not tool, drives the result
The standard read gets this backwards. People shop for a forecasting tool when they should be upgrading their forecasting method. A pretty Clari dashboard fed by stale, rep-entered stage data is still a tier-three forecast wearing a tier-five outfit. Our look at Clari features digs into exactly where that gap shows up.
This shows up plainly in real user reviews. Clari is genuinely strong at presenting a forecast, but operators repeatedly note it inherits whatever the CRM feeds it.
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit, so that is entirely handheld by using the built-in notes field as a calculator." Dexter L., Customer Success Executive Clari G2 Verified Review
"I find the setup process challenging, especially when migrating fields from Salesforce. This requires creating and maintaining duplicate fields, which adds complexity and workload." Josiah R., Head of Sales Operations Clari G2 Verified Review
The pattern is consistent: the visualization is fine, but a human is still hand-feeding the accuracy. Agentic forecasting attacks that root cause. Oliv's Forecaster Agent inspects each deal against signals stitched from calls, emails, and Slack rather than waiting for a rep to update a stage, which is how it pushes toward that top-tier band instead of just charting a mid-tier one.
Q4. Which Agentic Sales Workflows Deliver Value, and What KPI Does Each Move? [toc=4. Agent Workflows & KPIs]
Five agentic workflows carry most of the ROI, and each ties to exactly one KPI: forecast scrub (forecast accuracy %), deal inspection (slipped-deal rate), CRM hygiene (field-completeness %), lead enrichment (qualified-lead conversion %), and renewal-risk detection (gross revenue retention). Instead of dashboards you dig through, named agents run these continuously, scrubbing data, flagging at-risk deals, and updating records autonomously under human review. This is the core of how Oliv AI converts "AI for sales" from a slogan into measurable movement, and it sits at the center of the best AI sales tools conversation.
The trap most teams fall into is buying capability without a target. An agent that "helps with forecasting" is unaccountable. An agent that moves forecast accuracy from 72% to 90% is a budget line you can defend. Here are the five, each pinned to one number.
Five agentic workflows, each pinned to one KPI, the difference between vague capability and defensible budget.
1.1 ⚖️ Forecast scrub → forecast accuracy %
The agent continuously inspects every open deal, line by line, and reconciles the rep's commit against actual signals: email cadence, stakeholder engagement, and call sentiment. It catches the deal a rep "commits" while ignoring that the economic buyer went dark 14 days ago.
Before: a manager spends Thursday and Friday on manual roll-ups, then submits a number nobody fully trusts.
After: an autonomous roll-up lands Monday morning with risk commentary attached.
Oliv's Forecaster Agent does exactly this and, per internal benchmarks, targets roughly 98% forecast accuracy versus the 67% typical of purely rep-driven forecasting. That maps directly to the top accuracy tier from the benchmark above.
1.2 🔍 Deal inspection → slipped-deal rate
Deals rarely die loudly. They go quiet. A deal-inspection agent flags the ones drifting out of motion before they slip a quarter, so intervention happens while it still matters.
"Before Gong we had a lack of visibility across our deals because information was siloed in several places like CRM, Email, Zoom, phone. Now we can measure forecasting accuracy and have confidence in what is going to close and when." Scott T., Director of Sales Gong G2 Verified Review
That visibility is real, but note the limit operators hit with note-taker-first tools.
"For me, the only business problem gong solves is the call recordings. Understanding the pipeline management portion of it is almost impossible." John S., Senior Account Executive Gong G2 Verified Review
Oliv's Deal Driver Agent flags deals needing daily attention and reports that, for example, 68% of stalled Proposal deals had no economic-buyer touch in the last 14 days, turning inspection into a specific, fixable action rather than a screen to scroll. If you are weighing options here, our Gong vs Oliv comparison lays out the difference.
1.3 🧹 CRM hygiene → field-completeness %
This is the unglamorous one that quietly powers everything else. Dirty data sinks forecasts, scoring, and routing alike. A hygiene agent creates contacts, enriches accounts, merges duplicates, and populates methodology fields (MEDDPICC, BANT) straight from conversation context, with no rep typing required. The theory behind those fields is worth a refresher in our MEDDIC sales methodology guide.
"I love I can send off hundreds of emails in bulk. My frustration is with the UI. It feels very clonky and a lot of times groove is frequently saying an issue has occured." Bethany C., Customer Success Manager Clari G2 Verified Review
Manual upkeep is where reps tap out. Oliv's CRM Manager Agent, trained on 100+ sales methodologies, populates up to 100 custom fields from call context, which is how it lifts field-completeness without the late-night data-entry slog.
1.4 🔎 Lead enrichment → qualified-lead conversion %
Cold outreach fails when reps skip prep. An enrichment agent builds the account dossier (buyer pains, decision map, recent triggers) before the first touch, so outreach lands as context-rich instead of generic.
Before: an SDR burns 15 to 20 minutes per account mining LinkedIn and Crunchbase, then sends a templated note.
After: the dossier is ready, the angle is tailored, and reply rates climb.
Oliv's Researcher/Prospector Agent generates these dossiers in minutes by pulling from the web, LinkedIn, and Crunchbase, which moves the needle on qualified-lead conversion rather than raw volume.
This is the workflow most forecast-centric competitors under-serve, and it is pure margin. A renewal-risk agent watches engagement signals across the customer book and surfaces accounts drifting toward churn well before the renewal call.
The signal that matters is silence at the top: a key sponsor who hasn't engaged in 60 days is a leading churn indicator, not a lagging one. Oliv's Retention Forecaster surfaces exactly this, for instance flagging that renewal rates can drop from 94% to 71% when an executive sponsor goes untouched for 60 days, then triggering the play to re-engage. Pairing forecast scrub with renewal-risk is the "lean revenue team" angle: you cover both new-business accuracy and retention without standing up a separate RevOps function for each.
A fair caveat: Oliv's Voice Agent, which calls reps nightly to capture off-the-record renewal and deal updates, is still in alpha, and full custom workflow configuration typically takes two to four weeks. The baseline agents, though, deploy in about 15 minutes, which is why I'd start a lean team on hygiene and forecast scrub first and expand into renewal-risk as trust builds. For the wider category map, our guide to the best revenue orchestration platform tools shows where these workflows fit.
Q5. Why Is Data Quality the Make-or-Break Prerequisite for Agentic AI? [toc=5. Data-Quality Prerequisite]
A RevOps lead at a mid-market SaaS shop told me she turned on a shiny new AI scoring tool and watched it confidently rank a dead account as her hottest deal. The reason was boring: the contact had left the company eight months earlier, and nobody updated the record. That is the whole problem in one scene.
The situation: autonomy amplifies dirty data
Agentic AI is only as good as the data it acts on. Salesforce has reported that the overwhelming majority of CRM records are incomplete or inaccurate, with some studies putting the figure near 90%. With a dashboard, bad data just misleads a human. With an agent, bad data gets acted on automatically.
That is the complication nobody warns you about. An agent updating fields, drafting outreach, and shifting forecast categories on rotten inputs produces autonomous garbage, at scale, faster than any human could. Garbage in, garbage out, but now with a turbo button.
✅ The resolution: a quick data-readiness check
Before you let agents touch anything, run a simple baseline. You do not need a six-month cleanup project first, you need to know where you stand.
Field completeness: What share of open deals have the basics filled, like amount, close date, and next step?
Source coverage: Are calls, emails, and Slack actually connected, or is the CRM your only (thin) signal?
De-duplication: How many duplicate accounts and contacts are quietly splitting your data?
Recency: When was each open opportunity last genuinely touched, not just auto-stamped?
Here is the contrarian part. The standard read says "clean your data, then deploy AI." I think that gets the sequencing backwards for one specific category: hygiene agents. A full manual data clean can be a two-to-three-year slog, while a CRM-hygiene agent cleans as it works. This is the same logic behind our broader take on revenue intelligence platforms.
This is exactly the wedge Oliv AI uses. Our CRM Manager Agent creates contacts, merges duplicates, and populates methodology fields like MEDDPICC straight from conversation context, so the data gets cleaner with every call instead of waiting on a cleanup project. I might be slightly biased here, but from what surfaces when you actually run this, bootstrapping clean data through the agent beats gating the agent behind clean data. If you are weighing alternatives, our roundup of the best AI sales tools shows where hygiene-first agents fit.
Q6. How Do You Roll Out Agentic AI Safely With a Human-in-the-Loop Framework? [toc=6. Human-in-the-Loop Rollout]
By the end of this section, you will have a simple, defensible way to deploy agents without a board member asking why a bot emailed your biggest customer. Safe agentic adoption follows three escalating trust tiers: suggest, approve, and automate. Start agents on high-volume, low-risk work, keep humans on revenue-impacting moves, and widen autonomy as accuracy proves out. That is the framework Oliv AI uses to de-risk rollout, and it complements our guide to Agentforce implementation.
The suggest, approve, automate ladder
Think of agent autonomy like onboarding a new hire. You do not hand a week-one rep the biggest renewal. You earn trust in stages.
Suggest: The agent recommends, a human acts. It flags "this deal looks at risk," and the rep decides. Lowest risk, fastest to trust.
Approve: The agent drafts the action, a human one-clicks. It writes the follow-up or fills the CRM field, you confirm before it commits.
Automate: The agent executes low-risk tasks alone. Things like merging obvious duplicates or logging call notes run without a babysitter.
The point is that autonomy is a dial, not a switch. You move each workflow up the ladder as its accuracy earns the next rung.
The suggest, approve, automate ladder, each workflow climbs a rung only after its accuracy earns the next level of autonomy.
🎯 Sequencing what to automate first
The order matters more than the tooling. Get this wrong and adoption stalls, because one bad autonomous action poisons trust for everything else.
Automate early: CRM hygiene, call logging, and contact enrichment. High volume, low blast radius if wrong.
Keep at approve: Outbound emails, forecast category changes, and stakeholder messaging. Reversible, but customer-facing.
Keep human: The actual sales conversation, pricing calls, and exec relationships. The work only a person should own.
A governance checkpoint helps at each promotion: track the agent's acceptance rate (how often humans accept its suggestions) before moving it up a tier. I could be wrong on the exact thresholds for your team, but the principle holds. Earn the rung, then climb. The MEDDPICC fields these agents populate are worth understanding deeply, which our MEDDIC sales methodology guide covers.
This maps cleanly to how Oliv's agents work in practice. The CRM Manager nudges reps to validate data before pushing updates autonomously, which is "approve" graduating to "automate" as confidence builds. The honest caveat: our Voice Agent, which calls reps nightly for deal updates, is still in alpha, so I would keep that one firmly in the suggest tier for now. For teams comparing setup paths, our Gong implementation timeline breakdown is a useful reference point.
Q7. How Do You Evaluate Vendors? The Agentic Sales AI Buying-Criteria Matrix [toc=7. Buying-Criteria Matrix]
The best way to choose an agentic sales platform is to score every vendor on four axes: forecast-accuracy lift, conversation-intelligence depth, agentic execution, and CRM-native fit. The matrix below turns a noisy, overcrowded market into a like-for-like comparison. It is also the lens Oliv AI is happy to be measured against, because it rewards action over dashboards. For a deeper field scan, see our list of the best revenue intelligence software platforms.
The four axes that actually matter
Most "best AI sales tool" lists compare feature counts. That is noise. These four criteria predict whether the thing will move revenue.
Forecast-accuracy lift: Does it measurably tighten your forecast, or just visualize the same shaky number prettier?
Conversation-intelligence depth: Does it read calls, emails, and tickets, or only record calls?
Agentic execution: Does it take action, or does it stop at "here's a report, good luck"?
CRM-native fit: Does it sync both ways without locking your data in?
The trap is buying a strong tool on the wrong axis. A team needing forecast accuracy should not over-index on a category leader that is, at its core, a call recorder. Our Gong vs Clari comparison shows how easily teams pick the wrong axis.
📊 Scoring the field
Here is a vendor-neutral read, grounded in what operators actually report. Weight the axes by your own constraint: forecast-led teams weight the first column, prospecting-led teams the second.
Platform
Forecast-accuracy lift
Conversation depth
Agentic execution
CRM-native fit
Clari
Strong (forecast-first)
Moderate (Copilot)
Low (reports, not actions)
Good, but a "glorified SFDC overlay" per users
Gong
Moderate (add-on)
Strong (calls)
Low (note-taker core)
Limited bulk export
Outreach
Low
Low (sequencing)
Low
Sync breaks reported
Salesforce Agentforce
Moderate
Moderate
Emerging (config-heavy)
Native, but setup-heavy
Oliv AI
Strong (98% target)
Strong (calls, email, Slack)
High (named agents act)
Bi-directional, full open export
The red flags worth screening for show up loudly in reviews.
"It is really just a glorified SFDC overlay. Definitely overkill for most companies." conaldinho11, r/SalesOperations Reddit Thread
"The price of Agentforce is not clear and hard to find. Adoption is low. Customers are finding issues in deploying and using agents in Salesforce." Anusha T., Web Developer Salesforce Agentforce G2 Verified Review
"The engage product is stagnant. Looks to have the same features, UX, integrations and issues as it had 5 years ago." Matthew T., Head of Revenue Operations Outreach G2 Verified Review
Where Oliv scores well is the agentic-execution column most others leave empty: named agents that act, plus a full open export policy so your data is never hostage. Score honestly, and the gaps pick the winner for you. For a direct head-to-head, our Gong vs Oliv breakdown applies this same matrix.
Q8. Which Teams Benefit Most, and Why Lean SaaS Teams Win With Agentic AI? [toc=8. Best-Fit Teams]
The short answer: lean SaaS teams gain the most, because they have no large RevOps function to manually scrub forecasts or chase CRM hygiene. Agents replace headcount they cannot justify hiring. High-velocity B2B teams, fast-scaling startups, and renewal-heavy subscription businesses all see outsized returns. Oliv AI is built squarely for that lean, fast-moving profile, which we explore further in our guide to the best AI sales forecasting software.
Why lean teams get the biggest lift
A 200-person enterprise can throw five RevOps analysts at dirty data. A 30-rep scale-up cannot. For the lean team, an agent is not a nice-to-have, it is the RevOps hire they will not make.
The math is simple. When one ops person supports 25 reps, every hour the agent saves on hygiene, roll-ups, and prep is an hour that does not need a new salary behind it. Automation becomes a force-multiplier exactly where the budget is tightest.
🎯 If you are X, here is the fit
Match your situation to the call, including the honest "not for you" cases.
High-velocity B2B SaaS, 15 to 20 day cycles, drowning in dirty data: strong fit. Pipeline moves too fast for manual roll-ups.
Seed or Series A startup with 5 to 25 reps, no RevOps team: strong fit. Build the motion right from day one.
Renewal-heavy subscription business: strong fit. Renewal-risk detection protects retention without a dedicated CS-ops team.
❌ Pure B2C support automation: not the best fit. Look at a service-first agent platform instead.
❌ Teams wanting only basic call recording: overkill. A simple recorder is cheaper.
The operator pain that makes the case is everywhere in reviews of legacy stacks.
"It was a big mistake on our part to commit to a two year term. We are stuck with a tool that works technically but isnt the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"Once we started scaling to more users and use cases, the cost ramped up pretty quickly. We had to rethink a few workflows just to stay within budget." Reviewer, Salesforce Agentforce Salesforce Agentforce G2 Verified Review
That is the lean-team trap: paying enterprise prices for adoption you cannot fund. Oliv's modular, pay-for-what-you-use pricing (agents like the CRM Manager available individually, with no mandatory platform fee on many tiers) is designed so a 25-rep team gets agentic coverage without the $500-per-user stacked bill. If you are that team, this is the angle the bigger vendors quietly under-serve, as our roundup of the best Agentforce alternatives and competitors details.
Q9. How Do You Measure Success and Govern Agentic AI Over Time? [toc=9. Measurement & Governance]
A VP of Sales once asked me, "We turned the agents on. Now how do I know they're still working in six months?" That question is the whole game. Most teams measure agentic AI once, at the ROI pitch, then never check the dials again. Post-launch, you track the same KPIs each workflow targets, like forecast accuracy, gross revenue retention (GRR), and field completeness, plus agent-specific health metrics like action-acceptance rate and override frequency. Then you govern with periodic accuracy audits, drift monitoring, and clear ownership so autonomy stays accountable. Measurement is not a one-time ROI check, it is the control loop that lets you safely expand what the agents do. This is the discipline Oliv AI builds into its deployments rather than bolting on later, and it underpins our view of the best revenue intelligence software platforms.
The two layers of metrics you actually need
Here is the mistake I see constantly: teams track outcome KPIs and ignore agent-health KPIs. You need both, because one tells you if it's working and the other tells you why.
Outcome KPIs (the result): forecast accuracy %, gross revenue retention (the share of recurring revenue you keep), field-completeness %, and slipped-deal rate. These prove revenue impact.
Agent-health KPIs (the engine): action-acceptance rate (how often humans accept the agent's suggestions), override frequency (how often they reject it), and time-to-action. These predict trust.
The signal I watch most is override frequency. If reps suddenly start rejecting an agent's CRM updates, something drifted, and the outcome KPI hasn't caught up yet. Acceptance rate is your early-warning system, not a vanity stat. For teams refining the forecast number specifically, our guide to the best AI sales forecasting software goes deeper.
⏰ Governance is a cadence, not a launch event
Drift is the quiet killer. Your data changes, your sales motion changes, and an agent tuned for last quarter slowly gets things wrong. "Drift" just means the model's accuracy decaying as reality shifts underneath it.
A simple governance cadence keeps autonomy honest.
Monthly: review acceptance and override rates per agent. Flag any agent trending down.
Quarterly: run an accuracy audit. Sample agent actions and grade them against ground truth.
Always: assign one named owner per agent. Unowned automation is how you get a bot emailing a churned customer.
The contrarian point here: the standard read treats governance as a brake on autonomy. I think it is the opposite. Tight measurement is what earns you the right to expand autonomy, because each clean audit lets you promote another workflow from "approve" to "automate" with evidence, not hope. The same accountability logic shapes our take on revenue operations to intelligence to orchestration.
This is exactly why our agents are built to nudge reps to validate data before pushing updates, which generates the acceptance-rate signal automatically. When we run our own forecast reviews on Oliv agents, that override data is the dashboard we watch, not a buried log. I could be wrong on the perfect audit frequency for every team, but from what surfaces when you actually run this, the teams that audit quarterly expand autonomy roughly twice as fast as the ones that "set and forget." If you are benchmarking against legacy roll-ups, our breakdown of Gong forecasting is a useful comparison.
🔭 Where I think this goes next
Where my head is right now: the next two years quietly flip the model. The SaaS you log into becomes agents that work for you, and revenue orchestration gives way to revenue engineering. The open question I keep sitting with is governance itself. When agents start auditing other agents, who owns the override?
I don't have a clean answer yet, and I'd genuinely rather trade notes than pretend I do. If you're running agents in production and watching your own acceptance rates move, I want to hear what your dials are telling you. For the wider category shift, our guide to the best revenue orchestration platform tools maps where this is heading.
Q1. What Is Agentic AI for Sales, and How Does It Differ From Predictive and Generative AI? [toc=1. Agentic AI Defined]
A RevOps lead at a 60-rep SaaS company once showed me her Monday ritual: three dashboards open, a forecast spreadsheet she didn't trust, and a coffee going cold. The tools could tell her things. None of them could do anything. That gap, between knowing and acting, is exactly what agentic AI for sales closes. Agentic AI is software that doesn't just predict or draft, it acts. The capability model has three tiers: predictive AI scores deals and forecasts outcomes, generative AI writes the email or summary, and agentic AI autonomously inspects a deal, updates the CRM, and triggers next steps under human oversight. It is the shift from a dashboard you read to a teammate that executes.
The three-tier capability model
Most "AI for sales" pitches blur three very different things. Pulling them apart is the fastest way to cut through vendor noise.
Predictive AI scores and forecasts. It looks at historical patterns and says "this deal has a 40% chance to close." It informs. It does not move.
Generative AI creates. It drafts the follow-up email, the call summary, the account brief. It produces output, but a human still has to act on it.
Agentic AI executes. It chains steps together: read the call, update the MEDDPICC fields, draft the follow-up, flag the slipping deal, and route it to the right rep, with you approving where it matters.
Here is the simplest way I explain it to operators. Predictive AI is a weather report. Generative AI writes you a packing list. Agentic AI actually packs the bag and books the cab.
The capability ladder from predictive to agentic AI, the shift from reading a dashboard to a teammate that executes.
⚙️ One sales example across all three
Take a single discovery call. Predictive AI scores the resulting opportunity. Generative AI writes the recap and a draft follow-up. Agentic AI does the whole loop: it transcribes the call, populates the qualification scorecard, enriches the contact, drafts the email, and updates the forecast category, then waits for a human nod on anything revenue-impacting.
This is the layer where Oliv AI operates. Oliv is built as an AI-native data platform on fine-tuned LLMs, with a suite of named agents (Forecaster, Deal Driver, CRM Manager) that perform the work rather than just surface it. When we rebuilt the idea of the CRM internally, the goal was simple: make the system act, not just store. As our CEO Ishan Chhabra puts it, the aim is to make "your CRM fully autonomous."
🔭 Why 2026 is the agentic inflection
I could be slightly early on the timing, but where my head is right now: 2026 is when "agentic" stops being a slide and starts being a buying criterion. Predictive and generative AI were the previous two waves. Both still left a human doing the last mile of clicking, typing, and updating. The agentic wave automates that last mile.
The honest caveat is that autonomy without guardrails scares buyers, and it should. The pattern that actually works is human-in-the-loop: agents handle high-volume, low-risk work like CRM hygiene on their own, while a person stays on the calls that move money. That balance, not the autonomy itself, is what separates a useful agent from a liability. If you are mapping the broader category, our guide to revenue operations to intelligence to orchestration traces how these waves stack.
Q2. What Does Forecast Inaccuracy Actually Cost, and How Do You Calculate the ROI? [toc=2. Cost of Inaccuracy]
Here is the number that should bother every revenue leader: only 7% of sales teams hit forecast accuracy of 90% or more, and the median team lands somewhere between 70% and 79%, according to Gartner. Inaccuracy quietly drains revenue through missed quota and misallocated headcount. The fix is a simple equation: forecast-accuracy lift multiplied by pipeline value equals recovered revenue. On a $50M pipeline, even a 5-point accuracy gain protects $2.5M in better-allocated effort. That is the credibility math agentic forecasting is built to deliver, and it is the case Oliv AI makes to RevOps teams tired of guessing.
Only 7 percent of teams hit 90 percent accuracy, the gap a 5-point lift closes is worth $2.5M on a $50M pipeline.
The hidden cost of a wrong number
A bad forecast is not just an embarrassing board slide. It misroutes everything downstream.
Headcount gets misallocated. You hire against pipeline that was never real.
Deals get under-resourced. The genuinely winnable ones don't get exec air cover because the forecast buried them.
Trust erodes. Once leadership stops believing the number, every review becomes a negotiation instead of a decision.
The root cause is usually data, not effort. Salesforce has reported that the vast majority of CRM data is incomplete or out of date, and forecasts built on that foundation inherit the rot. Garbage in, confident-looking garbage out.
🧮 The accuracy-to-revenue equation
I want to give you something you can actually take to a CFO, not a vibe. Here is the equation, worked. Recovered Revenue equals Pipeline Value multiplied by Forecast-Accuracy Lift.
Say you run a $50M annual pipeline and you move forecast accuracy up 5 points. That is $2.5M of effort, attention, and capital that now lands on the right deals instead of the wrong ones. Industry analysis suggests AI-driven forecasting typically closes the accuracy gap by 10 to 20 percentage points in the first year, with best-in-class teams landing within 5% of actual revenue. Run the same math at a 10-point lift and the number doubles.
📈 The upside is bigger than the savings
The defensive case (stop wasting effort) is only half of it. McKinsey estimates generative AI could add the equivalent of $0.8 trillion to $1.2 trillion in productivity across sales and marketing functions, with sales productivity uplift in the range of 3% to 5% of global sales spend.
I might be wrong on exactly how fast that lands for any single team. But from what surfaces when you actually run agentic forecasting, the productivity gain is real in a boring, specific way: managers stop spending Thursday and Friday on roll-ups. Oliv's Forecaster Agent, for example, inspects every deal line-by-line and delivers a one-page roll-up with risk commentary to manager inboxes every Monday, which is exactly the manual labor the McKinsey numbers assume you'll reclaim. For a head-to-head on legacy roll-ups, see our breakdown of Gong forecasting.
Q3. How Accurate Is Agentic Forecasting? The Method-Tier Benchmark [toc=3. Method-Tier Benchmark]
Forecast accuracy rises with method maturity, not brand name. Gut-feel and manual rep rollups swing wildly; CRM-stage forecasting adds discipline; predictive AI tightens the variance; and agentic forecasting, which continuously scrubs every signal, delivers the tightest, least-biased numbers. The table below lets you locate your team today and see the accuracy lift each upgrade unlocks. This is the benchmark Oliv AI uses to show RevOps leaders where their current method actually sits, and it pairs well with our roundup of the best revenue intelligence software platforms.
The method-tier accuracy benchmark
The single most useful thing I can hand a skeptical VP of Sales is this: forecast accuracy is a function of how you forecast, not which logo you bought. Here is the ladder, with the approximate accuracy band each tier tends to produce.
Forecast method
Typical accuracy band
Main bias source
Effort to run
Data it needs
Gut-feel / rep commit
50 to 65%
Rep optimism, sandbagging
Low (but unreliable)
None structured
Manual rep rollup
60 to 75%
Aggregated rep bias
High (manager hours)
CRM stage fields
CRM-stage weighted
70 to 79% (median)
Stale stage data
Medium
Disciplined stage hygiene
Predictive AI
80 to 88%
Historical-pattern drift
Low after setup
Clean historical data
Agentic (signal-scrubbed)
90%+ (top tier)
Minimal, continuously corrected
Very low (autonomous)
Multi-source live signals
The jump from CRM-stage to predictive is where most teams get their first big lift, and analysis shows AI-driven forecasting typically adds 10 to 20 points of accuracy in year one. The jump from predictive to agentic is subtler but compounding: instead of scoring a snapshot, the system keeps correcting the number as new signals land.
🧭 Why method, not tool, drives the result
The standard read gets this backwards. People shop for a forecasting tool when they should be upgrading their forecasting method. A pretty Clari dashboard fed by stale, rep-entered stage data is still a tier-three forecast wearing a tier-five outfit. Our look at Clari features digs into exactly where that gap shows up.
This shows up plainly in real user reviews. Clari is genuinely strong at presenting a forecast, but operators repeatedly note it inherits whatever the CRM feeds it.
"I do think the forecasting feature is decent, but at least in our setup, it doesn't do a great job of auto-calculating the values I need to submit, so that is entirely handheld by using the built-in notes field as a calculator." Dexter L., Customer Success Executive Clari G2 Verified Review
"I find the setup process challenging, especially when migrating fields from Salesforce. This requires creating and maintaining duplicate fields, which adds complexity and workload." Josiah R., Head of Sales Operations Clari G2 Verified Review
The pattern is consistent: the visualization is fine, but a human is still hand-feeding the accuracy. Agentic forecasting attacks that root cause. Oliv's Forecaster Agent inspects each deal against signals stitched from calls, emails, and Slack rather than waiting for a rep to update a stage, which is how it pushes toward that top-tier band instead of just charting a mid-tier one.
Q4. Which Agentic Sales Workflows Deliver Value, and What KPI Does Each Move? [toc=4. Agent Workflows & KPIs]
Five agentic workflows carry most of the ROI, and each ties to exactly one KPI: forecast scrub (forecast accuracy %), deal inspection (slipped-deal rate), CRM hygiene (field-completeness %), lead enrichment (qualified-lead conversion %), and renewal-risk detection (gross revenue retention). Instead of dashboards you dig through, named agents run these continuously, scrubbing data, flagging at-risk deals, and updating records autonomously under human review. This is the core of how Oliv AI converts "AI for sales" from a slogan into measurable movement, and it sits at the center of the best AI sales tools conversation.
The trap most teams fall into is buying capability without a target. An agent that "helps with forecasting" is unaccountable. An agent that moves forecast accuracy from 72% to 90% is a budget line you can defend. Here are the five, each pinned to one number.
Five agentic workflows, each pinned to one KPI, the difference between vague capability and defensible budget.
1.1 ⚖️ Forecast scrub → forecast accuracy %
The agent continuously inspects every open deal, line by line, and reconciles the rep's commit against actual signals: email cadence, stakeholder engagement, and call sentiment. It catches the deal a rep "commits" while ignoring that the economic buyer went dark 14 days ago.
Before: a manager spends Thursday and Friday on manual roll-ups, then submits a number nobody fully trusts.
After: an autonomous roll-up lands Monday morning with risk commentary attached.
Oliv's Forecaster Agent does exactly this and, per internal benchmarks, targets roughly 98% forecast accuracy versus the 67% typical of purely rep-driven forecasting. That maps directly to the top accuracy tier from the benchmark above.
1.2 🔍 Deal inspection → slipped-deal rate
Deals rarely die loudly. They go quiet. A deal-inspection agent flags the ones drifting out of motion before they slip a quarter, so intervention happens while it still matters.
"Before Gong we had a lack of visibility across our deals because information was siloed in several places like CRM, Email, Zoom, phone. Now we can measure forecasting accuracy and have confidence in what is going to close and when." Scott T., Director of Sales Gong G2 Verified Review
That visibility is real, but note the limit operators hit with note-taker-first tools.
"For me, the only business problem gong solves is the call recordings. Understanding the pipeline management portion of it is almost impossible." John S., Senior Account Executive Gong G2 Verified Review
Oliv's Deal Driver Agent flags deals needing daily attention and reports that, for example, 68% of stalled Proposal deals had no economic-buyer touch in the last 14 days, turning inspection into a specific, fixable action rather than a screen to scroll. If you are weighing options here, our Gong vs Oliv comparison lays out the difference.
1.3 🧹 CRM hygiene → field-completeness %
This is the unglamorous one that quietly powers everything else. Dirty data sinks forecasts, scoring, and routing alike. A hygiene agent creates contacts, enriches accounts, merges duplicates, and populates methodology fields (MEDDPICC, BANT) straight from conversation context, with no rep typing required. The theory behind those fields is worth a refresher in our MEDDIC sales methodology guide.
"I love I can send off hundreds of emails in bulk. My frustration is with the UI. It feels very clonky and a lot of times groove is frequently saying an issue has occured." Bethany C., Customer Success Manager Clari G2 Verified Review
Manual upkeep is where reps tap out. Oliv's CRM Manager Agent, trained on 100+ sales methodologies, populates up to 100 custom fields from call context, which is how it lifts field-completeness without the late-night data-entry slog.
1.4 🔎 Lead enrichment → qualified-lead conversion %
Cold outreach fails when reps skip prep. An enrichment agent builds the account dossier (buyer pains, decision map, recent triggers) before the first touch, so outreach lands as context-rich instead of generic.
Before: an SDR burns 15 to 20 minutes per account mining LinkedIn and Crunchbase, then sends a templated note.
After: the dossier is ready, the angle is tailored, and reply rates climb.
Oliv's Researcher/Prospector Agent generates these dossiers in minutes by pulling from the web, LinkedIn, and Crunchbase, which moves the needle on qualified-lead conversion rather than raw volume.
This is the workflow most forecast-centric competitors under-serve, and it is pure margin. A renewal-risk agent watches engagement signals across the customer book and surfaces accounts drifting toward churn well before the renewal call.
The signal that matters is silence at the top: a key sponsor who hasn't engaged in 60 days is a leading churn indicator, not a lagging one. Oliv's Retention Forecaster surfaces exactly this, for instance flagging that renewal rates can drop from 94% to 71% when an executive sponsor goes untouched for 60 days, then triggering the play to re-engage. Pairing forecast scrub with renewal-risk is the "lean revenue team" angle: you cover both new-business accuracy and retention without standing up a separate RevOps function for each.
A fair caveat: Oliv's Voice Agent, which calls reps nightly to capture off-the-record renewal and deal updates, is still in alpha, and full custom workflow configuration typically takes two to four weeks. The baseline agents, though, deploy in about 15 minutes, which is why I'd start a lean team on hygiene and forecast scrub first and expand into renewal-risk as trust builds. For the wider category map, our guide to the best revenue orchestration platform tools shows where these workflows fit.
Q5. Why Is Data Quality the Make-or-Break Prerequisite for Agentic AI? [toc=5. Data-Quality Prerequisite]
A RevOps lead at a mid-market SaaS shop told me she turned on a shiny new AI scoring tool and watched it confidently rank a dead account as her hottest deal. The reason was boring: the contact had left the company eight months earlier, and nobody updated the record. That is the whole problem in one scene.
The situation: autonomy amplifies dirty data
Agentic AI is only as good as the data it acts on. Salesforce has reported that the overwhelming majority of CRM records are incomplete or inaccurate, with some studies putting the figure near 90%. With a dashboard, bad data just misleads a human. With an agent, bad data gets acted on automatically.
That is the complication nobody warns you about. An agent updating fields, drafting outreach, and shifting forecast categories on rotten inputs produces autonomous garbage, at scale, faster than any human could. Garbage in, garbage out, but now with a turbo button.
✅ The resolution: a quick data-readiness check
Before you let agents touch anything, run a simple baseline. You do not need a six-month cleanup project first, you need to know where you stand.
Field completeness: What share of open deals have the basics filled, like amount, close date, and next step?
Source coverage: Are calls, emails, and Slack actually connected, or is the CRM your only (thin) signal?
De-duplication: How many duplicate accounts and contacts are quietly splitting your data?
Recency: When was each open opportunity last genuinely touched, not just auto-stamped?
Here is the contrarian part. The standard read says "clean your data, then deploy AI." I think that gets the sequencing backwards for one specific category: hygiene agents. A full manual data clean can be a two-to-three-year slog, while a CRM-hygiene agent cleans as it works. This is the same logic behind our broader take on revenue intelligence platforms.
This is exactly the wedge Oliv AI uses. Our CRM Manager Agent creates contacts, merges duplicates, and populates methodology fields like MEDDPICC straight from conversation context, so the data gets cleaner with every call instead of waiting on a cleanup project. I might be slightly biased here, but from what surfaces when you actually run this, bootstrapping clean data through the agent beats gating the agent behind clean data. If you are weighing alternatives, our roundup of the best AI sales tools shows where hygiene-first agents fit.
Q6. How Do You Roll Out Agentic AI Safely With a Human-in-the-Loop Framework? [toc=6. Human-in-the-Loop Rollout]
By the end of this section, you will have a simple, defensible way to deploy agents without a board member asking why a bot emailed your biggest customer. Safe agentic adoption follows three escalating trust tiers: suggest, approve, and automate. Start agents on high-volume, low-risk work, keep humans on revenue-impacting moves, and widen autonomy as accuracy proves out. That is the framework Oliv AI uses to de-risk rollout, and it complements our guide to Agentforce implementation.
The suggest, approve, automate ladder
Think of agent autonomy like onboarding a new hire. You do not hand a week-one rep the biggest renewal. You earn trust in stages.
Suggest: The agent recommends, a human acts. It flags "this deal looks at risk," and the rep decides. Lowest risk, fastest to trust.
Approve: The agent drafts the action, a human one-clicks. It writes the follow-up or fills the CRM field, you confirm before it commits.
Automate: The agent executes low-risk tasks alone. Things like merging obvious duplicates or logging call notes run without a babysitter.
The point is that autonomy is a dial, not a switch. You move each workflow up the ladder as its accuracy earns the next rung.
The suggest, approve, automate ladder, each workflow climbs a rung only after its accuracy earns the next level of autonomy.
🎯 Sequencing what to automate first
The order matters more than the tooling. Get this wrong and adoption stalls, because one bad autonomous action poisons trust for everything else.
Automate early: CRM hygiene, call logging, and contact enrichment. High volume, low blast radius if wrong.
Keep at approve: Outbound emails, forecast category changes, and stakeholder messaging. Reversible, but customer-facing.
Keep human: The actual sales conversation, pricing calls, and exec relationships. The work only a person should own.
A governance checkpoint helps at each promotion: track the agent's acceptance rate (how often humans accept its suggestions) before moving it up a tier. I could be wrong on the exact thresholds for your team, but the principle holds. Earn the rung, then climb. The MEDDPICC fields these agents populate are worth understanding deeply, which our MEDDIC sales methodology guide covers.
This maps cleanly to how Oliv's agents work in practice. The CRM Manager nudges reps to validate data before pushing updates autonomously, which is "approve" graduating to "automate" as confidence builds. The honest caveat: our Voice Agent, which calls reps nightly for deal updates, is still in alpha, so I would keep that one firmly in the suggest tier for now. For teams comparing setup paths, our Gong implementation timeline breakdown is a useful reference point.
Q7. How Do You Evaluate Vendors? The Agentic Sales AI Buying-Criteria Matrix [toc=7. Buying-Criteria Matrix]
The best way to choose an agentic sales platform is to score every vendor on four axes: forecast-accuracy lift, conversation-intelligence depth, agentic execution, and CRM-native fit. The matrix below turns a noisy, overcrowded market into a like-for-like comparison. It is also the lens Oliv AI is happy to be measured against, because it rewards action over dashboards. For a deeper field scan, see our list of the best revenue intelligence software platforms.
The four axes that actually matter
Most "best AI sales tool" lists compare feature counts. That is noise. These four criteria predict whether the thing will move revenue.
Forecast-accuracy lift: Does it measurably tighten your forecast, or just visualize the same shaky number prettier?
Conversation-intelligence depth: Does it read calls, emails, and tickets, or only record calls?
Agentic execution: Does it take action, or does it stop at "here's a report, good luck"?
CRM-native fit: Does it sync both ways without locking your data in?
The trap is buying a strong tool on the wrong axis. A team needing forecast accuracy should not over-index on a category leader that is, at its core, a call recorder. Our Gong vs Clari comparison shows how easily teams pick the wrong axis.
📊 Scoring the field
Here is a vendor-neutral read, grounded in what operators actually report. Weight the axes by your own constraint: forecast-led teams weight the first column, prospecting-led teams the second.
Platform
Forecast-accuracy lift
Conversation depth
Agentic execution
CRM-native fit
Clari
Strong (forecast-first)
Moderate (Copilot)
Low (reports, not actions)
Good, but a "glorified SFDC overlay" per users
Gong
Moderate (add-on)
Strong (calls)
Low (note-taker core)
Limited bulk export
Outreach
Low
Low (sequencing)
Low
Sync breaks reported
Salesforce Agentforce
Moderate
Moderate
Emerging (config-heavy)
Native, but setup-heavy
Oliv AI
Strong (98% target)
Strong (calls, email, Slack)
High (named agents act)
Bi-directional, full open export
The red flags worth screening for show up loudly in reviews.
"It is really just a glorified SFDC overlay. Definitely overkill for most companies." conaldinho11, r/SalesOperations Reddit Thread
"The price of Agentforce is not clear and hard to find. Adoption is low. Customers are finding issues in deploying and using agents in Salesforce." Anusha T., Web Developer Salesforce Agentforce G2 Verified Review
"The engage product is stagnant. Looks to have the same features, UX, integrations and issues as it had 5 years ago." Matthew T., Head of Revenue Operations Outreach G2 Verified Review
Where Oliv scores well is the agentic-execution column most others leave empty: named agents that act, plus a full open export policy so your data is never hostage. Score honestly, and the gaps pick the winner for you. For a direct head-to-head, our Gong vs Oliv breakdown applies this same matrix.
Q8. Which Teams Benefit Most, and Why Lean SaaS Teams Win With Agentic AI? [toc=8. Best-Fit Teams]
The short answer: lean SaaS teams gain the most, because they have no large RevOps function to manually scrub forecasts or chase CRM hygiene. Agents replace headcount they cannot justify hiring. High-velocity B2B teams, fast-scaling startups, and renewal-heavy subscription businesses all see outsized returns. Oliv AI is built squarely for that lean, fast-moving profile, which we explore further in our guide to the best AI sales forecasting software.
Why lean teams get the biggest lift
A 200-person enterprise can throw five RevOps analysts at dirty data. A 30-rep scale-up cannot. For the lean team, an agent is not a nice-to-have, it is the RevOps hire they will not make.
The math is simple. When one ops person supports 25 reps, every hour the agent saves on hygiene, roll-ups, and prep is an hour that does not need a new salary behind it. Automation becomes a force-multiplier exactly where the budget is tightest.
🎯 If you are X, here is the fit
Match your situation to the call, including the honest "not for you" cases.
High-velocity B2B SaaS, 15 to 20 day cycles, drowning in dirty data: strong fit. Pipeline moves too fast for manual roll-ups.
Seed or Series A startup with 5 to 25 reps, no RevOps team: strong fit. Build the motion right from day one.
Renewal-heavy subscription business: strong fit. Renewal-risk detection protects retention without a dedicated CS-ops team.
❌ Pure B2C support automation: not the best fit. Look at a service-first agent platform instead.
❌ Teams wanting only basic call recording: overkill. A simple recorder is cheaper.
The operator pain that makes the case is everywhere in reviews of legacy stacks.
"It was a big mistake on our part to commit to a two year term. We are stuck with a tool that works technically but isnt the right business decision." Iris P., Head of Marketing and Sales Partnerships Gong G2 Verified Review
"Once we started scaling to more users and use cases, the cost ramped up pretty quickly. We had to rethink a few workflows just to stay within budget." Reviewer, Salesforce Agentforce Salesforce Agentforce G2 Verified Review
That is the lean-team trap: paying enterprise prices for adoption you cannot fund. Oliv's modular, pay-for-what-you-use pricing (agents like the CRM Manager available individually, with no mandatory platform fee on many tiers) is designed so a 25-rep team gets agentic coverage without the $500-per-user stacked bill. If you are that team, this is the angle the bigger vendors quietly under-serve, as our roundup of the best Agentforce alternatives and competitors details.
Q9. How Do You Measure Success and Govern Agentic AI Over Time? [toc=9. Measurement & Governance]
A VP of Sales once asked me, "We turned the agents on. Now how do I know they're still working in six months?" That question is the whole game. Most teams measure agentic AI once, at the ROI pitch, then never check the dials again. Post-launch, you track the same KPIs each workflow targets, like forecast accuracy, gross revenue retention (GRR), and field completeness, plus agent-specific health metrics like action-acceptance rate and override frequency. Then you govern with periodic accuracy audits, drift monitoring, and clear ownership so autonomy stays accountable. Measurement is not a one-time ROI check, it is the control loop that lets you safely expand what the agents do. This is the discipline Oliv AI builds into its deployments rather than bolting on later, and it underpins our view of the best revenue intelligence software platforms.
The two layers of metrics you actually need
Here is the mistake I see constantly: teams track outcome KPIs and ignore agent-health KPIs. You need both, because one tells you if it's working and the other tells you why.
Outcome KPIs (the result): forecast accuracy %, gross revenue retention (the share of recurring revenue you keep), field-completeness %, and slipped-deal rate. These prove revenue impact.
Agent-health KPIs (the engine): action-acceptance rate (how often humans accept the agent's suggestions), override frequency (how often they reject it), and time-to-action. These predict trust.
The signal I watch most is override frequency. If reps suddenly start rejecting an agent's CRM updates, something drifted, and the outcome KPI hasn't caught up yet. Acceptance rate is your early-warning system, not a vanity stat. For teams refining the forecast number specifically, our guide to the best AI sales forecasting software goes deeper.
⏰ Governance is a cadence, not a launch event
Drift is the quiet killer. Your data changes, your sales motion changes, and an agent tuned for last quarter slowly gets things wrong. "Drift" just means the model's accuracy decaying as reality shifts underneath it.
A simple governance cadence keeps autonomy honest.
Monthly: review acceptance and override rates per agent. Flag any agent trending down.
Quarterly: run an accuracy audit. Sample agent actions and grade them against ground truth.
Always: assign one named owner per agent. Unowned automation is how you get a bot emailing a churned customer.
The contrarian point here: the standard read treats governance as a brake on autonomy. I think it is the opposite. Tight measurement is what earns you the right to expand autonomy, because each clean audit lets you promote another workflow from "approve" to "automate" with evidence, not hope. The same accountability logic shapes our take on revenue operations to intelligence to orchestration.
This is exactly why our agents are built to nudge reps to validate data before pushing updates, which generates the acceptance-rate signal automatically. When we run our own forecast reviews on Oliv agents, that override data is the dashboard we watch, not a buried log. I could be wrong on the perfect audit frequency for every team, but from what surfaces when you actually run this, the teams that audit quarterly expand autonomy roughly twice as fast as the ones that "set and forget." If you are benchmarking against legacy roll-ups, our breakdown of Gong forecasting is a useful comparison.
🔭 Where I think this goes next
Where my head is right now: the next two years quietly flip the model. The SaaS you log into becomes agents that work for you, and revenue orchestration gives way to revenue engineering. The open question I keep sitting with is governance itself. When agents start auditing other agents, who owns the override?
I don't have a clean answer yet, and I'd genuinely rather trade notes than pretend I do. If you're running agents in production and watching your own acceptance rates move, I want to hear what your dials are telling you. For the wider category shift, our guide to the best revenue orchestration platform tools maps where this is heading.
FAQ's
What is AI for revenue operations, and how is it different from predictive or generative AI?
AI for revenue operations is software that acts, not just software that reports. We think the cleanest way to see it is a three-tier model.
Predictive AI scores deals and forecasts outcomes. It informs, but it does not move.
Generative AI drafts the email, summary, or account brief. A human still has to act on the output.
Agentic AI executes a full loop: it reads the call, updates the CRM, drafts the follow-up, and flags the slipping deal, with you approving anything revenue-impacting.
Take one discovery call. Predictive AI scores the opportunity, generative AI writes the recap, and agentic AI does the whole sequence autonomously under review. That last mile, the clicking and typing nobody wants, is what agentic AI removes.
This is the layer we built Oliv around, with named agents that perform the work instead of just surfacing it. If you want the broader category map, our guide to revenue operations, intelligence, and orchestration traces how these three waves stack and why 2026 is the agentic inflection point.
What does forecast inaccuracy actually cost, and how do we calculate the ROI of AI for RevOps?
The cost is bigger than an awkward board slide. Only about 7% of sales teams hit forecast accuracy of 90% or more, and the median team lands between 70% and 79%. Inaccuracy quietly misroutes everything downstream.
Headcount gets hired against pipeline that was never real.
Winnable deals get under-resourced because the forecast buried them.
Trust erodes until every review becomes a negotiation.
The ROI math is simple enough to take to a CFO. Recovered Revenue equals Pipeline Value multiplied by Forecast-Accuracy Lift. On a $50M pipeline, even a 5-point gain protects $2.5M of effort and attention. AI-driven forecasting typically closes the gap by 10 to 20 points in the first year.
We designed our Forecaster Agent to inspect every deal line by line and deliver a Monday roll-up with risk commentary, which is exactly the manual labor you reclaim. For a deeper benchmark, see our breakdown of the best AI sales forecasting software and how method maturity drives accuracy.
Which AI revenue operations workflows deliver the most value, and what KPI does each one move?
In our experience, five workflows carry most of the return, and each ties cleanly to a single KPI. That one-to-one mapping is what makes the spend defensible.
Forecast scrub reconciles rep commits against real signals, moving forecast accuracy %.
Deal inspection flags deals drifting out of motion, moving slipped-deal rate.
CRM hygiene populates fields and merges duplicates from call context, moving field-completeness %.
Lead enrichment builds account dossiers before outreach, moving qualified-lead conversion %.
The trap is buying capability without a target. An agent that vaguely "helps with forecasting" is unaccountable, but one that moves accuracy from 72% to 90% is a budget line.
Our named agents map directly to these jobs, from the CRM Manager to the Retention Forecaster. To see how this stacks against legacy stacks, compare our take on the best AI sales tools and where action beats dashboards.
Why is data quality the make-or-break prerequisite for AI in revenue operations?
Agentic AI is only as good as the data it acts on. Salesforce has reported that the overwhelming majority of CRM records are incomplete or inaccurate, with some studies near 90%. With a dashboard, bad data merely misleads a human. With an agent, bad data gets acted on automatically and at scale.
Before letting agents touch anything, we recommend a quick readiness check.
Field completeness: Do open deals have amount, close date, and next step filled?
Source coverage: Are calls, emails, and Slack connected, or is the CRM your only thin signal?
De-duplication: How many duplicate accounts are splitting your data?
Recency: When was each opportunity genuinely last touched?
Here is our contrarian take. The standard advice says "clean your data, then deploy AI," but that gets sequencing backwards for hygiene agents. A manual clean can take years, while a hygiene agent cleans as it works. We bootstrap clean data through the agent, an approach we expand on in our overview of revenue intelligence platforms.
How do we roll out AI for revenue operations safely with a human-in-the-loop framework?
We treat agent autonomy like onboarding a new hire. You do not hand a week-one rep your biggest renewal, you earn trust in stages along a three-tier ladder.
Suggest: the agent recommends, a human acts. Lowest risk, fastest to trust.
Approve: the agent drafts the action, a human one-clicks to confirm.
Automate: the agent executes low-risk tasks alone, like merging obvious duplicates.
Sequencing matters more than tooling. We automate CRM hygiene, call logging, and enrichment early because they are high-volume and low-blast-radius. We keep outbound emails and forecast-category changes at approve, and we keep the actual sales conversation, pricing, and exec relationships fully human.
A governance checkpoint helps at each promotion: track the agent's acceptance rate before moving it up a tier. Our agents nudge reps to validate data before pushing updates, which is approve graduating to automate as confidence builds. For setup expectations, our Gong implementation timeline breakdown is a useful reference point.
How do we evaluate AI revenue operations vendors against criteria like forecast accuracy and agentic execution?
We score every vendor on four axes that actually predict revenue impact, rather than counting features.
Forecast-accuracy lift: does it tighten the number, or just visualize the same shaky one?
Conversation-intelligence depth: does it read calls, emails, and tickets, or only record calls?
Agentic execution: does it take action, or stop at a report?
CRM-native fit: does it sync both ways without locking your data in?
The trap is buying a strong tool on the wrong axis. A forecast-led team should not over-index on what is, at its core, a call recorder. Operators flag this in reviews, calling some leaders a "glorified SFDC overlay" or noting unclear pricing and low adoption.
Where we score well is the agentic-execution column most others leave empty, plus a full open-export policy so your data is never hostage. For a direct head-to-head using this same matrix, see our Gong vs Oliv comparison.
Which teams benefit most from AI for revenue operations, and how do we measure success over time?
Lean, scaling SaaS teams gain the most. A 200-person enterprise can throw five analysts at dirty data, but a 30-rep scale-up cannot, so an agent becomes the RevOps hire they will not make. High-velocity B2B teams, fast-scaling startups, and renewal-heavy subscription businesses all see outsized returns. Pure B2C support automation or basic call-recording use cases are not the right fit.
Measurement is the control loop, not a one-time ROI check. We track two layers.
Outcome KPIs: forecast accuracy, gross revenue retention, and field completeness.
Agent-health KPIs: action-acceptance rate and override frequency, your early-warning signals.
Govern with monthly acceptance reviews, quarterly accuracy audits, and one named owner per agent. Each clean audit earns you the right to expand autonomy with evidence, not hope. We dig into where this is heading in our guide to the best revenue orchestration platform tools.
Enjoyed the read? Join our founder for a quick 7-minute chat — no pitch, just a real conversation on how we’re rethinking RevOps with AI.
Revenue teams love Oliv
Here’s why:
All your deal data unified (from 30+ tools and tabs).
Insights are delivered to you directly, no digging.
AI agents automate tasks for you.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Meet Oliv’s AI Agents
Hi! I’m, Deal Driver
I track deals, flag risks, send weekly pipeline updates and give sales managers full visibility into deal progress
Hi! I’m, CRM Manager
I maintain CRM hygiene by updating core, custom and qualification fields, all without your team lifting a finger
Hi! I’m, Forecaster
I build accurate forecasts based on real deal movement and tell you which deals to pull in to hit your number
Hi! I’m, Coach
I believe performance fuels revenue. I spot skill gaps, score calls and build coaching plans to help every rep level up
Hi! I’m, Prospector
I dig into target accounts to surface the right contacts, tailor and time outreach so you always strike when it counts
Hi! I’m, Pipeline tracker
I call reps to get deal updates, and deliver a real-time, CRM-synced roll-up view of deal progress
Hi! I’m, Analyst
I answer complex pipeline questions, uncover deal patterns, and build reports that guide strategic decisions

.avif)
.png)








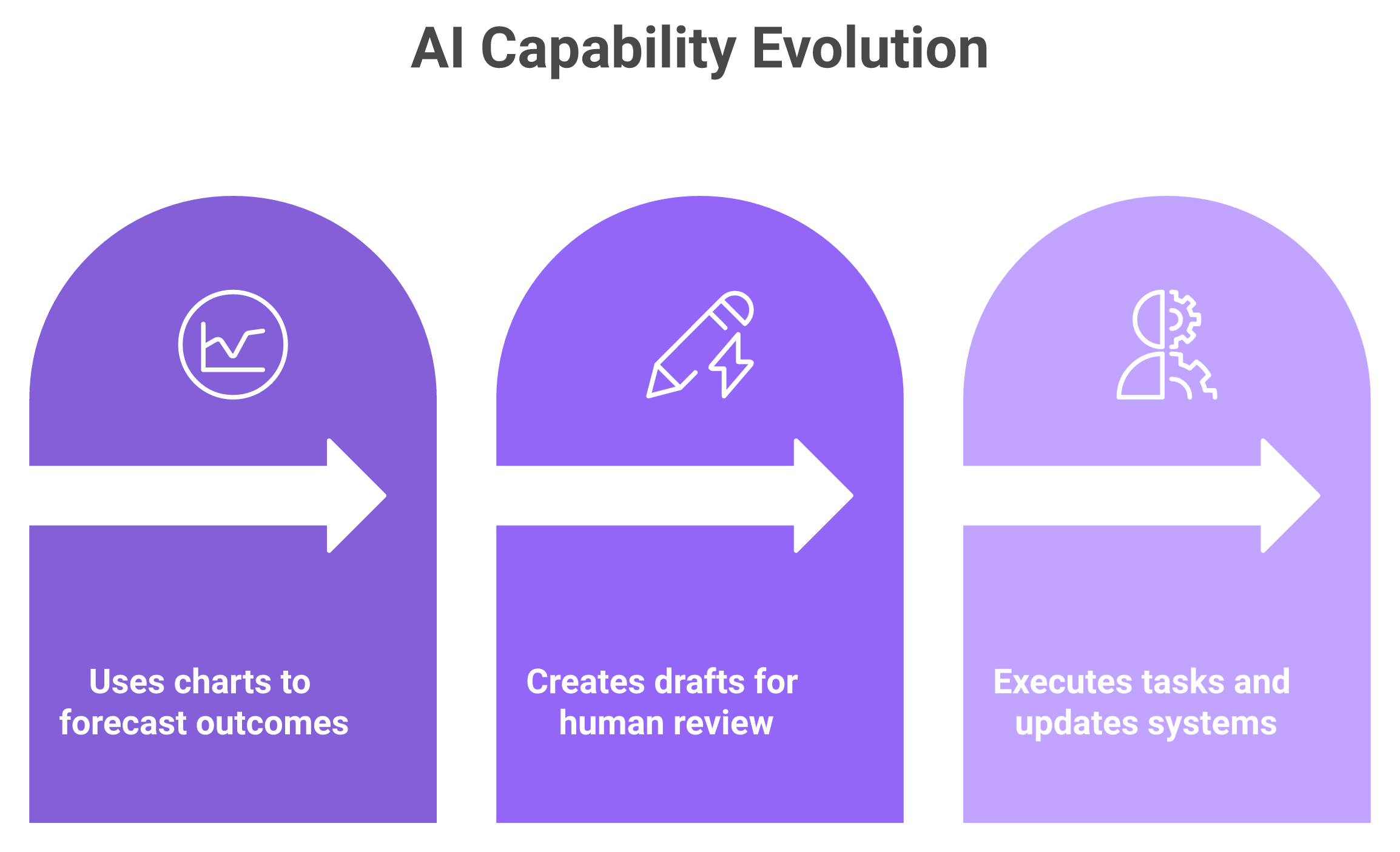
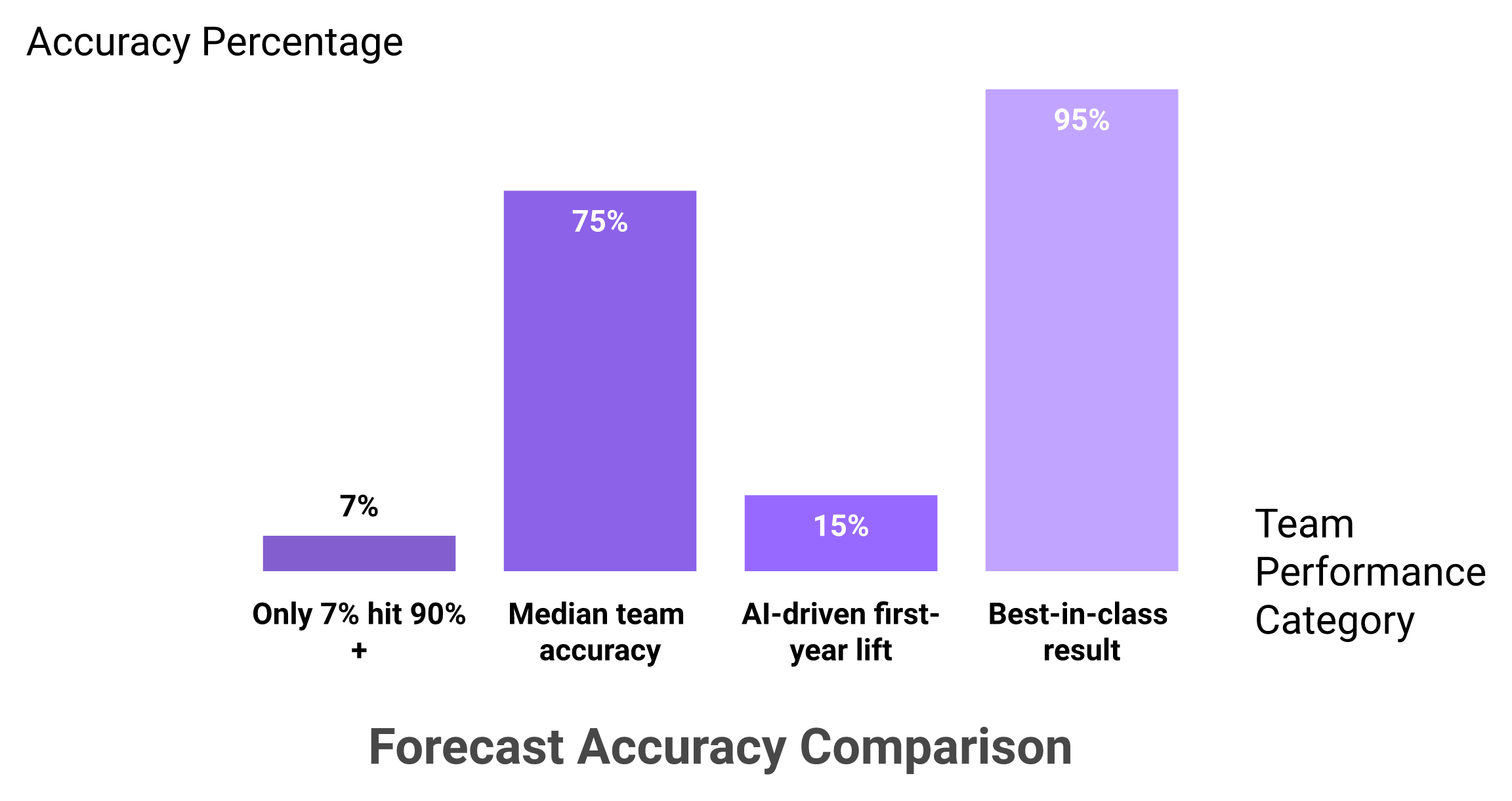
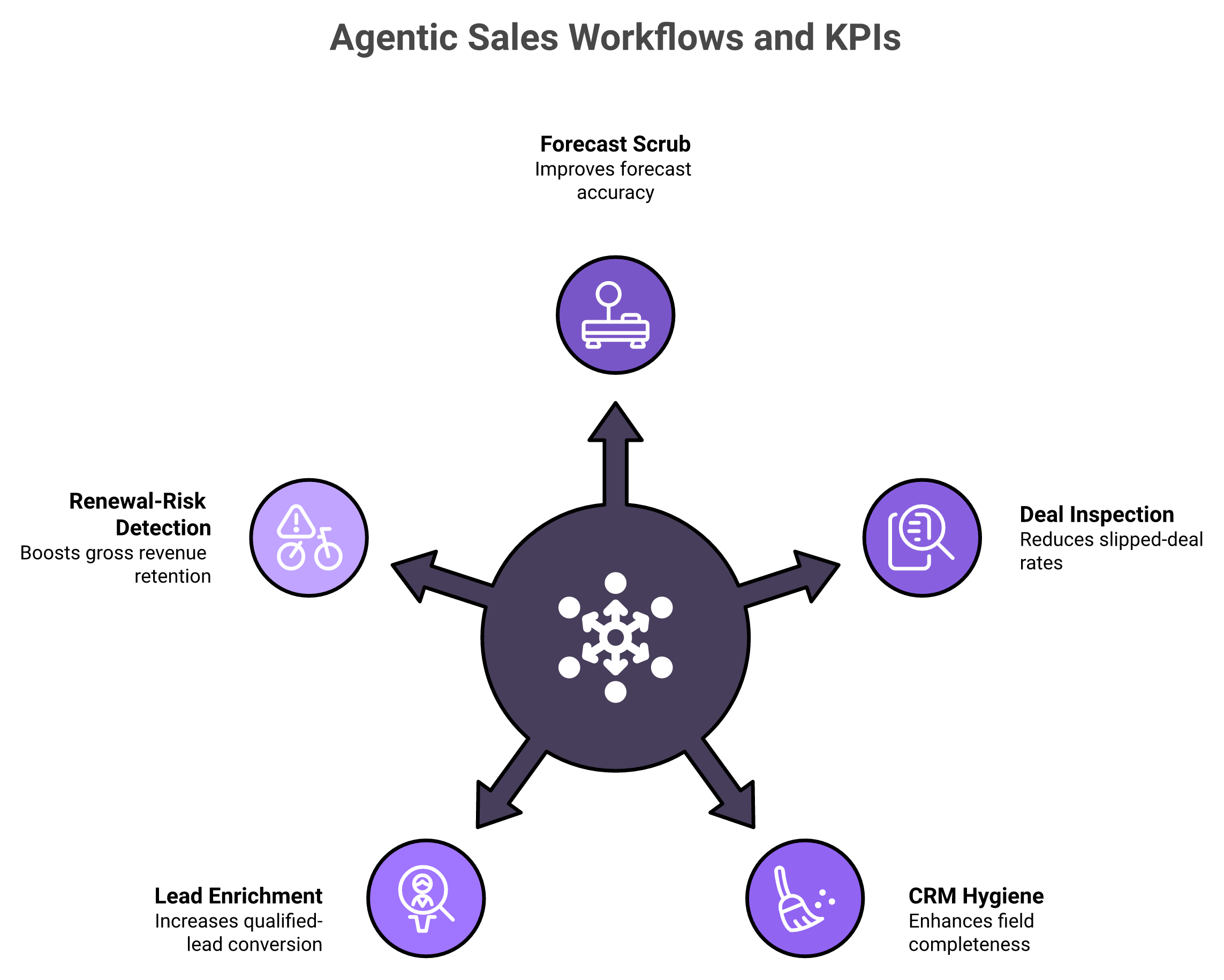
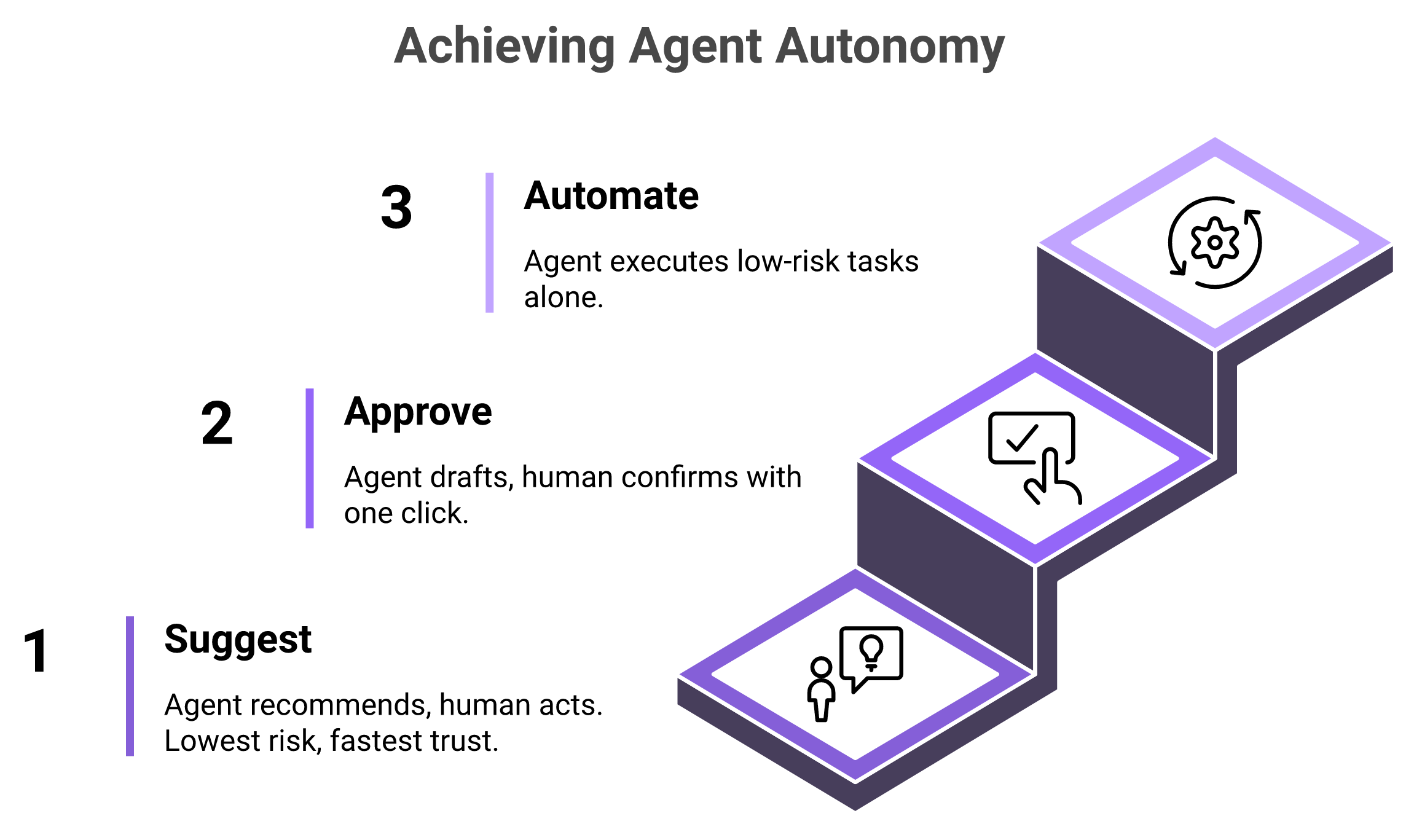

.png)
.png)
.png)

